朱政科
读完需要
分钟
速读仅需 3 分钟
-
趋势分析:长期收集并统计监控样本数据,对监控指标进行趋势分析。例如,通过分析磁盘的使用空间增长率,可以预测何时需要对磁盘进行扩容。 -
对照分析:随时掌握系统的不同版本在运行时资源使用情况的差异,或在不同容量的环境下系统并发和负载的区别。 -
告警:当系统即将出现故障或已经出现故障时,监控可以迅速反应并发出告警。这样,管理员就可以提前预防问题发生或快速处理已产生的问题,从而保证业务服务的正常运行。 -
故障分析与定位:故障发生时,技术人员需要对故障进行调查和处理。通过分析监控系统记录的各种历史数据,可以迅速找到问题的根源并解决问题。 -
数据可视化:通过监控系统获取的数据,可以生成可视化仪表盘,使运维人员能够直观地了解系统运行状态、资源使用情况、服务运行状态等。
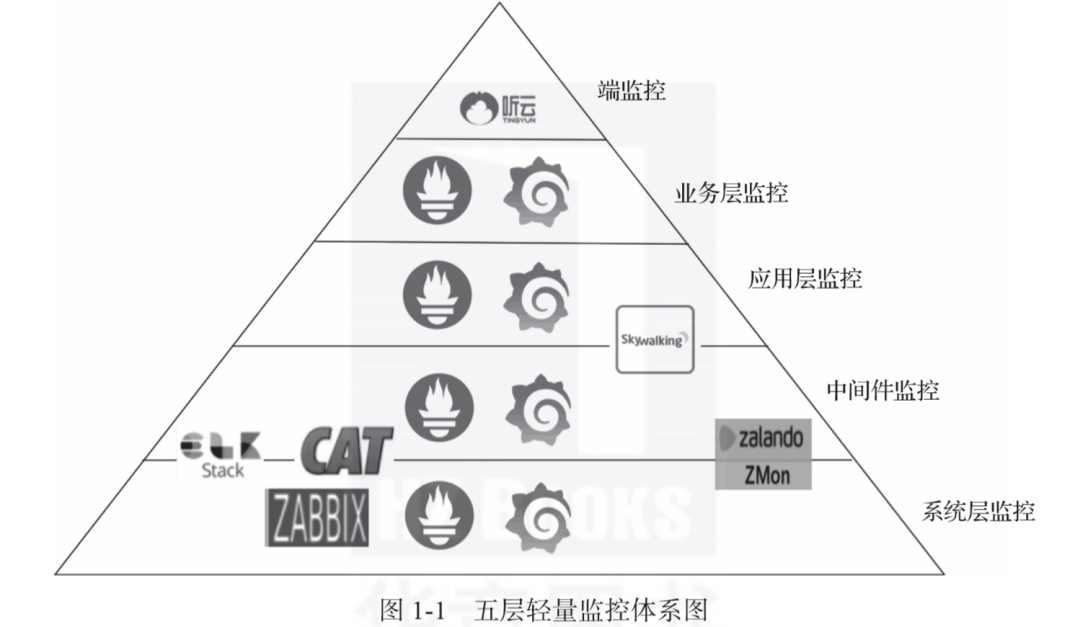
-
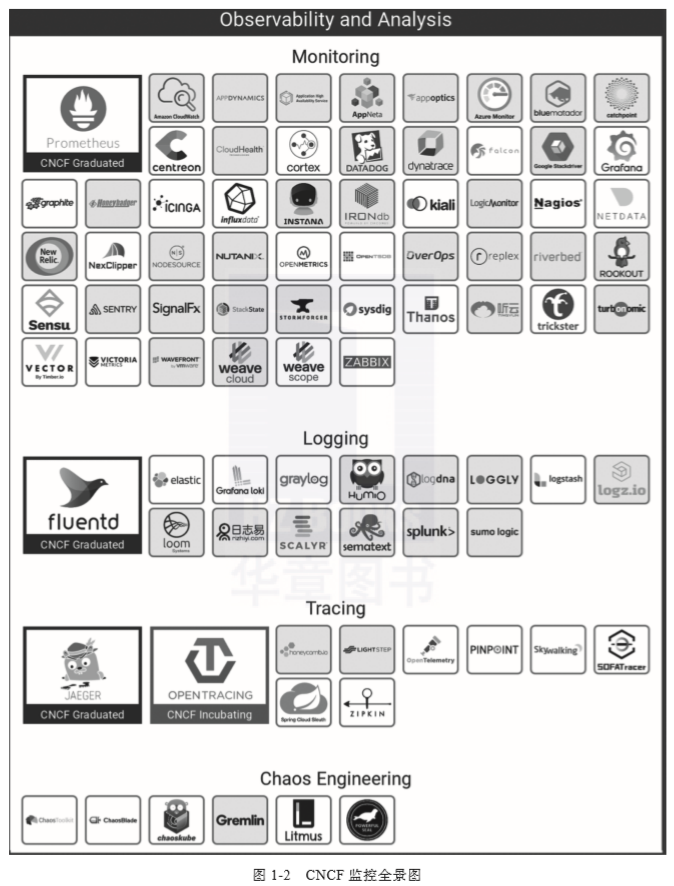
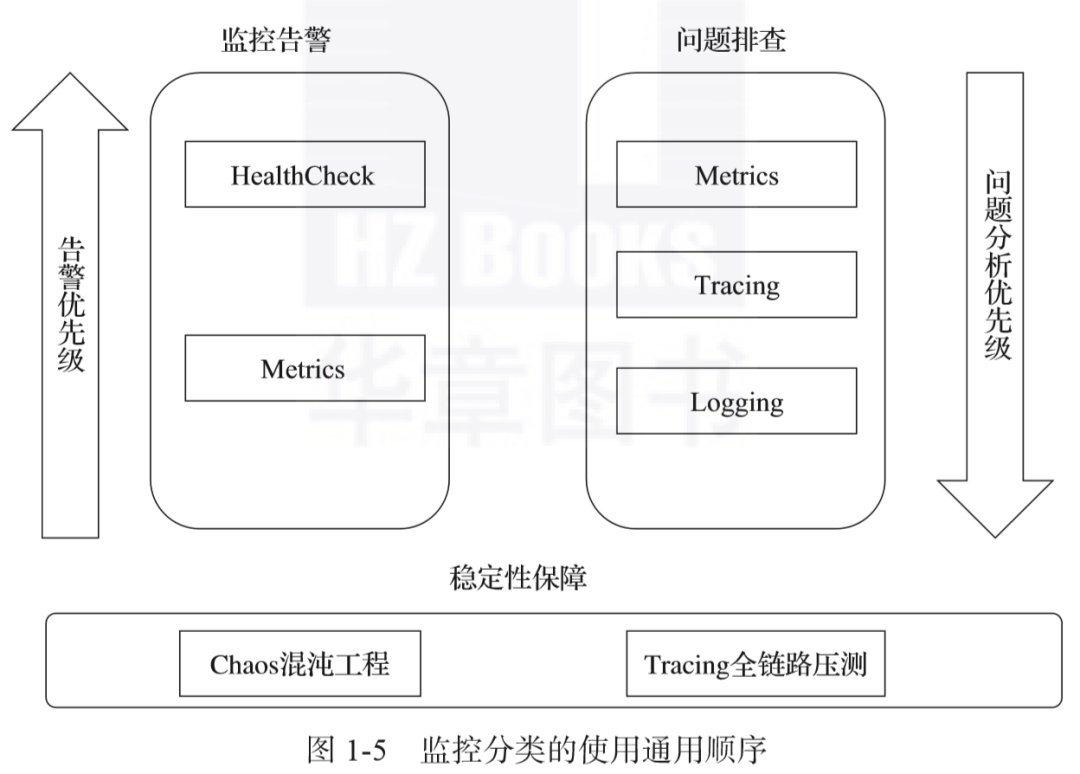
Monitoring子类中的产品与监控相关,包括Prometheus、Grafana、Zabbix、Nagios等常见的监控软件,以及Prometheus的伴侣Thanos。 -
