【导语】:AutoScraper是一个智能、自动、快速和轻量级的Web爬虫,使用简单便捷,让你从此告别爬虫手动解析网页和写规则的烦恼。
简介
AutoScraper 是使用 Python 实现的 Web 爬虫,兼容 Python 3,能快速且智能获取指定网站上的数据,这些数据可以是网页文本、URL 地址或者是其它 HTML 元素。另外,它还可以学习抓取规则并返回类似的元素。
下载安装
项目的源码地址是:
https://github.com/alirezamika/autoscraper
兼容 Python 3。可使用以下方法进行安装:
(1)从git获取安装
$ pip install git+https://github.com/alirezamika/autoscraper.git(2)从PyPI获取安装
pip install autoscraper(3)下载源码后进行安装
python setup.py install简单使用
假设我们想在stackoverflow页面中获取所有相关的文章标题:
from autoscraper import AutoScraperurl = 'https://stackoverflow.com/questions/2081586/web-scraping-with-python'wanted_list = ["How to call an external command?"]scraper = AutoScraper()result = scraper.build(url, wanted_list)print(result)
输出结果如下:
['How do I merge two dictionaries in a single expression in Python (taking union of dictionaries)?','How to call an external command?','What are metaclasses in Python?','Does Python have a ternary conditional operator?','How do you remove duplicates from a list whilst preserving order?','Convert bytes to a string','How to get line count of a large file cheaply in Python?',"Does Python have a string 'contains' substring method?",'Why is “1000000000000000 in range(1000000000000001)” so fast in Python 3?']
抓取相似结果
