
作者 | 薛寒钰
策划 | 蔡芳芳
在大多数的业务系统的构建和开发之中,日志作为系统运行背后的产出,描述着我们系统的行为和状态,是开发和运维人员对系统进行观察和分析的基石。在系统状态比较微小和原始的状态下,日志可能仅仅是为了打桩和调试而存在的,或独立、或单一的记录,但随着我们系统不断的复杂化、模块化,服务与服务之间的配合不断的密切化、分布化,我们对于日志描述的精准化、规范化、可观察化的需求就愈发凸显。本文是《微服务中台技术解析》系列文章第七篇,将简要介绍 FreeWheel 核心业务系统团队经过多年的思考、开发、迭代之后形成的日志系统实践。
早期 FreeWheel 的核心业务系统是基于 Ruby on Rails 的单体式应用。Ruby on Rails 提供的精炼、快速的语言风格和构建方式,为 FreeWheel 核心业务系统早期的开发和扩展提供了非常强大的支撑。但随着 FreeWheel 的业务需求和服务场景不断的扩大,传统的单体式应用已经不足以满足我们日益增长的高速开发迭代的需求。
于是,在 2016 年,FreeWheel 核心业务系统团队破釜沉舟的开启了拥抱 Golang 的技术栈更迭。在这个过程中,我们的日志系统也由依赖 Ruby on Rails 提供的日志结构向基于 Golang 的新方式发生了演进。同时,随着架构由 SOA 到微服务再到云原生的不断进步和迭代,我们不断探索着适合于我们当前业务系统的日志解决方案,并将当下 FreeWheel 核心业务的日志系统最佳实践简要汇聚成下文。
调试日志是日志中最为常见和基础日志类型,通常由开发者在代码逻辑中植入日志记录的代码,来对系统正在或已经发生的行为和状态进行记录。为了能够提供良好的阅读性和可维护性,我们首先制定了初步的日志规范:
-
在日志标记上,要记录打印日志的时间,来方便查阅和追溯什么时刻发生了什么,以及相关的先后顺序。
-
在日志分类上,要说明当前的日志级别(Debug、Info、Warn、Error、Fatal、Panic,其中 Panic 非极特殊情况不推荐使用)。
-
在日志内容上,不能简单的打印变量或结构体,要添加基本的描述和相关辅助信息,来说明和指导当前日志内容的用途和意义,拒绝因没有意义的日志而浪费人力、物力资源。
通过上述规范,我们能够得到一个能够对日志按照时间和级别进行归类,但这还是远远不够的。为了将日志结构更加便于收集、解析、整理、分析,我们编写了一套名为 Bricks Log 的日志工具库。该日志库在满足了以上三点要求的基础上,实现了:
-
可动态配置和调整时间输出格式,默认为 RFC3339。
-
可动态配置和调整日志在当前系统中的输出级别,默认为 Info。
-
可动态配置和调整日志的输出格式(当前支持 Text 或 JSON),默认为 JSON。
-
在系统接入 Tracing 后从 Context 中提取打印 Tracing 信息,便于相关日志间查询参考。
-
