(给Python开发者加星标,提升Python技能)
来源:诡途
https://blog.csdn.net/qq_35866846/article/details/109601322
由于今年疫情,加速了长租公寓的暴雷,某壳公寓频繁传出各种负面新闻,于是把黑猫上关于某壳公寓的投诉内容爬取了下来并进行了分析,就有了这篇完整的数据分析实战项目,从数据获取到数据的分析。
一、数据抓取
import requests,timeimport pandas as pdimport numpy as nprequests.packages.urllib3.disable_warnings() # 屏蔽https请求证书验证警告from fake_useragent import UserAgent # 生成随机请求头# uid请求数据,数据格式较为规范,方便处理def request_data_uid(req_s,couid,page,total_page):params = {'couid': couid, # 商家ID'type': '1','page_size': page * 10, # 每页10条'page': page, # 第几页# 'callback':'jQuery11',}print(f"正在爬取第{page}页,共计{total_page}页,剩余{total_page-page}页")url = 'https://tousu.sina.com.cn/api/company/received_complaints'# 伪造随机请求头header={'user-agent':UserAgent().random}res=req_s.get(url,headers=header,params=params, verify=False)# res = requests.get(url, params=params, verify=False)info_list = res.json()['result']['data']['complaints']result =[]for info in info_list:_data = info['main']# 投诉日期timestamp =float(_data['timestamp'])date = time.strftime("%Y-%m-%d",time.localtime(timestamp))# sn:投诉编号 title :投诉问题 appeal:投诉诉求 summary :问题说明data = [date,_data['sn'],_data['title'],_data['appeal'],_data['summary']]result.append(data)pd_result = pd.DataFrame(result,columns=["投诉日期","投诉编号","投诉问题","投诉诉求","详细说明"])return pd_result# keywords请求数据,数据格式相对混乱# 某梧桐这种没有收录商家ID的公司只能用keywords进行检索处理# 某壳公寓有uid的这种也可以使用keywods进行数据请求def request_data_keywords(req_s,keyword,page,total_page):# page =1params = {'keywords':keyword, # 检索关键词'type': '1','page_size': page * 10, # 每页10条'page': page, # 第几页# 'callback':'jQuery11',}print(f"正在爬取第{page}页,共计{total_page}页,剩余{total_page-page}页")# url = 'https://tousu.sina.com.cn/api/company/received_complaints'url ='https://tousu.sina.com.cn/api/index/s?'# 伪造随机请求头header={'user-agent':UserAgent().random}res=req_s.get(url,headers=header,params=params, verify=False)# res = requests.get(url, params=params, verify=False)info_list = res.json()['result']['data']['lists']result =[]for info in info_list:_data = info['main']# 投诉日期timestamp =float(_data['timestamp'])date = time.strftime("%Y-%m-%d",time.localtime(timestamp))# sn:投诉编号 title :投诉问题 appeal:投诉诉求 summary :问题说明data = [date,_data['sn'],_data['title'],_data['appeal'],_data['summary']]result.append(data)pd_result = pd.DataFrame(result,columns=["投诉日期","投诉编号","投诉问题","投诉诉求","详细说明"])return pd_result#生成并保持请求会话req_s = requests.Session()# 某壳公寓result = pd.DataFrame()total_page = 2507for page in range(1,total_page+1):data = request_data_uid(req_s,'5350527288',page,total_page)result = result.append(data)result['投诉对象']="某壳公寓"result.to_csv("某壳公寓投诉数据.csv",index=False)# 某梧桐 关键词检索# 某壳公寓为品牌名,工商注册名称为某梧桐资产管理有限公司result = pd.DataFrame()total_page = 56for page in range(1,total_page+1):data = request_data_keywords(req_s,'某梧桐',page,total_page)result = result.append(data)result['投诉对象']="某梧桐"result.to_csv("某梧桐投诉数据.csv",index=False)
二、清洗绘图
import os,reimport pandas as pdimport numpy as np# 数据清洗,处理keywords爬取导致的投诉标题混乱data_path = os.path.join('data','某梧桐投诉数据.csv')data =pd.read_csv(data_path)pattern=r'[^\u4e00-\u9fa5\d]'data['投诉问题']=data['投诉问题'].apply(lambda x: re.sub(pattern,'',x))data.to_csv(data_path,index=False,encoding="utf_8_sig")# 数据合并result = pd.DataFrame()for wj in os.listdir('data'):data_path = os.path.join('data',wj)data =pd.read_csv(data_path)result = result.append(data)result.to_csv("data/合并后某壳投诉数据.csv",index=False,encoding="utf_8_sig")
# 读取数据data = pd.read_csv("data/合并后某壳投诉数据.csv")# 筛选到截止昨天的数据,保证按天数据的完整性data = data[data.投诉日期<='2020-11-09']print(f"截至2020-11-09之前,黑猫投诉累计收到某壳公寓相关投诉共计 {len(data)} 条")
# 时间分布处理_data=data.groupby('投诉日期').count().reset_index()[['投诉日期','投诉编号']]_data.rename(columns={"投诉编号":"投诉数量"},inplace = True)# 2020-01-30之前投诉数量求和num1 = _data[_data.投诉日期<='2020-01-30'].投诉数量.sum()data0 =pd.DataFrame([['2020-01-30之前',num1]],columns=['投诉日期','投诉数量'])# 2020-02-01 ~ 2020-02-21号之间投诉情况分布data1=_data[(_data.投诉日期>='2020-02-01')&(_data.投诉日期<='2020-02-21')]# 2020-02-21 ~ 2020-11-05num2 = _data[(_data.投诉日期>='2020-02-21')&(_data.投诉日期<='2020-11-05')].投诉数量.sum()# 2020-11-06 ~ 2020-11-09 本数据只采集到2020-11-09print(f"2020-11-06当天投诉量{_data[_data.投诉日期=='2020-11-06'].iloc[0,1]}条")data2=_data[(_data.投诉日期>'2020-11-06')&(_data.投诉日期<='2020-11-09')]data3=pd.DataFrame([['2020-02-21 ~ 2020-11-05',num2]],columns=['投诉日期','投诉数量'])new_data = pd.concat([data0,data1,data3,data2])
'''配置绘图参数'''import matplotlib.pyplot as plt%matplotlib inlineplt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['font.size']=18plt.rcParams['figure.figsize']=(12,8)plt.style.use("ggplot")new_data.set_index('投诉日期').plot(kind='bar') # 剔除了2020-11-06的数据,24093条
2020-01-30之前属于正常投诉量,偶尔一两单,2月份因为疫情原因,导致投诉量大量增长,可能是因为疫情原因无法保洁,疫情租房补贴之类的,还有被长租公寓暴雷以及某壳破产之类的负面新闻给带起来的租户紧张等等。
2020-02-21之后一直到2020-11-05号投诉量很正常,相比较2020-01-30之前略多,仍在正常经营可接受范围内。
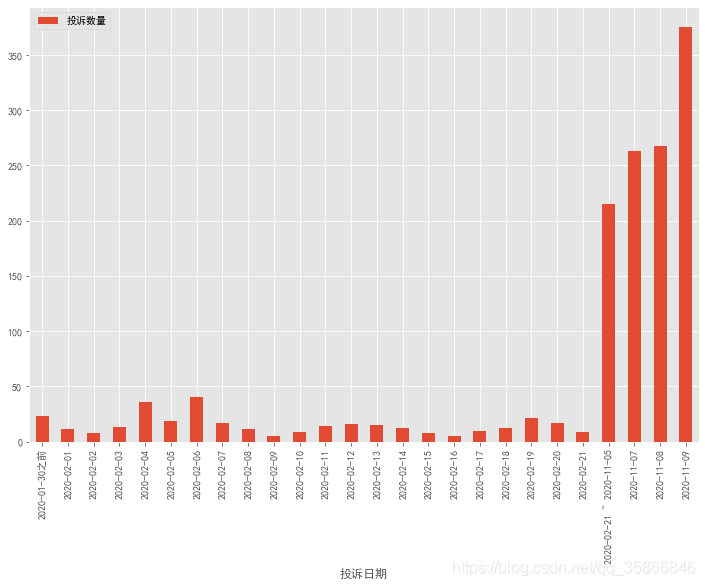
2020-11-06突然骤增了2万4千多条投诉,异常值影响展示,单独剔除出去了,特地去查了一下新闻,看看有没有什么大事儿发生,结果还真有,据36氪报道 2020-11-06某壳公寓关联公司称被执行人,执行标的超519万元。