Logging子类中的产品与日志相关,比如Elastic、logstash、fluentd、Loki等开源软件。 -
Tracing子类中的产品与追踪相关,包括Jaeger、SkyWalking、Pinpoint、Zipkin、Spring Cloud Sleuth等。 -
Chaos Engineering是一个新兴的领域。随着云原生系统的演进,系统的稳定性受到很大的挑战,混沌工程通过反脆弱思想,在系统中模拟常见的故障场景,以期提前发现问题。Chaos Engineering可以帮助分布式系统提升可恢复性和容错性。
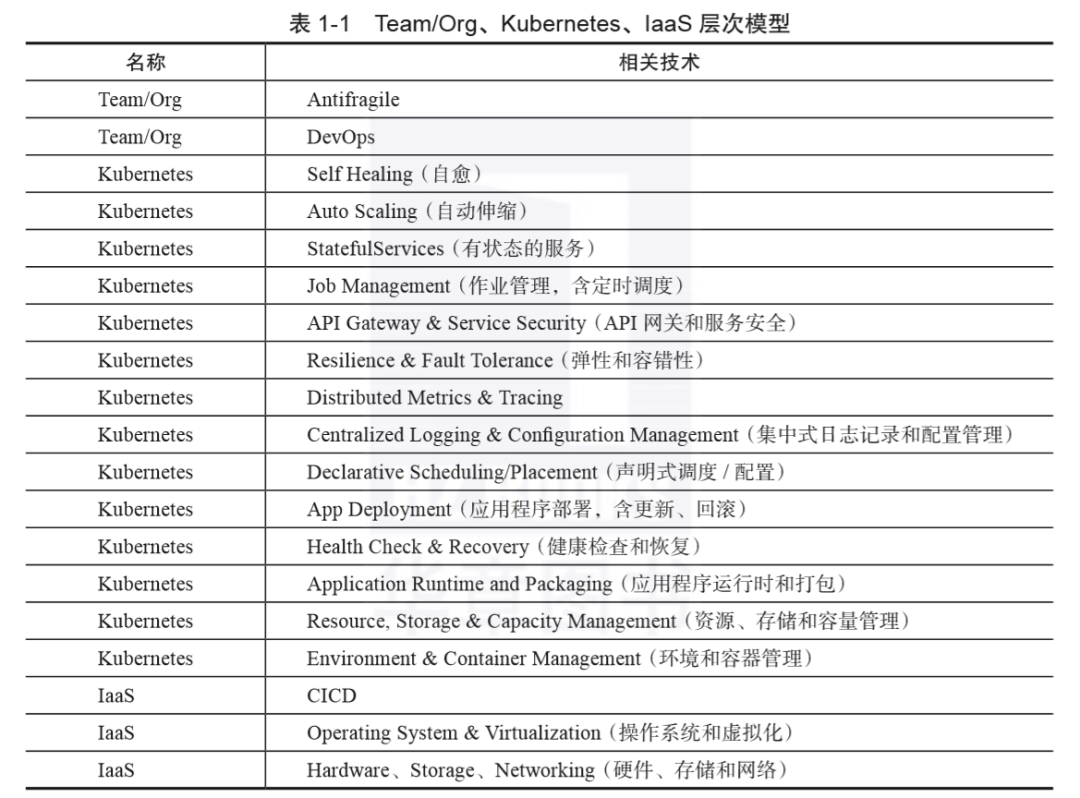
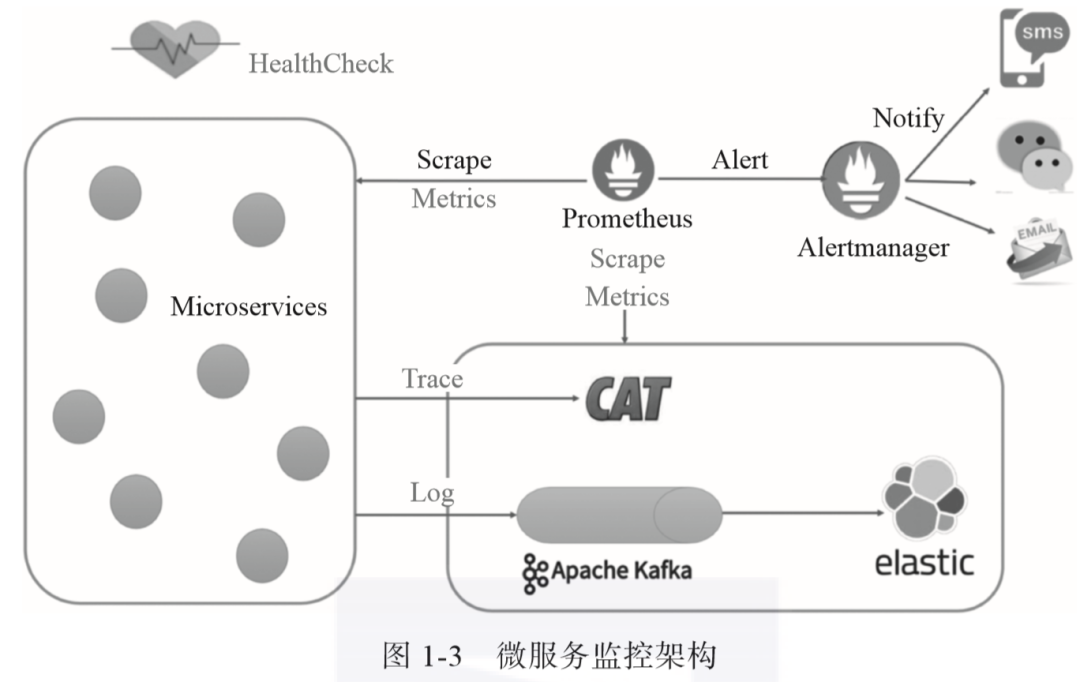
-
Metrics的特点是可聚合(Aggregatable),它是根据时间发生的可以聚合的数据点。通俗地讲,Metrics是随着时间的推移产生的一些与监控相关的可聚合的重要指标(如与Counter计数器、Historgram等相关的指标)。 -
Logging是一种离散日志(或称事件),分为有结构的日志和无结构的日志两种。 -
Tracing是一种为请求域内的调用链提供的监控理念。