可添加自定义 Key-Value 日志内容,方便对日志内容描述进行自定义扩展。
-
记录日志内容的大小,方便统计和审视日志的规模和合理性。
例如我们可以通过如下方式进行调用使用
// 日志打印样例func logExample() {// 初始化 Tracing,将 Tracing 信息注入到 Context 中tracing.InitDefaultTracer("example")sp := tracing.StartSpan("example_span")sp.Finish()ctx := opentracing.ContextWithSpan(context.Background(), sp)// 可配置日志输出格式和时间格式,默认为 JSON 和 RFC3339log.ConfigFormat(log.JSONFormat, time.RFC3339)// 可配置日志输出级别,低于该级别的日志不进行输出,默认为 Infolog.SetLevel(log.DebugLevel)// 可自定义增添日志输出的 Key-Value 内容fields := map[string]interface{}{"test_key": "test_value",}// 打印输出级别为 Error 并携带 Context 中 Tracing 信息以及自定义 Key-Value 内容的简单文本log.WithCtxFieldsError(ctx, fields, "test message: log example.")}
对应输出的日志如下:
// log.WithCtxFieldsError(ctx, fields, "test message: log example."){"level":"error","msg":"test message: log example.","parent_id":"0","size":26,"span_id":"719a1b2fe311510a","test_key":"test_value","time":"2020-11-11T11:11:11Z","trace_id":"719a1b2fe311510a","type":"debug"}
可以看到,日志按照设定的内容和格式预期的输出了我们要打印的内容。其中:
-
level:日志输出级别
-
time:日志输出时间
-
msg:日志内容
-
size:日志内容大小
-
type:标记该日志为调试日志,用于后期收集时对不同日志类型进行处理
-
test_key,test_value:自定义 Key-Value
-
trace_id,span_id,parent_id:Context 中携带的 Tracing 信息
在实践中我们发现,单纯的打点式记录代码逻辑过程中的内容,已经不足以满足核心业务系统团队构建的应用服务场景。对于面向客户操作的业务系统,输入输出是整个系统的重中之重。尤其是在微服务化后,服务接收到的请求和返回给调用方的内容,对于我们查看和监控系统的状态、以及分析用户和系统行为十分必要。
