
原文作者:Nicholas J. DeVito,Georgia C. Richards & Peter Inglesby
对于Nicholas DeVito、Georgia Richards 和Peter Inglesby来说,个性化的网络爬虫正在高效地推动着他们的研究,同时也推动了他们的合作。
时间和资源对于研究来说非常宝贵。将像数据收集这类普遍的任务自动化会使项目变得更为高效与可重复,从而提高生产率与结果产出。最终你会得到一种可共享、可复用的数据收集工作流程,使得其他研究人员也可以验证、使用和拓展你的研究成果,形成在计算上可复用的数据收集工作流。
构建网络爬虫工具来建立自己的在线研究。图片来源:Shutterstock
我们在最近的项目中,通过分析一系列验尸报告(https://www.judiciary.uk/subject/prevention-of-future-deaths/)来帮助避免未来发生死亡。整个项目需要下载超过3000份PDF文件并搜索出与阿片相关的死亡,这是一项庞大的数据收集工作。在与其他团队的研究人员探讨后,我们认为这是使用自动化方式处理的一个绝佳机会。经过几天的工作后,我们就编出了可以快速、高效、可复用的程序收集PDF文档(https://github.com/georgiarichards/opioiddeaths),并为每一个案例创建出相关的电子表格。
我们团队经常使用的这项工具被称为“网络爬虫”。我们使用它去从临床试验注册中收集信息,并不断丰富OpenPrescribing.net数据,用于追踪英格兰的初级医疗处方数据。如果没有爬虫的帮助,这会是一项十分冗长甚至不可能完成的任务。
在验尸报告项目中,人工方式可以在一小时内打开并保存约25份报告,而现在程序可以在一小时内打开并保存下超过1000份报告,在节省大量的人工时间的同时,将效率提高到了原先的40倍。更重要的是,这种方式还通过共享数据集创造了新的协作机会,并能通过重新运行程序来持续追踪新发布的报告,不断更新数据集。
在这些实践经验的基础上,我们将在接下来的内容里阐述爬虫的基本知识,以及如何在研究中使用爬虫来提高科研效率。
爬虫如何运行?
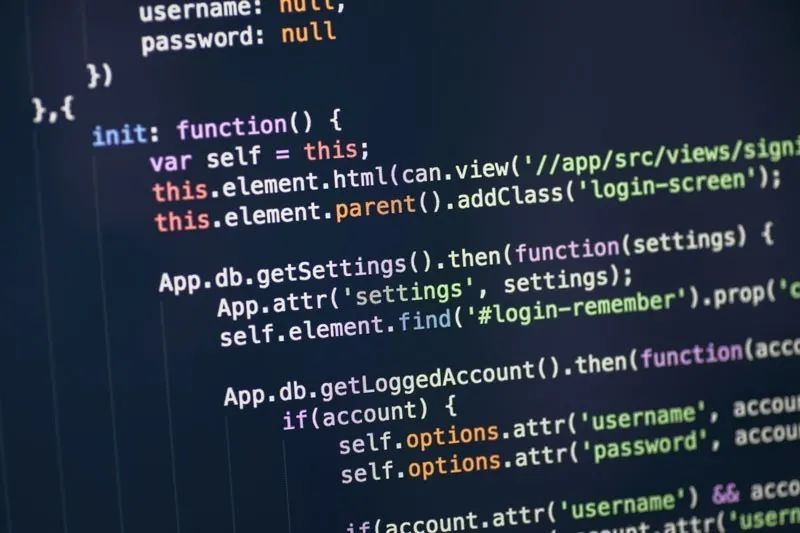
网络爬虫是可以从网站中抽取(爬取)特定信息的程序。网页的结构和内容通过超文本标记语言(Hypertext Markup Language, HTML)来进行组织,你可以通过浏览器的“查看源代码”或“审查元素”选项看到(注:一般浏览器点击右键/F12就能看到查看源代码/审查元素)。爬虫可以理解HTML并对其进行解析,从中抽取有用的信息。例如,你可以编写一只抽取特定领域的信息的爬虫,包括抽取在线文档或者下载链接到本页面的文件。
通常来讲,一个典型的爬虫程序需要对所有可能的URL进行迭代处理,例如抓取从www.example.com/data/1到www.example.com/data/100的数据,并保存每一页中你需要的东西,同时还不会在抽取过程中引入人为错误的风险。一旦程序完成编写,你可以在任何你需要的时候重新爬取数据,不过这需要假设网站在绝大多数情况下结构保持不变。
如何着手?
并不是所有的爬虫都需要编程。有很多像webscraper.io这样的插件在浏览器中可以开箱即用,只需要点点鼠标选择页面中感兴趣的内容,它们就能自动地帮助你解析相关的HTML内容并输出你需要的数据。
另一种稍微复杂的方式是构建自己的爬虫系统,虽然需要动手写代码,但是会赋予你更多的可控性。我们主要使用Python构建爬虫系统,但任何现代爬虫语言都可以做到爬取数据 (具体来讲,Python一般使用Request和BeautifulSoup包,R语言则更多使用rvest包)。在开始编程前,可以先搜索是否有前人已经为你需要的数据源写过爬虫了,如果没有也不用担心,无论哪种语言在网络上都有充足的免费教程供你学习和理解,帮助你编写出自己的爬虫。
和大多数编程一样,爬虫的编写当然也免不了试错的过程,不同的网站拥有不同的数据结构体系和各种不同的HTML实现形式。然而解决问题的过程却十分有益,随着你不断地解决问题,不断地克服困难会内化成你意识的一部分。
值得注意的是:爬虫程序运行的时间取决于爬取分析的页面数量、网络连接状况以及网站服务器的性能,有的可能需要几天的时间,所以在私有服务器上运行爬虫程序会比较好。如果在自己的个人电脑上运行,则需要确保电脑不会进入睡眠模式,中断网络连接。同时也要仔细预想爬虫失败的原因,并仔细地记录下爬虫的日志信息,以便知道哪些可行,哪些不行,哪些需要进一步深挖。

