机器之心发布
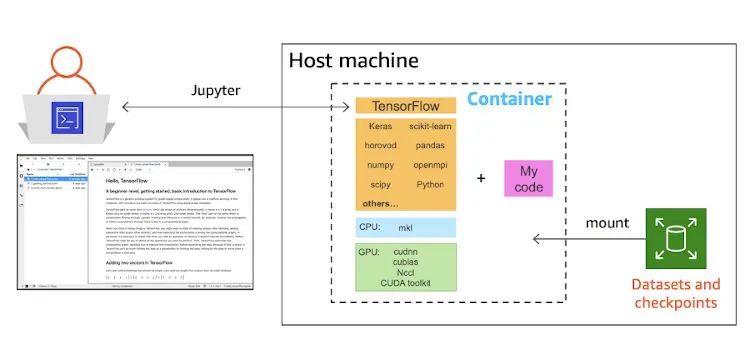
大多数人都喜欢在笔记本电脑上做原型开发。当想与人协作时,通常会将代码推送到 GitHub 并邀请协作者。当想运行实验并需要更多的计算能力时,会在云中租用 CPU 和 GPU 实例,将代码和依赖项复制到实例中,然后运行实验。如果您对这个过程很熟悉,那么您可能会奇怪:为什么一定要用 Docker 容器呢?
运营团队中优秀的 IT 专家们可以确保您的代码持续可靠地运行,并能够根据客户需求进行扩展。那么对于运营团队而言,容器不就成了一种罕见的工具吗?您能够高枕无忧,无需担心部署问题,是因为有一群基础设施专家负责在 Kubernetes 上部署并管理您的应用程序吗?
在本文中,AWS会尝试说明为什么您应该考虑使用 Docker 容器进行机器学习开发。在本文的前半部分,将讨论在使用复杂的开源机器学习软件时遇到的主要难题,以及采用容器将如何缓和这些问题。然后,将介绍如何设置基于 Docker 容器的开发环境,并演示如何使用该环境来协作和扩展集群上的工作负载。
机器学习开发环境:基本需求
首先了解一下机器学习开发环境所需的四个基本要素:
-
计算:训练模型离不开高性能 CPU 和 GPU。
-
存储:用于存储大型训练数据集和您在训练过程中生成的元数据。 -
框架和库:提供用于训练的 API 和执行环境。 -
源代码控制:用于协作、备份和自动化。
作为机器学习研究人员、开发人员或数据科学家,您可以在单个 Amazon Elastic Compute Cloud (Amazon EC2) 实例或家庭工作站上搭建满足这四种要素的环境。
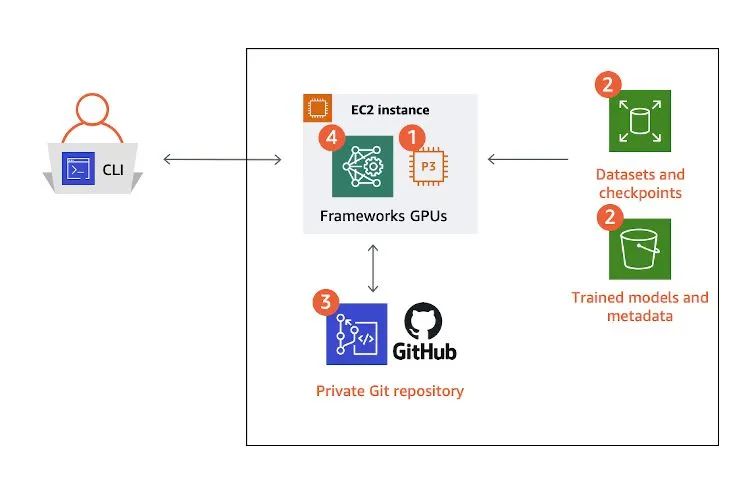
那么,此设置有什么问题吗?
其实也谈不上有问题。因为几十年来,大多数开发设置都是如此:既没有集群,也没有共享文件系统。
除了高性能计算 (HPC) 项目的一小群研究人员能够将开发的代码放在超级计算机上运行之外,绝大多数人都只能依靠自己专用的计算机进行开发。
事实证明,与传统软件开发相比,机器学习与 HPC 具有更多的共同点。与 HPC 工作负载一样,若在大型集群上运行机器学习工作负载,执行速度更快,实验速度也更快。要利用集群进行机器学习训练,您需要确保自己的开发环境可移植,并且训练在集群上可重复。
为什么需要可移植的训练环境?