为了解决这一问题,我们提出了一种记录 Request Log 的拦截器式中间件。该中间件包裹在服务请求或事件生命周期的开始和结束,从请求发生的上下文中提取请求地址、请求内容、返回内容、错误列表、处理函数、客户 ID、时间戳、时长等信息,并以 JSON 的形式打印出来。同时,该中间件不单单记录了本服务的输入输出,也支持记录从本服务向其他服务,特别是非核心业务系统内部的服务(如 ElasticSearch、DynamoDB)的输入输出,来帮助我们更好的观测和发现服务中发生的行为和问题。
基于该中间件的良好结构,我们支持 HTTP 和 gRPC 两种协议下的服务,也同时兼容 Job 和 Message 类型的服务,方便我们统一化收录和解读,降低不同服务之间日志的阅读和维护成本。
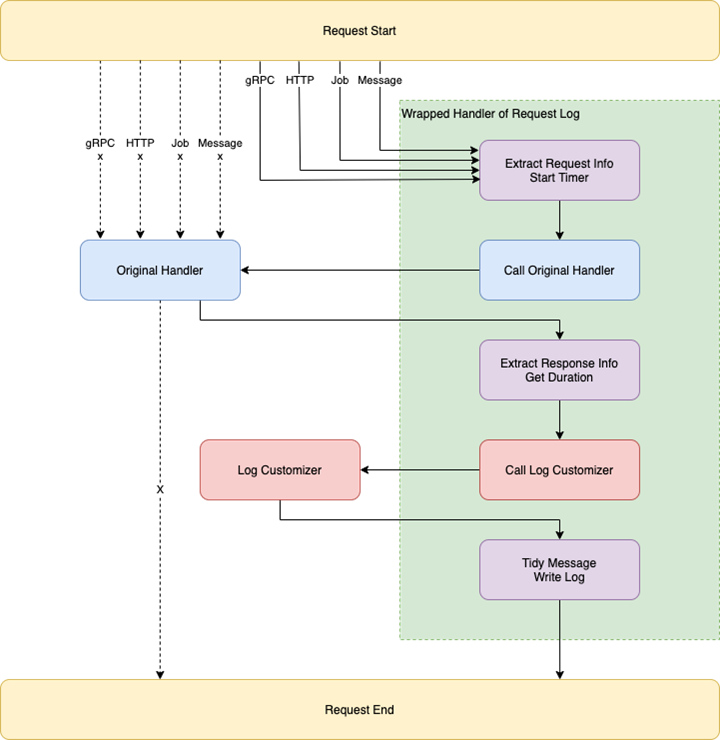
请求日志的实现结构如上图所示,通过该结构实现了:
-
记录 Request Body、Reply Body,产生的 Error Code、Message、Body、Stack Trace,被调用的 Method 及对应的 Context,请求或事件的开始时间和持续时间,请求发起的客户 ID 等
-
增加可定制化的记录单元,并通过传入的定制函数来处理定制化内容
-
支持同时作为 HTTP 和 gRPC 的 Server 和 Client 来记录接到的发出的请求日志信息
-
支持非即时请求式的 Job 和 Message 的信息记录
-
支持 Tracing 来记录调用链信息
生成的请求日志直接调用调试日志,将转译后的信息放置在 msg 中,并将 type 字段置为 request 来与其他日志进行区分。样例如下所示:
{"level": "info","msg": "{\"TraceID\":\"7ec0301254a9af75\",\"IsOutgoing\":false,\"NetworkID\":12…","size": 1517,"time": "2020-11-11T11:11:11Z","type": "request"}
通过以上功能,记录 Request Log 的中间件覆盖了核心业务系统当前所有业务场景下对请求日志功能的需求,并提供了足够的扩展能力。为新服务的构建以及不同服务之间问题的排查,提供了良好的中台基础。
具有了优秀的中间件来输出标准规范的日志,我们同样需要一套优雅的日志收集系统来将我们的日志更好的归类,以便进一步的观察、分析、监控。为此,FreeWheel 核心业务系统团队选择了 ELK Stack 来对我们系统产生的日志进行收集。
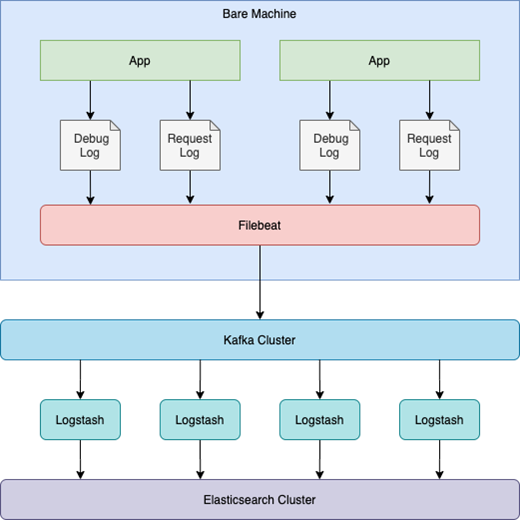