三思而后行
获取数据容易吗?从ClinicalTrials.gov上每天爬取所有30多万条数据,对于我们的FDAAA TrialsTracker(https://fdaaa.trialstracker.net/)项目而言是一个十分庞大的任务,但幸运的是,ClinicalTrials.gov将他们的完整数据开放下载了;我们的软件只需要每天下载一次开放的数据集就好。我们的EU TrialsTracker项目就没有那么幸运了,所以我们要每月爬取EU registry(https://github.com/ebmdatalab/euctr-tracker-code)。
如果没有批量下载链接,那就查阅网站是否提供了应用程序接口(application programming interface, API)。API提供了软件与网站直接进行交互的接口,而无需请求HTML内容。与直接爬取网页内容相比,这种方式会更为便捷,但也许会带来额外的API费用。我们在工作中经常使用PubMed API。此外,还可以与网站运营者直接联系,看看是否能够直接为你提供数据。
网站是否可爬?一些网站并没有直接提供HTML形式的可用数据,需要更为先进的技术来获取数据(可以到StackOverflow等问答网站上寻求帮助)。另一些网站还有输入验证码和反DoS等反爬措施,增加了爬取的难度。还有少数网站不想让别人爬取,在构建时就不鼓励爬虫。此外很多网站还提供了一套爬虫规则在根目录下的robots.txt中,只有按照这些规则与网站进行交互,才能进行有效的信息爬取。
你的程序是不是一只有礼貌的爬虫?你的程序每一次向网站请求数据都需要调用网站的资源服务。当我们在浏览器中访问网页时不会发送太多请求,但是由程序编写的爬虫可以在一分钟内向服务器发送成百上千个请求。这样高负载的访问会使得网站运行变慢甚至宕机(频繁的请求无意中成为了对网站的DoS攻击)。这可能会使你的IP被网站暂时地、甚至永久地封禁——所以你应该尽可能地减少对于网站的负载压力。一方面可以在每次请求后间隔数秒,另一方面也可以在robots.txt中查阅网站期望的间隔时长。
数据是否有限制?需要检查抽取数据的版权或许可。一般情况下,你可以使用爬取的数据,但要共享这些数据时,就需要仔细考虑是否符合法律法规。理想情况下,网站会提供对应的内容许可证。但无论你是否分享了数据,你都应该在像GitHub这样的开源社区公开的你的代码,这是开源文化与实践的重要部分,可以让其他有需要的人轻松地找到、复现并扩展你的代码。
我们强烈推荐更多的研究人员开发代码来进行研究,并向社区共享这些代码(https://stackoverflow.com/)。在项目中如果手工收集数据遇到困难,那么爬虫也许是一个不错的解决方案,同时也是很好的入门编程项目。爬虫的复杂程度足够展示软件开发过程中的重要内容,但同时非常丰富的资料也为初学者提供了充足的实践信心。在电脑上编写简单的代码与外界进行交互,感觉就像拥有了研究超能力一样美妙,你还在等什么呢?
原文以 How we learnt to stop worrying and love web scraping为标题发表在 2020年9月8日的《自然》职业版块
© nature
doi: 10.1038/d41586-020-02558-0
点击阅读原文查看英文原文
相关文章:

点击图片了解自然职场线上招聘会更多内容

扫描二维码报名参加自然职场线上招聘会,了解海内外学术界和产业界的工作机会,并参加会议环节,倾听自然科研高级编辑和名校专家讲授实用的论文写作和学术简历撰写技巧。
版权声明:
本文由施普林格·自然上海办公室负责翻译。中文内容仅供参考,一切内容以英文原版为准。欢迎转发至朋友圈,如需转载,请邮件[email protected]。未经授权的翻译是侵权行为,版权方将保留追究法律责任的权利。
© 2020 Springer Nature Limited. All Rights Reserved

喜欢今天的内容吗?喜欢就给我们一个“三连”(转发,将公众号设为星标?,在看⇣⇣)吧!


Nature Research科研服务
点击图片阅读

文章评论