点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读
基于IoU的NMS实际上是一种贪心算法,这种方法得到的结果往往不是最优的,Confluence给出了另一种选择。
论文地址:https://arxiv.org/abs/2012.00257
摘要:文章提出另一种NMS的替代的方法,这种方法不是只依赖单个框的得分,也不依赖IoU去除冗余的框,它使用曼哈顿距离,在一个cluster中选取和其他框都是距离最近的那个框,然后去除那些附近的高重合的框。
1. 介绍
在当前的主流的物体检测中,NMS都是很必要的,如下图1,NMS其实是一种贪心算法,每次取一个得分最高的框,然后抑制掉其他和这个框重叠过多框,所以NMS的结果并不是最优的,因此,出现了很多对NMS的改进,比如soft NMS,或者替代的方法,有些依赖于聚类,有些依赖空间上的共现关系,有些使用霍夫变换,还有些基于端到端的训练的方法。

2. 方法
文章提出的方法叫做:Confluence,这个方法的主要思路并不是要把大量的检测结果抑制掉,而是想办法从中识别出最优的框,这是通过识别出和其他的框交汇最多的那个框来实现的。Confluence是一个2阶段的方法,可以保留最佳的框,抑制掉假阳框,通过曼哈顿距离来度量框之间的相关性,然后通过置信度加权,得到最优的那个框,然后再通过和这个框的交汇程度来去掉其他的假阳框。
2.1 曼哈顿距离
曼哈顿距离就是L1范数,就是所有点的水平和垂直距离的和,两点之间的曼哈顿距离表示如下:
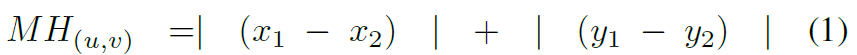
两个框之间的接近程度可以表示为左上角点和右下角点的曼哈顿距离的和:
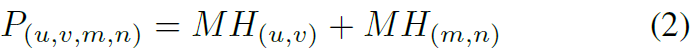
P越小表示交汇程度越高,P越大表示这两个框越不可能表示同一个物体。对于一个cluster内的框,我们把具有最小簇内的P值的框作为最佳的检测框。从图1中可以看到,Confluence具有更好的鲁棒性。
2.2 归一化
在实际使用中,由于框的尺寸不一,所以在用阈值来去除FP的时候,会对这个超参数阈值很敏感,所以需要对框进行归一化,归一化方法如下:
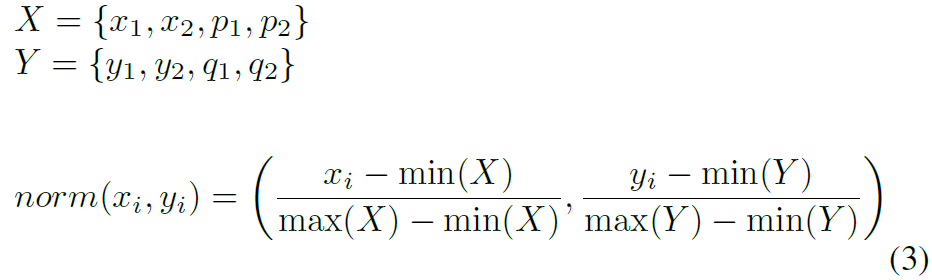
归一化之后,使得簇内的框和簇外的框可以分的很开。
2.3 保留簇内的最优框以及去除冗余框
所有的坐标归一化到0~1之后,两个有相交的框之间的接近度量会小于2,因此,只要两个框之间的P值小于2,就属于同一个cluster,一旦cluster确定了之后,就可以找到最优的簇内框。然后,设置一个阈值,所有和这个最优框的接近度小于这个阈值的框都会去掉,然后对所有的框重复这个操作。
2.4 置信度得分加权
NMS只考虑物体的置信度得分,而Confluence会同时考虑物体的置信度得分c和p值,然后得到一个加权的接近度:
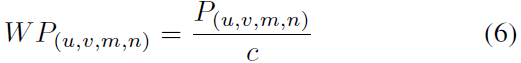
2.5 实现步骤
算法流程如下:

1、对所有的类别进行遍历。
2、得到对应类别的所有的检测框。
3、计算对应类别的所有检测框的两两接近度p,计算的时候使用坐标的归一化。
4、遍历对应类别中的每一个检测框,对每个检测框,把p值小于2的归到一个簇里面,并计算对应的置信度加权接近度。
5、找到一个簇里面具有最小加权p值(最优)的那个框,找到之后,保存这个框,并且将其从总的框列表里删除。
6、对于其他的所有的框,其接近度小于预设阈值的全部去除。
7、循环处理所有的框。
每个步骤的计算复杂度都为O(N),总的Confluence的复杂度为。
3. 结果
在不同的方法上的效果:
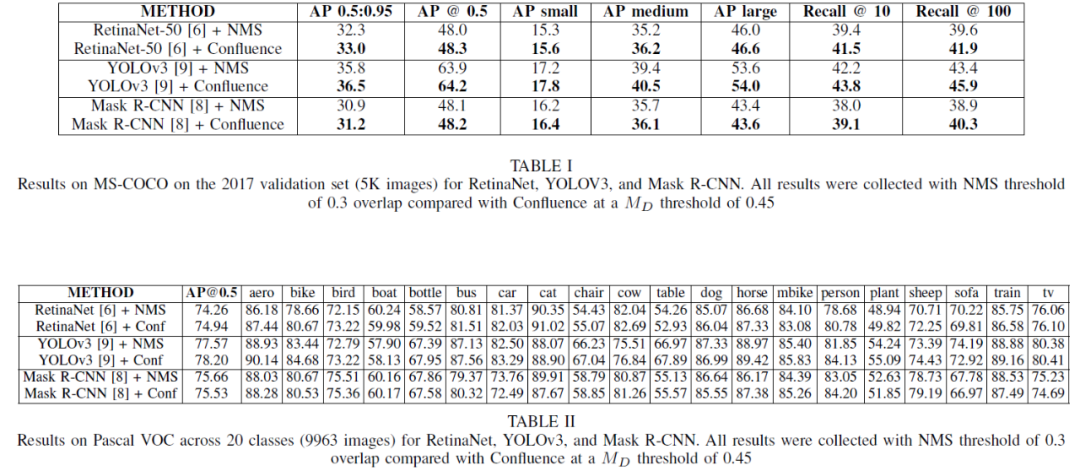
总的来说,还是有效果的,特别是对recall的提升效果更好一点,可以保留之前NMS由于IoU过大而过滤掉的一些TP。
下面是一些具体的例子:

右边黄框的人由于在使用NMS的时候,由于IoU和红色的框过大而被抑制掉了。

左边的Confluence给出的黄色框为最优框,右边NMS的给出的黄色框为次优框,因为最优框和其他的置信度更高的框的IoU太大,被抑制了。
还有一些例子如下:
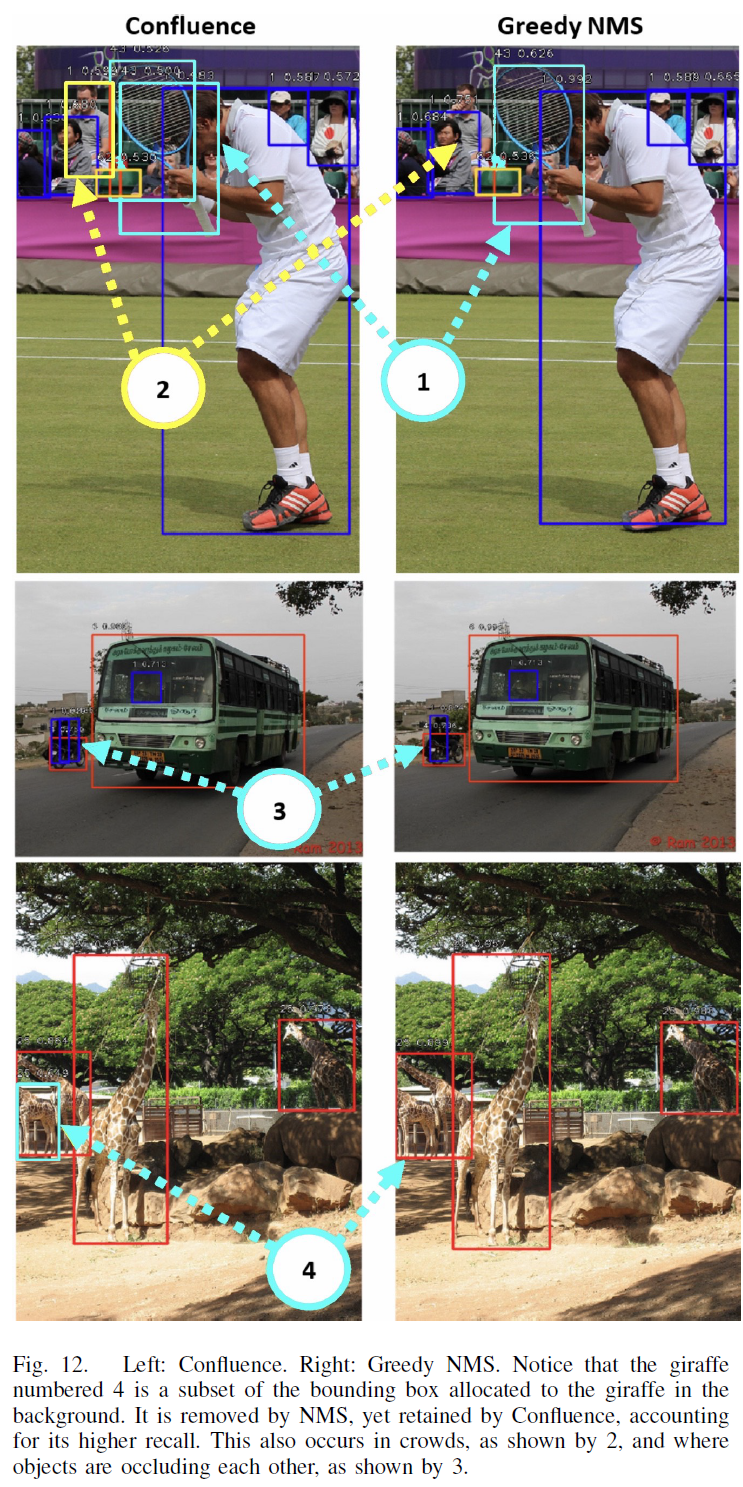
总的来说,这个一个有效的方法,但是从COCO和VOC上的效果来说,虽然有效,但是提升不大。不过,这也和数据集有关,从这个方法的原理来看,最大的好处是可以保留一些原本使用NMS的时候被IoU抑制掉的TP,这在比较拥挤的检测场景中,可能会有更加明显的效果。

论文链接:https://arxiv.org/abs/2012.00257

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!![]()

文章评论