在单体应用和物理机时期,我们通过在物理机上部署 Filebeat 将应用产生的不同日志按行进行收集、加入分类信息以及封装,并作为 Producer 将封装好的消息传递给消息队列 Kafka。之后 Logstash 作为 Consumer 从 Kafka 处获得日志消息,并对其进行分类、清洗、解析、二次加工后传递给 Elasticsearch 进行存储。而后即可通过 Kibana 对系统产生的日志进行查看,并在此基础上构建 Dashboard 来对日志信息进一步可视化。
随着服务的容器化,服务之间的运行环境相对独立,也不再受物理机的制约,于是我们便初步尝试将 Filebeat 以 Sidecar 的形式整合在了服务的 Pod 中。
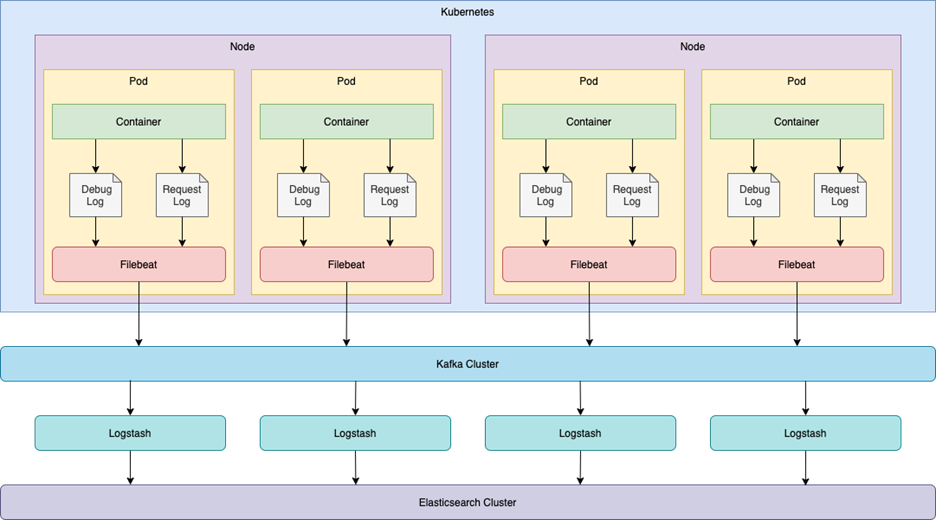
如上图所示,Filebeat 作为 Sidecar 在 Pod 中采集对应路径下的日志文件,进而发送到 Kafka。这种方案的 Filebeat 配置与物理机时期非常相近,作为过渡方案改动相对较小。但是 Sidecar 运行时的资源消耗会对整个 Pod 造成影响,进而影响服务的性能。我们曾经遇到过,由于短时高发的日志输出,导致整个 Pod 的内存资源消耗严重,业务服务不能继续提供服务,进而 Pod 自动重启的情况。因此,我们在此基础上,提出了采用 DaemonSet 的方案。
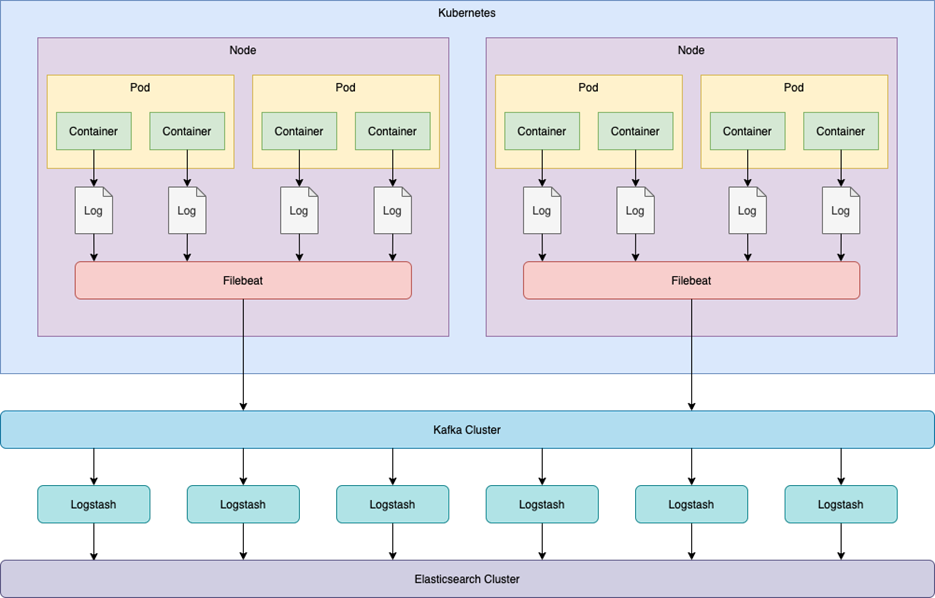
如上图所示,我们将在 Container 中的应用打印在 Console 中的 Log(调试日志、请求日志、第三方日志)重定向到 Node 的固定位置,之后令 Node 中的 Filebeat 对日志所在的路径进行监控采集。这种方案能够有效的将 Filebeat 的运行与应用的 Container 和 Pod 分割开来,规避了在 Pod 中使用 Sidecar 对应用所带来的资源损耗。
而后,Filebeat 会把采集到的日志进行初步处理,增添 Host 等信息并封装后,传递给对应的 Kafka Cluster 的 Topic 里面。Logstash 将作为 Kafka Cluster 的消费者,监听注册的 Topic 中的消息,当接收到新的消息时,会根据日志消息中的 type 类型来区分是调试日志、请求日志还是第三方日志,并按照不同的类型来进行解析处理。
得益于 Kubernetes 会将 Container 的信息写入 Console 的 Log 中,我们在此可以根据 Container 的 Name 将日志分类到不同的 Elasticsearch Index 里面(当下,我们将第三方日志与调试日志合并在同一个 Elasticsearch Index 之中,方便日志查询),其形式如:
fw-ui-%{kubernetes container name}-%{log type}-log-%{+YYYY.ww}最后 Logstash 会将处理好的日志信息与其对应的 Elasticsearch Index 发送给 Elasticsearch Cluster 进行存储。