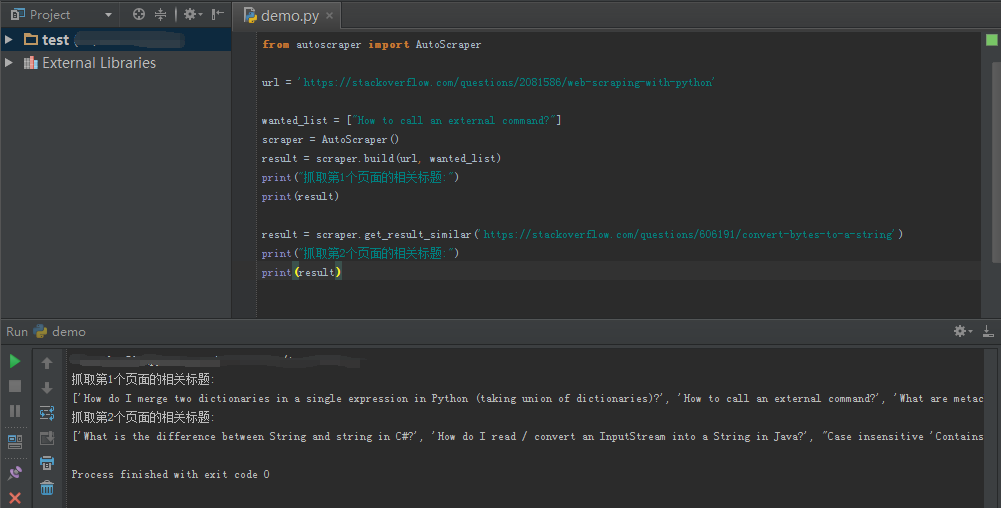
当你还想获取stackoverflow上其他页面中所有相关的文章标题,则可以直接通过get_result_similar方法获取:
scraper.get_result_similar('https://stackoverflow.com/questions/606191/convert-bytes-to-a-string')两个页面的抓取结果为:
抓取确切结果
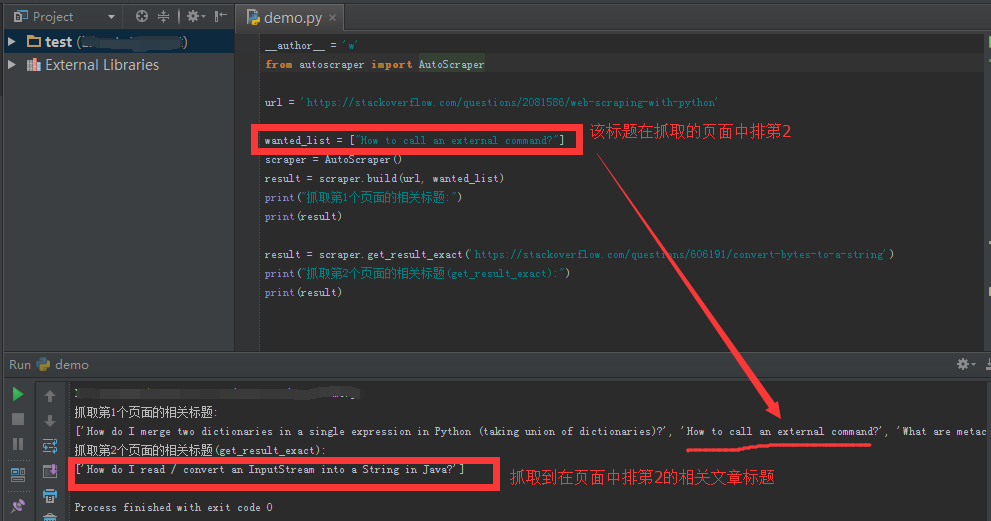
当你只想抓取某个确切的结果,可以使用get_result_exact方法,即从wanted_list中以完全相同的顺序检索数据:
scraper.get_result_exact('https://stackoverflow.com/questions/606191/convert-bytes-to-a-string')比如抓取页面中排第2的相关文章标题,执行结果:
自定义请求模块参数
你还可以传递任何自定义请求模块参数。例如,你可能想使用代理或自定义头:
proxies = {"http": 'http://127.0.0.1:8001',"https": 'https://127.0.0.1:8001',}result = scraper.build(url, wanted_list, request_args=dict(proxies=proxies))
抓取多项信息
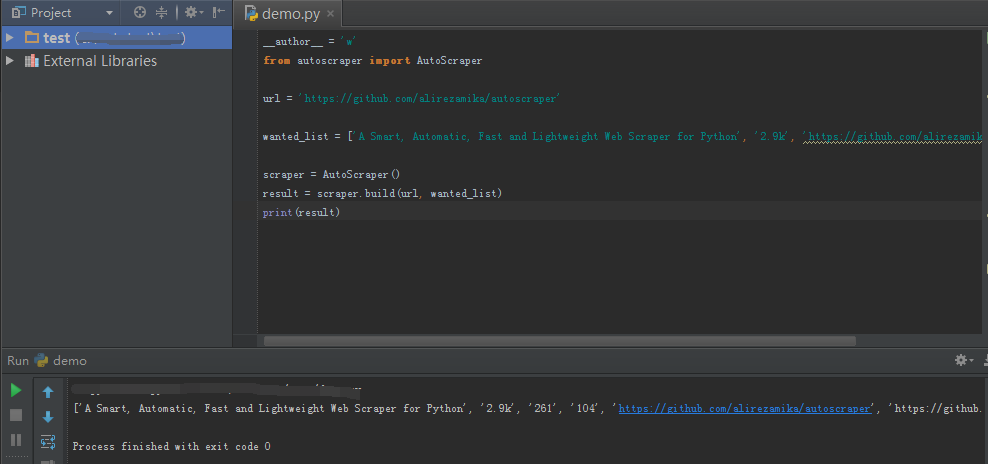
假设我们想要抓取关于文本,Star的数量和Github回购页面的问题链接:
from autoscraper import AutoScraperurl = 'https://github.com/alirezamika/autoscraper'wanted_list = ['A Smart, Automatic, Fast and Lightweight Web Scraper for Python', '2.5k', 'https://github.com/alirezamika/autoscraper/issues']scraper = AutoScraper()scraper.build(url, wanted_list)
执行结果为:
保存模型
我们可以保存抓取的模型以便以后使用:
# 指定保存的文件路径scraper.save('stackoverflow')# 调用方法:scraper.load('stackoverflow')
AutoScraper简单介绍就到这里了,如果你想使用更多的功能,详见官方主页了解。
- EOF -
更多优秀开源项目(点击下方图片可跳转)



如果觉得本文介绍的开源项目不错,欢迎转发推荐给更多人。

分享、点赞和在看
支持我们分享更多优秀开源项目,谢谢!

文章评论