在机器学习开发流程中的某个阶段,您会遇到以下两个难题:
-
您正在进行实验,但您的训练脚本发生了太多次的更改导致无法运行,并且只用一台计算机无法满足需求。
-
您在具有大型数据集的大型模型上进行训练,但仅在一台计算机上运行使您无法在合理的时间内获得结果。
这两个原因往往会让您希望在集群上运行机器学习训练。这也是科学家选择使用超级计算机(例如 Summit 超级计算机)进行科学实验的原因。要解决第一个难题,您可以在计算机集群上独立且异步地运行每个模型。要解决第二个难题,您可以将单个模型分布在集群上以实现更快的训练。
这两种解决方案都要求您能够在集群上以一致的方式成功复现开发训练设置。这一要求很有挑战性,因为集群上运行的操作系统和内核版本、GPU、驱动程序和运行时以及软件依赖项可能与您的开发计算机有所不同。
您需要可移植的机器学习环境的另一个原因是便于协作开发。通过版本控制与协作者共享训练脚本很容易。但在不共享整个执行环境(包括代码、依赖项和配置)的情况下保证可重复性却很难。这些内容将在下一节中介绍。
机器学习、开源和专用硬件
机器学习开发环境面临的挑战是,它们依赖于复杂且不断发展的开源机器学习框架和工具包以及同样复杂且不断发展的硬件生态系统。虽然这两者都是我们需要的积极特质,但它们却在短期内构成了挑战。
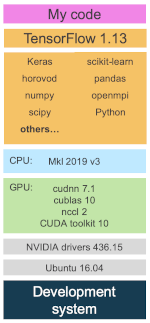
在进行机器学习训练时,您有多少次问过自己以下这些问题:
-
我的代码是否利用了 CPU 和 GPU 上的所有可用资源?
-
我是否使用了正确的硬件库 和硬件库版本? -
当运行环境大同小异时,为什么我的训练代码在自己的计算机上可以正常工作,而在同事的计算机上就会崩溃? -
我今天更新了驱动程序,现在训练变慢/出错了。这是为什么?
如果您检查自己的机器学习软件堆栈,会发现自己的大部分时间都花在了紫红色框(即图中的我的代码)上。这部分包括您的训练脚本、实用程序和帮助例程、协作者的代码、社区贡献等。如果这还不够复杂,您还会注意到您的依赖项包括:
-
迅速演进的机器学习框架 API;
-
机器学习框架依赖项,其中有很多是独立的项目; -
CPU 专用库,用于加速数学例程; -
GPU 专用库,用于加速数学例程和 GPU 间通信例程;以及 -
需要与用于编译上述 GPU 库的 GPU 编译器协调一致的 GPU 驱动程序。
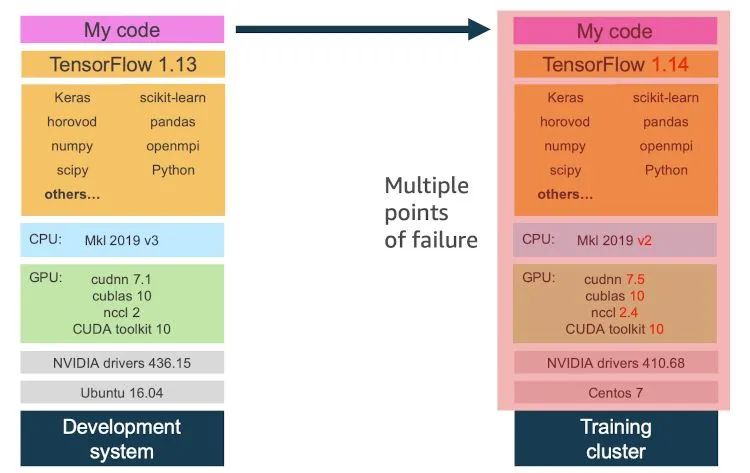
由于开源机器学习软件堆栈的高度复杂性,在您将代码移至协作者的计算机或集群环境时,会引入多个故障点。在下图中,请注意,即使您控制对训练代码和机器学习框架的更改,也可能无法顾及到较低级别的更改,从而导致实验失败。
最终,白白浪费了您的宝贵时间。
为什么不使用虚拟 Python 环境?