-
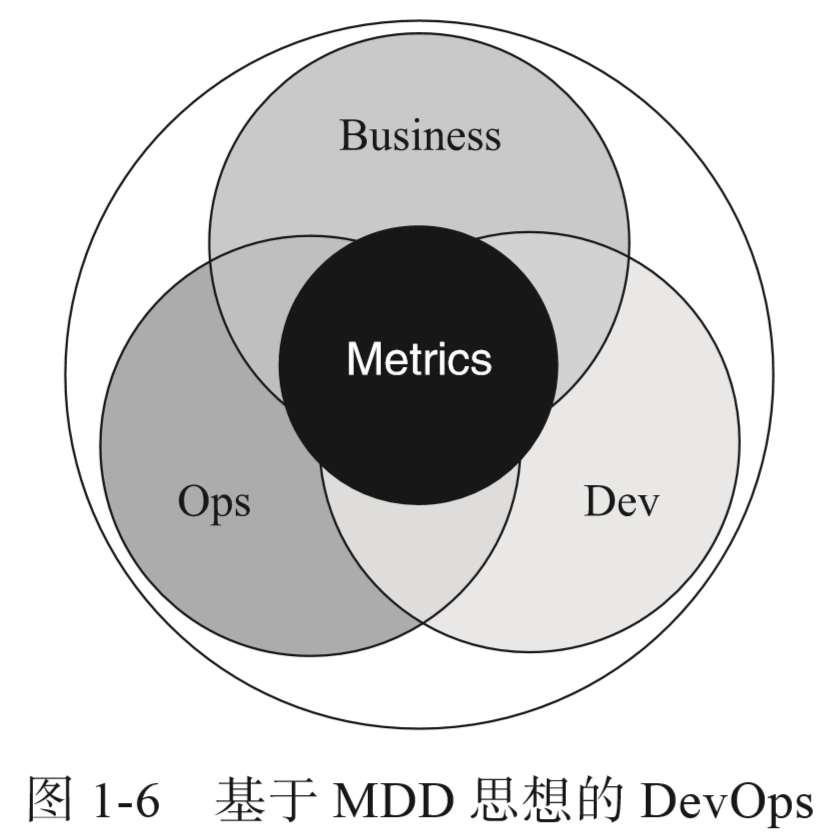
将指标分配给指标所有者(业务、应用、基础架构等)。 -
创建分层指标并关联趋势。 -
制定决策时使用的指标。
-
对软件研发人员来说,可以实时感知应用各项指标、聚焦应用优化。 -
对运维人员来说,可以实时感知系统各项指标、快速定位问题。 -
对产品经理、商务人士来说,可以实时掌控业务各项指标,通过数据帮助自己做出决策。
-
Infrastructure/System Metrics:如服务器状态、网络状态、流量等。 -
Service/Application Metrics:如每个API耗时、错误次数等,可以分为中间件监控、容器监控(Nginx、Tomcat)等。 -
Business Metrics:运营数据或者业务数据,比如单位时间订单数、支付成功率、A/B测试、报表分析等。
-
延迟(Latency):服务请求所需耗时,例如HTTP请求平均延迟。需要区分成功请求和失败请求,因为失败请求可能会以非常低的延迟返回错误结果。 -
流量(Traffic):衡量服务容量需求(针对系统而言),例如每秒处理的HTTP请求数或者数据库系统的事务数量。 -
错误(Errors):请求失败的速率,用于衡量错误发生的情况,例如HTTP 500错误数等显式失败,返回错误内容或无效内容等隐式失败,以及由策略原因导致的失败(比如强制要求响应时间超过30ms的请求为错误)。 -
饱和度(Saturation):衡量资源的使用情况,例如内存、CPU、I/O、磁盘使用量(即将饱和的部分,比如正在快速填充的磁盘)。
-
使用率:关注系统资源的使用情况。这里的资源主要包括但不限于CPU、内存、网络、磁盘等。100%的使用率通常是系统性能瓶颈的标志。 -
饱和度:例如CPU的平均运行排队长度,这里主要是针对资源的饱和度(注意,不同于四大黄金指标)。任何资源在某种程度上的饱和都可能导致系统性能的下降。 -
错误:错误数。例如,网卡在数据包传输过程中检测到以太网络冲突了14次。
-
(Request)Rate:每秒接收的请求数。 -
(Request)Errors:每秒失败的请求数。 -
(Request)Duration:每个请求所花费的时间,用时间间隔表示。

- EOF -

想要加入中生代架构群的小伙伴,请添加群合伙人大白的微信
申请备注(姓名+公司+技术方向)才能通过哦!


好文推荐
2020-11-13

2020-11-12

2020-11-10

2020-11-09

2020-11-11

2020-11-06

2020-11-05

2020-11-03

2020-11-02

2020-10-30

2020-10-28

2020-10-27

2020-10-22

2020-10-20

2020-10-19

END
#架构师必备#
点分享 点点赞 点在看





文章评论