
总第248篇/张俊红
学过统计学的同学应该对置信区间都有了解,置信区间又叫估计区间,是从概率来讲某个随机变量可能取的值的范围。
在前面的文章《聊聊置信度与置信区间》中讲过为什么会有置信区间以及置信区间应该如何求取。在那篇文章中讲了当数据服从正态分布时,95%的置信区间就是均值加减1.96倍的标准差。
那很多时候数据是不符合正态分布,或者是我们不知道样本总体是否符合正态分布,但是我们又需要求取置信区间时,就可以用到我们的今天的主角--Bootstrap抽样的方法。
Bootstrap是对样本进行有放回的抽样,抽样若干次(一般为1000次),每次抽样的结果作为一个样本点,抽样1000次,就会有1000个样本点,用这1000个点的分布作为样本总体的分布,而这1000个点是大概率是服从正态分布的,只要服从正态分布就可以按照正态分布的公式求取置信区间。
那为什么这1000个点是服从正态分布的呢?依据的就是就是中心极限定理,关于中心极限定理的讲解可以看《讲讲中心极限定理》。
接下来我们通过一个例子来看下,首先生成一个长尾分布的数据:
from scipy.stats import f
dfn, dfd = 45, 10
r = f.rvs(dfn, dfd, size=10000)
sns.distplot(r)
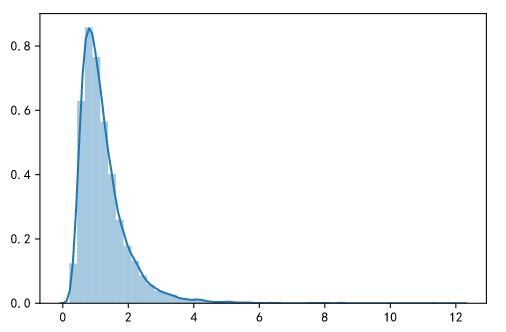
在实际业务中很多数据其实都是符合长尾分布的。然后我们对这个长尾分布的数据进行Bootstrap抽样,有放回的抽样1000次,每次抽10000个样本,最后得到1000个均值,这1000个均值的分布如下:
import numpy as np
sample_mean = []
for n in range(1,1001):
s = np.random.choice(r,size = 10000).mean()
sample_mean.append(s)
运行上面的代码得到如下结果:
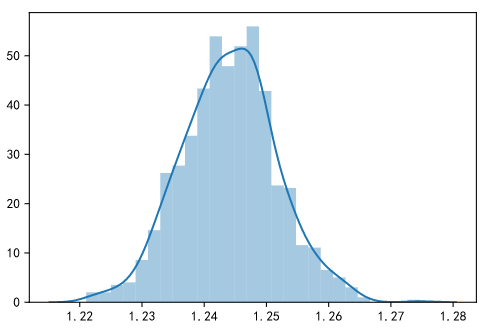
可以看到这1000个均值是符合正态分布的,只要符合正态分布,那我们就可以利用正态分布的性质对其进行估算。
以上就是关于Bootstrap的一个简单介绍,希望对你有用。


文章评论