您可能会认为,conda 和 virtualenv 之类的虚拟环境方法可以解决这些问题。没错,但是它们只能解决部分问题。有些非 Python 依赖项不由这些解决方案管理。由于典型机器学习堆栈十分复杂,因此很大一部分框架依赖项(例如硬件库)都在虚拟环境范围之外。
使用容器进行机器学习开发
机器学习软件是具有多个项目和参与者的零散生态系统的一部分。这可能是件好事,因为每个人都可以从自己的参与中获益,并且开发人员始终拥有充分的选择。不利方面是要应对一些问题,例如一致性、可移植性和依赖项管理。这就是容器技术的用武之地。在本文中,我不想讨论容器的常规优势,而想讲讲讲机器学习如何从容器中获益。
容器不仅可以完全封装您的训练代码,还能封装整个依赖项堆栈甚至硬件库。您会得到一个一致且可移植的机器学习开发环境。通过容器,在集群上开展协作和进行扩展都会变得更加简单。如果您在容器环境中开发代码和运行训练,不仅可以方便地共享您的训练脚本,还能共享您的整个开发环境,只需将您的容器映像推送到容器注册表中,并让协作者或集群管理服务提取容器映像并运行,即可重现您的结果。
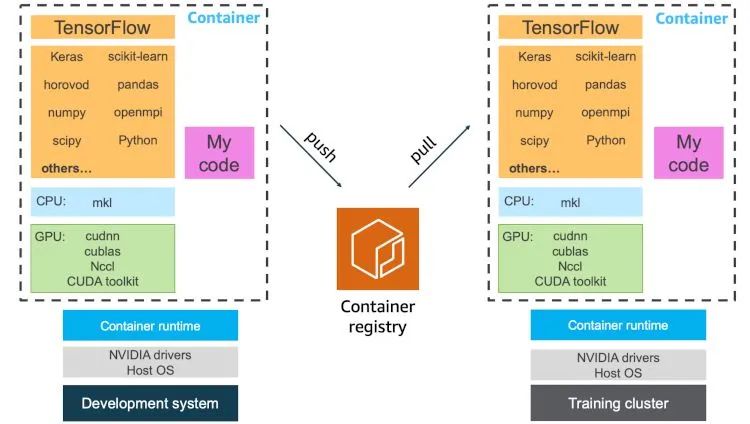
应将/不应将哪些内容包含在您的机器学习开发容器中
这个问题没有正确答案,您的团队如何运营由您来决定,但是关于可以包含哪些内容,有以下几个方案:
-
只包含机器学习框架和依赖项:这是最简洁的方法。每位协作者都可以获得相同执行环境的相同副本。他们可以在运行时将自己的训练脚本克隆到容器中,也可以挂载包含训练代码的卷。
-
机器学习框架、依赖项和训练代码:当扩展集群上的工作负载时,首选此方法。您可以获得一个可在集群上扩展的可执行的机器学习软件单元。根据您对训练代码的组织方式,您可以允许脚本执行多种训练变体,以运行超参数搜索实验。
共享您的开发容器也非常轻松。您可以按以下方式进行共享:
-
容器映像:这是最简单的方法。这种方法允许每位协作者或集群管理服务(例如 Kubernetes)提取容器映像,对映像进行实例化,然后直接执行训练。
-
Dockerfile:这是一种轻量型方法。Dockerfile 中包含关于创建容器映像时需要下载、构建和编译哪些依赖项的说明。可以在您编写训练代码时对 Dockerfile 进行版本控制。您可以使用持续集成服务(例如 AWS CodeBuild),自动完成从 Dockerfile 创建容器映像的过程。