自此之后的7、8、9某壳在黑猫的投诉每天维持在2-300的日增,看来某壳破产的官方辟谣都是扯淡了,也许并不是谣言,也许网传某壳再现ofo排队讨债并非空穴来风。
以上还是仅仅从黑猫上获取到的投诉数据,投诉无门以及自认倒霉的的用户量又会有多大呢?
接下来就看一下,投诉用户主要投诉的是什么?主要诉求是什么?
三、词云生成
import jieba# 分词模块import reimport collectionsimport PIL.Image as img# pip install PILfrom wordcloud import WordCloudimport PIL.Image as img# pip install PILfrom wordcloud import WordCloud# 投诉详细说明合并后进行分词all_word=''for line in data.values:word = line[4]all_word = all_word+word# jieba分词result=list(jieba.cut(all_word))# 投诉问题词云图wordcloud=WordCloud(width=800,height=600,background_color='white',font_path='C:\\Windows\\Fonts\\msyh.ttc',# 如果存在中文字符需要加载解析的词典max_font_size=500,min_font_size=20).generate(' '.join(result))image=wordcloud.to_image()# image.show()# 生成图片展示wordcloud.to_file('某壳公寓投诉详情.png')# 在本地生成文件展示# 投诉标题合并后进行分词all_word=''for line in data.values:word = line[2]all_word = all_word+word# jieba分词result=list(jieba.cut(all_word))# 生成词云图# 投诉问题词云图wordcloud=WordCloud(width=800,height=600,background_color='white',font_path='C:\\Windows\\Fonts\\msyh.ttc',# 如果存在中文字符需要加载解析的词典max_font_size=500,min_font_size=20).generate(' '.join(result))image=wordcloud.to_image()# image.show()# 生成图片展示wordcloud.to_file('某壳公寓投诉问题.png')# 在本地生成文件展示# 投诉诉求合并后进行分词all_word=''for line in data.values:word = line[3]all_word = all_word+word# jieba分词result=list(jieba.cut(all_word))# 生成词云图# 投诉问题词云图wordcloud=WordCloud(width=800,height=600,background_color='white',font_path='C:\\Windows\\Fonts\\msyh.ttc',# 如果存在中文字符需要加载解析的词典max_font_size=500,min_font_size=20).generate(' '.join(result))image=wordcloud.to_image()# image.show()# 生成图片展示wordcloud.to_file('某壳公寓投诉诉求.png')# 在本地生成文件展示
某壳公寓投诉详情 词云图
投诉详情可以看出来,主要投诉问题:提现,活动返现(每个月返多少钱,我的除了刚开始两个月正常返现,后面也没按时打款,客服打不通后面就没怎么关注了),主要还有客服联系不上,保洁问题等!也许好好直面问题,投诉可能也没那么多。

某壳公寓投诉诉求 词云图
投诉用户的主要诉求大家强烈要求对某壳公寓做出相应处罚并要求退款和赔偿。

- EOF -
1、一文学会爬虫技巧
觉得本文对你有帮助?请分享给更多人
关注「Python开发者」加星标,提升Python技能

点赞和在看就是最大的支持❤️

文章评论