得益于调试日志和请求日志的广泛使用,日志的格式和主体的统一,让我们有能力将 Logstash 的配置统一化。同时,因为我们使用了上面的匹配方式,新的服务可以完全透明的使用 ELK Stack,不必再进行任何 ELK Stack 配置的修改,即可将应用产生的日志写入 Elasticsearch 中。这为我们日益增长的各种微服务的构建,提供了极大的便利条件,降低了各个服务的维护和配置成本。
当我们能够以非常优雅的方式将线上系统的实时日志信息收集之后,即可在丰富日志的基础上,构建更加便利的可视化图表来展现系统服务的特性与状态;同时也可以制定相应的报警机制,对非预期的客户或系统行为状态进行实时告警。
基于 ELK Stack 中的 Kibana,我们不仅能够通过其 Discover 模块对日志进行有效的搜索和查看,我们还可以基于其 Visualize、Dashboard 等模块,对日志数据进行多种维度的分析和可视化,将业务系统中的行为和状态清晰而直观的展示。
我们可以通过 Visualize 统计某一模块的吞吐量、响应时长进而反映出系统的工作状态和性能。同时还可以按照更细的维度来划分,比如按照访问方法、客户 ID 等来对不同客户对不同方法的访问频度、服务效能、业务功能依赖性等方面进行分析。
更重要的,我们可以实时展示日志中所产生的错误情况,并根据其错误码进行归类划分,反映系统中已发生和正在发生的问题,甚至通过错误日志产生的场景分析客户的使用方式和行为,进一步对系统的设计进行优化,增强用户体验。我们还可以将上述构建的 Visualize 模块统一到某个 Dashboard 之中,并周期性的一同审阅系统前一日或几日的状态的行为,将我们精心构建的系统了然于心。
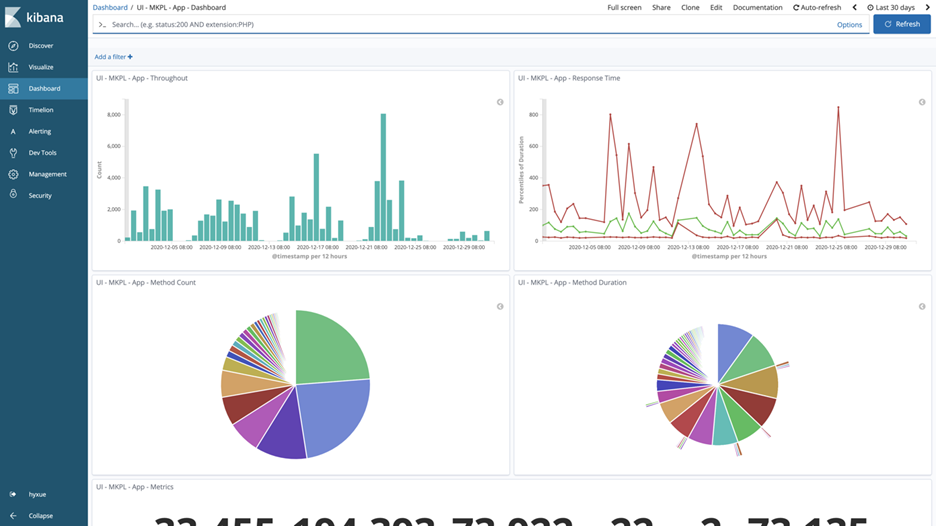
在采用了调试日志和请求日志后,不同服务的日志结构近乎相同。我们可以很方便的根据已有服务的 Dashboard 来创建自己新服务的 Dashboard。在基础的 Visualize 不会被遗失的保障下,还可以针对新服务的特性创建更多个性化的定制视图,为我们的日常开发和维护提供极大的便利,降低了因日志的格式形态不同而导致的学习、构建、维护成本。
Kibana 的使用让我们更加便利的对系统日志进行图形化分析和查看,但仅依靠人来对系统进行观测并不能在第一时间发现系统的问题并进行调整,于是我们引入了 ElastAlert。
ElastAlert 是一个基于 Python 编写的简单易懂的报警框架,通过编写其 YAML 格式的配置文件,可以实现对 Elasticsearch 中日志的异常、峰谷值或其他关键数据进行监控和报警。
在没有完整的日志收集和监控系统之前,系统的报警通常是由系统的业务逻辑代码直接判断和发送的。这种方式,往往将报警逻辑和业务逻辑紧耦合,不仅消耗了原本为业务服务的时间和资源,引入和更高的维护和依赖成本,还造成了报警仅能就当前单一请求或状态进行判断,不能统观全局。这种由系统直接发送的大量无效和冗余报警,对业务系统、报警通知系统都是一个严重的负担,同时也会导致我们花费更大的时间和精力报警的处理上,更有甚者会将其中某些有效的报警淹没在无效报警的洪流之中,造成重要的问题被忽视和遗忘。