Docker 中心提供了广泛使用的开源机器学习框架或库的容器映像,这些映像通常由框架维护人员提供。您可以在他们的存储库中找到 TensorFlow、PyTorch 和 MXNet 等。在决定从哪里下载以及下载哪种类型的容器映像时,要十分谨慎。
大部分上游存储库都会将其容器构建为在任何位置均可使用,这意味着这些容器需要与大部分 CPU 和 GPU 架构兼容。如果您确切知晓将在怎样的系统上运行容器,最好选择已经针对您的系统配置进行优化的合格容器映像。
使用 Jupyter 和 Docker 容器设置您的机器学习开发环境
AWS 使用常用的开源深度学习框架来托管可用于计算优化型 CPU 和 GPU 实例的 AWS Deep Learning Containers。接下来,我将说明如何使用容器通过几个步骤设置开发环境。在此示例中,我假设您使用的是 Amazon EC2 实例。

第 1 步:启动您的开发实例。
C5、P3 或 G4 系列实例都适合用于机器学习工作负载。后两者每个实例最多可提供多达八个 NVIDIA GPU。有关如何启动实例的简要指南,请阅读 Amazon EC2 入门文档(https://amazonaws-china.com/cn/ec2/getting-started/)。
选择 Amazon 系统映像 (AMI) 时,请选择最新的 Deep Learning AMI,该 AMI 中包含所有最新的深度学习框架、Docker 运行时以及 NVIDIA 驱动程序和库。尽管使用安装在 AMI 本地的深度学习框架看似方便,但使用深度学习容器会让您距离可移植性更强的环境更近一步。
第 2 步:通过 SSH 连接到实例并下载深度学习容器。
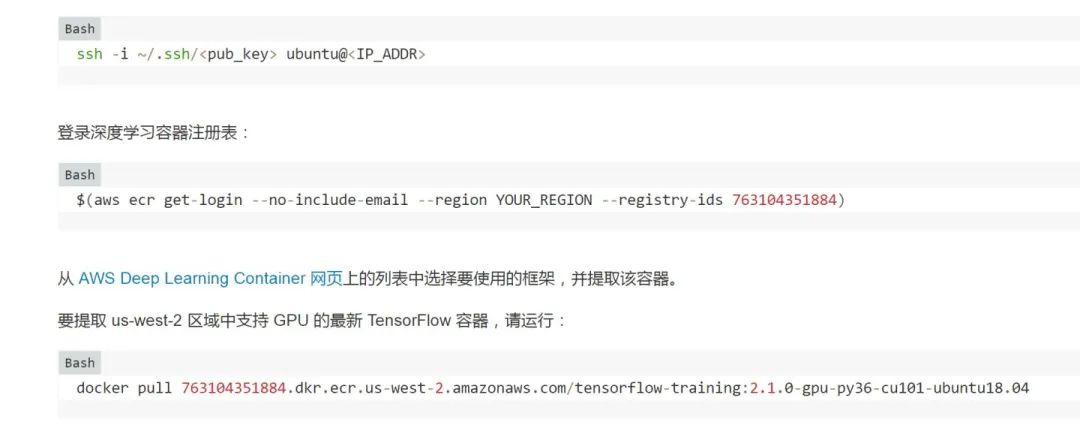
第 3 步:实例化容器并设置 Jupyter。
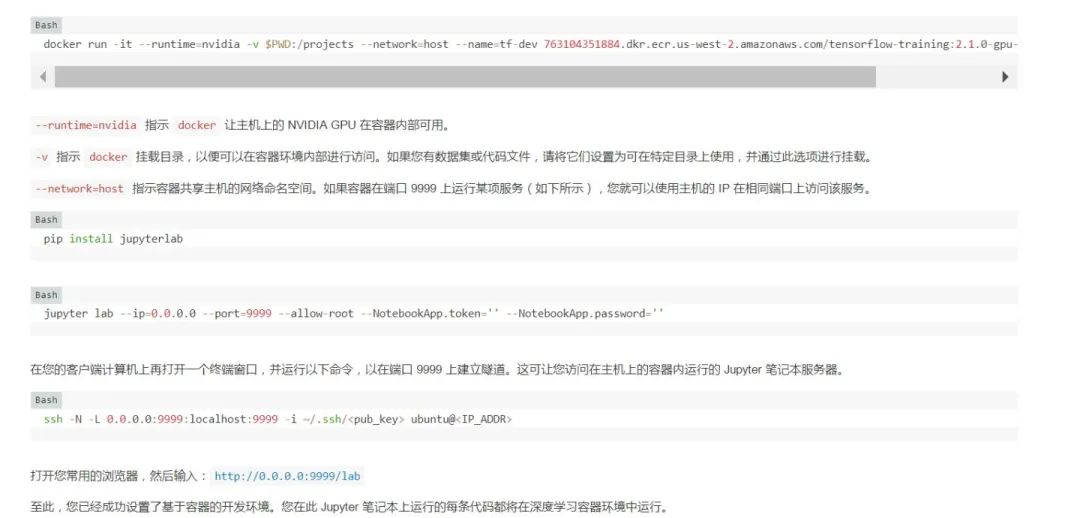
第 4 步:使用基于容器的开发环境。
容器原本是无状态的执行环境,因此请将您的工作保存在调用 docker run 时使用 -v 标志指定的挂载目录中。要退出容器,请停止 Jupyter 服务器并在终端上键入 exit。要重新启动已停止的容器,请运行:
docker start tf-dev按照第 3 步中的说明设置隧道,即可继续进行开发。
现在,假设您要对基本容器进行更改,例如,按照第 3 步所示,将 Jupyter 安装到容器中。最简单的方法是跟踪所有自定义安装并在 Dockerfile 中进行捕获。这使您可以重新创建容器映像,并从头进行更改。这还可用于记录更改,并且可与剩余代码一起进行版本控制。
在对开发过程造成最小干扰的情况下执行此操作的更快方法是,通过运行以下命令将这些更改提交到新的容器映像中:
sudo docker commit tf-dev my-tf-dev:latest
注意:容器纯粹主义者会认为这不是保存更改的建议方法,应将这些更改记录在 Dockerfile 中。这是一个很好的建议,也是通过编写 Dockerfile 跟踪您的自定义设置的好做法。如果您不这样做,则会面临以下风险:随着时间流逝,您将失去对更改的跟踪,并将依赖于一个“工作”映像,就像依赖于无法访问源代码的已编译二进制文件一样。
如果您想与协作者共享新容器,请将其推送到容器注册表,例如 Docker Hub 或 Amazon Elastic Container Registry (Amazon ECR)。要将其推送到 Amazon ECR,请先创建一个注册表,登录,然后推送您的容器:
aws ecr create-repository --repository-name my-tf-dev$(aws ecr get-login --no-include-email --region <REGION>)docker tag my-tf-dev:latest <ACCOUNT_ID>.dkr.ecr.<REGION>.amazonaws.com/my-tf-dev:latestdocker push <ACCOUNT_ID>.dkr.ecr.<REGION>.amazonaws.com/my-tf-dev:latest
现在,您可以与协作者共享此容器映像,并且您的代码应该能像在计算机上一样工作。这种方法的额外好处是您现在可以使用同一容器在集群上运行大规模工作负载。我们来了解一下如何做到这一点。
机器学习训练容器并在集群上扩展它们
