

前两天闹得沸沸扬扬的事件不知道大家有没有听说,Google 竟然将 Docker 踢出了 Kubernetes 的群聊,不带它玩了。
我这里简单描述下,Kubernetes 是通过 CRI 来对接容器运行时的,而 Docker 本身是没有实现 CRI 的,所以 Kubernetes 内置了一个 “为 Docker 提供 CRI 支持” 的 dockershim 组件。现在 Kubernetes 宣布不再维护这个组件了。

Nvidia 驱动
-
安装 gcc 和 kernel-dev(如果没有) sudo apt install gcc kernel-dev -y。
-
访问官网下载。
-
选择操作系统和安装包,并单击【SEARCH】搜寻驱动,选择要下载的驱动版本
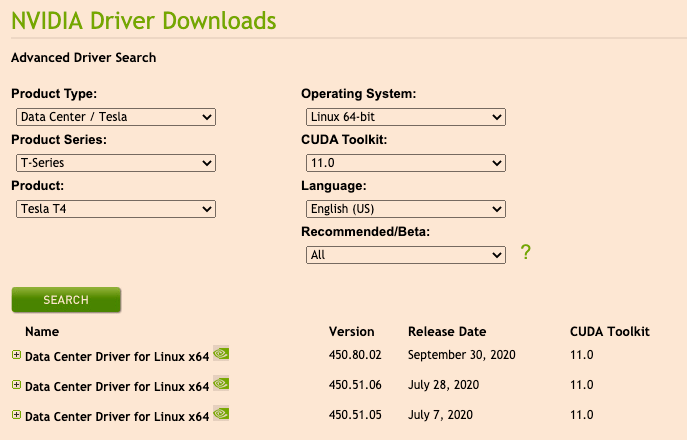
下载对应版本安装脚本,在宿主机上执行:
$ wget https://www.nvidia.com/content/DriverDownload-March2009/confirmation.php?url=/tesla/450.80.02/NVIDIA-Linux-x86_64-450.80.02.run&lang=us&type=Tesla安装,执行脚本安装:
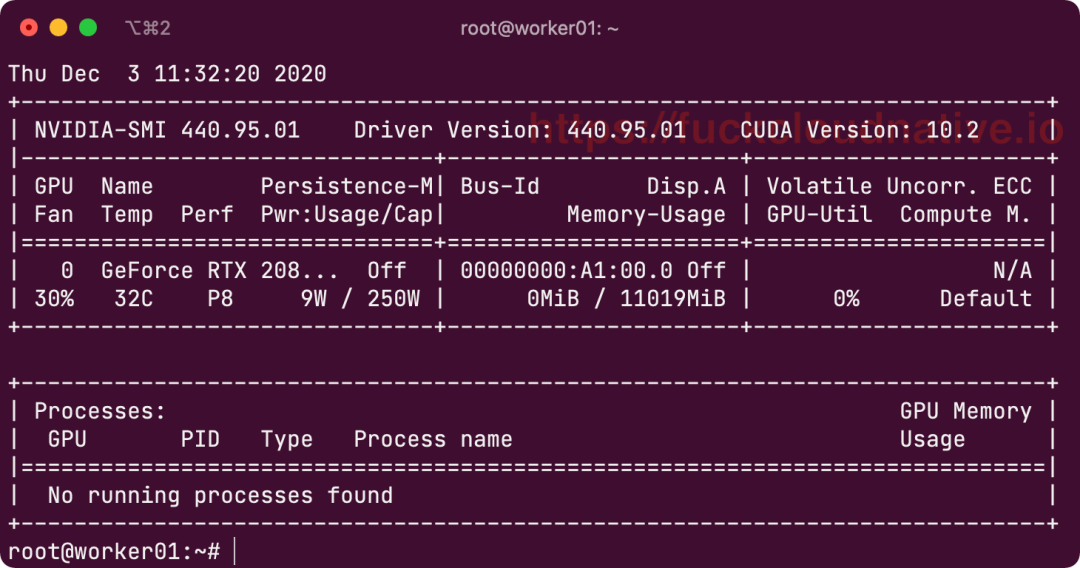
$ chmod +x NVIDIA-Linux-x86_64-450.80.02.run && ./NVIDIA-Linux-x86_64-450.80.02.run验证,使用如下命令验证是否安装成功 nvidia-smi ,如果输出类似下图则驱动安装成功。

-
访问官网下载
-
下载对应版本如下:

$ echo 'export PATH=/usr/local/cuda/bin:$PATH' | sudo tee /etc/profile.d/cuda.sh $ source /etc/profile
nvidia-container-runtime
nvidia-container-runtime 是在 runc 基础上多实现了 nvidia-container-runime-hook(现在叫 nvidia-container-toolkit),该 hook 是在容器启动后(Namespace 已创建完成),容器自定义命令(Entrypoint)启动前执行。 当检测到 NVIDIA_VISIBLE_DEVICES 环境变量时,会调用 libnvidia-container 挂载 GPU Device 和 CUDA Driver。如果没有检测到 NVIDIA_VISIBLE_DEVICES 就会执行默认的 runc。 下面分两步安装: 先设置 repository 和 GPG key:
$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo apt-key add -$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/$(. /etc/os-release;echo $ID$VERSION_ID)/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list安装:
$ apt install nvidia-container-runtime -y配置 Containerd 使用 Nvidia container runtime
如果 /etc/containerd 目录不存在,就先创建它: $ mkdir /etc/containerd生成默认配置: $ containerd config default > /etc/containerd/config.tomlKubernetes 使用设备插件(Device Plugins)[3] 来允许 Pod 访问类似 GPU 这类特殊的硬件功能特性,但前提是默认的 OCI runtime 必须改成 nvidia-container-runtime,需要修改的内容如下: /etc/containerd/config.toml ...[plugins."io.containerd.grpc.v1.cri".containerd]snapshotter = "overlayfs"default_runtime_name = "runc"no_pivot = false...[plugins."io.containerd.grpc.v1.cri".containerd.runtimes][plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]runtime_type = "io.containerd.runtime.v1.linux" # 将此处 runtime_type 的值改成 io.containerd.runtime.v1.linux...[plugins."io.containerd.runtime.v1.linux"]shim = "containerd-shim"runtime = "nvidia-container-runtime" # 将此处 runtime 的值改成 nvidia-container-runtime...重启 containerd 服务: $ systemctl restart containerd
部署 NVIDIA GPU 设备插件
一条命令解决战斗:
$ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.7.1/nvidia-device-plugin.yml查看日志:
$ kubectl -n kube-system logs nvidia-device-plugin-daemonset-xxx2020/12/04 06:30:28 Loading NVML2020/12/04 06:30:28 Starting FS watcher.2020/12/04 06:30:28 Starting OS watcher.2020/12/04 06:30:28 Retreiving plugins.2020/12/04 06:30:28 Starting GRPC server for 'nvidia.com/gpu'2020/12/04 06:30:28 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock2020/12/04 06:30:28 Registered device plugin for 'nvidia.com/gpu' with Kubelet可以看到设备插件部署成功了。在 Node 上面可以看到设备插件目录下的socket: $ ll /var/lib/kubelet/device-plugins/total 12drwxr-xr-x 2 root root 4096 Dec 4 01:30 ./drwxr-xr-x 8 root root 4096 Dec 3 05:05 ../-rw-r--r-- 1 root root 0 Dec 4 01:11 DEPRECATION-rw------- 1 root root 3804 Dec 4 01:30 kubelet_internal_checkpointsrwxr-xr-x 1 root root 0 Dec 4 01:11 kubelet.sock=srwxr-xr-x 1 root root 0 Dec 4 01:11 kubevirt-kvm.sock=srwxr-xr-x 1 root root 0 Dec 4 01:11 kubevirt-tun.sock=srwxr-xr-x 1 root root 0 Dec 4 01:11 kubevirt-vhost-net.sock=srwxr-xr-x 1 root root 0 Dec 4 01:30 nvidia-gpu.sock=
测试 GPU
首先测试本地命令行工具 ctr,这个应该没啥问题:且显卡资源是独占,无法在多个容器之间分享。
$ ctr images pull docker.io/nvidia/cuda:9.0-base$ ctr run --rm -t --gpus 0 docker.io/nvidia/cuda:9.0-base nvidia-smi nvidia-smiFri Dec 4 07:01:38 2020+-----------------------------------------------------------------------------+| NVIDIA-SMI 440.95.01 Driver Version: 440.95.01 CUDA Version: 10.2 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. ||===============================+======================+======================|| 0 GeForce RTX 208... Off | 00000000:A1:00.0 Off | N/A || 30% 33C P8 9W / 250W | 0MiB / 11019MiB | 0% Default |+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+| Processes: GPU Memory || GPU PID Type Process name Usage ||=============================================================================|| No running processes found |+-----------------------------------------------------------------------------+
apiVersion: v1kind: Podmetadata:name: cuda-vector-addspec:restartPolicy: OnFailurecontainers:- name: cuda-vector-addimage: "k8s.gcr.io/cuda-vector-add:v0.1"resources:limits:nvidia.com/gpu: 1执行 kubectl apply -f ./gpu-pod.yaml 创建 Pod。使用 kubectl get pod 可以看到该 Pod 已经启动成功:
$ kubectl get podNAME READY STATUS RESTARTS AGEcuda-vector-add 0/1 Completed 0 3s查看 Pod 日志:
$ kubectl logs cuda-vector-add[Vector addition of 50000 elements]Copy input data from the host memory to the CUDA deviceCUDA kernel launch with 196 blocks of 256 threadsCopy output data from the CUDA device to the host memoryTest PASSEDDone可以看到成功运行。这也说明 Kubernetes 完成了对 GPU 资源的调用。需要注意的是,目前 Kubernetes 只支持卡级别的调度,并且显卡资源是独占,无法在多个容器之间分享。 参考资料
[1]官网: https://www.nvidia.com/Download/Find.aspx
[2] 官网: https://developer.nvidia.com/cuda-toolkit-archive
[3] 设备插件(Device Plugins): https://v1-18.docs.kubernetes.io/zh/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/
[4] 容器中使用 GPU 的基础环境搭建: https://lxkaka.wang/docker-nvidia/更多精彩推荐 ☞科技垄断正在朝着纵向发展 ☞挑战TensorFlow、PyTorch,谁才是中国AI开源框架之星?☞被弃用的 Docker 会被 Podman 取代吗? ☞稳居TIOBE前三,涨幅No.1,Python做了什么? ☞索要 2.3 亿元赎金!富士康遭遇黑客攻击 ☞马斯克与贝索斯:世界上最有钱的两人展开太空大战点分享 点点赞 点在看









文章评论