在拥抱 ELK Stack 之后,我们可以通过我们的日志系统,将报警和业务彻底结偶,同时也让报警具备了统筹一段时间内日志行为和缓冲短时高发错误日志的能力,将迎面而来的扫荡式报警轰炸,优化为更加精确具体的点对点攻击。
除此之外,我们还要求团队在编写报警规则时,规范化报警的格式和内容,便于对应的值班同学能够在第一时间发现问题的所在,并采取最准确的行动。我们要求报警邮件的标题必须要以特定的格式包含以下内容,以便通过标题能够快速的分类和定位到报警:
[<报警级别>][<线上环境>][<负责团队>][<服务节点>] <报警名称> @<时间戳> [ElastAlert]比如:[WARN][PRD][UI][test-asdfqwerzxcv] More Than 100 422s in 1s @2020-11-11T11:11:11Z [ElastAlert]
其中的部分内容是可以通过命中的问题日志获取的,比如服务节点等。还有部分内容是由人工根据实际情况指定的,比如报警级别。我们要求大家把报警根据危险程度分为:
-
WARN,可能会引起某个问题,需要稍后进行分析确认,但不紧急;
-
FAIL,程序异常行为,需要查看当前异常是否对客户造成错误影响,是否阻碍了客户的正常行为,是否有脏数据产生等,必要时联系该服务的负责人进行处理;
-
CRIT,严重异常,需要立即通知该服务的负责人进行立即止血和修复。
关于具体的报警邮件里面的内容,相关的同学可以根据实际情况进行定制,但是一定要满足以下几个基本要求:
-
明确值班同学看到当前报警的行为
-
明确对应报警的负责同学是谁
-
明确可以参考的日志的 Kibana 链接
-
明确对应报警日志的 Tracing 链接
遵循以上内容和格式的规范,我们可以更加明确的定位到发生的问题,以及对应需要处理问题的方法,提高问题处理的效率,降低监控报警的人力物力成本。写在最后在未来,我们将不断对日志系统进行优化,来满足我们日新月异的业务需求和技术迭代,包括但不限于:
-
异步化日志记录,为高吞吐量、高性能需求的应用提供异步的日志读写,降低 IO 对业务性能的影响。
-
思考如何有效且优雅的记录基于流和 WebSocket 通讯的数据传输内容的日志记录。
-
非服务型应用的请求日志接入。
经过 FreeWheel 核心业务系统的同学们多年的探索和努力,形成了一套从日志编写、生成到收集、监控、报警的完整生命周期,每一个部分都有机的组合在一起,总结成了上文中的方案,希望对读到这里的你能有些许启发和帮助。
点击文末【阅读原文】移步InfoQ官网,内容更多更精彩!
InfoQ 写作平台欢迎所有热爱技术、热爱创作、热爱分享的内容创作者入驻!
还有更多超值活动等你来!
扫描下方二维码
填写申请,成为作者


点个在看少个 bug ?

文章评论