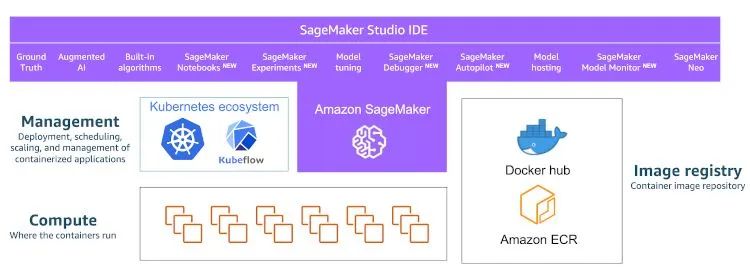
大多数集群管理解决方案(例如 Kubernetes 或 Amazon ECS)都会在集群上调度和运行容器。另外,您也可以使用完全托管的服务,例如 Amazon SageMaker,在其中您可以根据需要配置实例,并在作业完成时自动将其销毁。此外,该服务还提供用于数据标签的完全托管的服务套件、托管的 Jupyter 笔记本开发环境、托管的训练集群、超参数优化、托管模型托管服务以及将所有这些结合在一起的 IDE。
要利用这些解决方案并在集群上运行机器学习训练,您必须构建一个容器并将其推送到注册表。
如果您如上所述采用基于容器的机器学习开发,那么您尽可放心,您开发时所用的容器环境将按计划在集群上大规模运行,而不会出现框架版本问题和依赖项问题。
要在 2 个节点上使用 Kubernetes 和 KubeFlow 运行分布式训练作业,您需要在 YAML 中编写一个如下所示的配置文件:
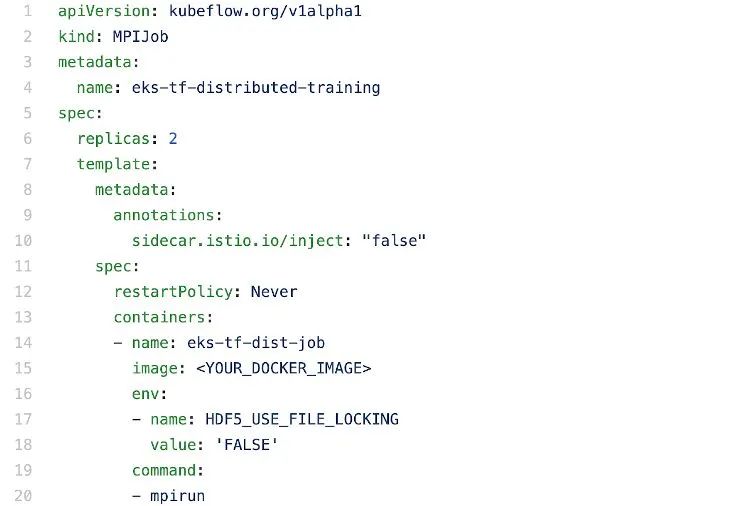
使用 TensorFlow 和 Horovod API 进行分布式训练的 Kubernetes 配置文件的摘录,可在 Github 上找到。请注意,屏幕截图未显示完整文件。
在映像部分下,您将使用训练脚本指定 docker 图像。在命令下,您将指定训练所需的命令。由于这是一项分布式训练作业,因此您将使用 mpirun 命令运行 MPI 作业。
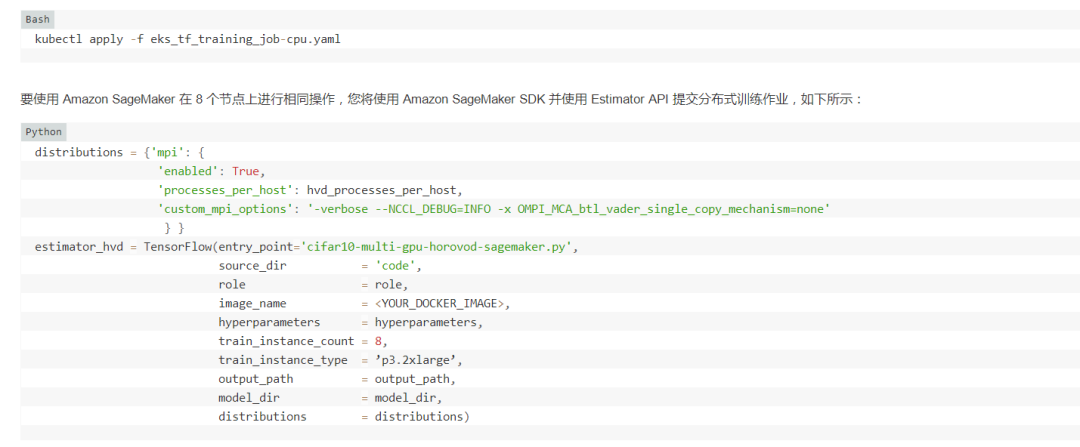
您可以按以下步骤将此作业提交到 Kubernetes 集群(假设集群已设置并正在运行,并且您已安装 KubeFlow):
多疑善思,但不要惊慌失措
机器学习社区发展迅猛。新的研究成果在发布后的数周或数月之内就会在开源框架中的 API 中实施。由于软件迅速演进,及时更新并保持产品的质量、一致性和可靠性颇具挑战。因此,请保持多疑善思,但不要惊慌失措,因为您不是单人作战,并且社区中有许多最佳实践可用来确保您从最新信息中受益。
转向容器化机器学习开发是应对这些挑战的一种途径,希望在本文中我已经解释清楚了这一点。
现在,创建AWS账户即可体验免费产品服务,包括以下内容:

点击阅读原文,即可创建AWS免费账户,体验以上服务。

文章评论