一、“爬虫”是什么
大东:小白,身为计算机学科的学生,“网络爬虫”你应该不陌生吧?
小白:那当然了,写的最多的就是“爬虫”程序了。
大东:既然你这么熟悉,能给我讲讲什么是“爬虫”么?
小白:当然能,终于有一天能给大东动反向传播知识啦,哈哈哈!“网络爬虫”就是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,能够把网站上的信息收集回来,并且能在网站之间游走。
大东:没错。随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大挑战,搜素引擎就是一种典型的“爬虫”应用,它每隔几天对全网的网页扫一遍,以便大家查阅,被扫网站也乐意被收集。但是,小白你知道吗?“爬虫”也分善恶!
小白:我可没有写过恶意的“爬虫”,大东东你别看我。
大东:像抢票软件这样的“爬虫”,对着 12306 每秒扫几万次,被扫网站对它十分厌恶。
小白;哦,作为12306用户的我,也挺讨厌抢票软件的。
大东:那你知道网络世界这么多“爬虫”,都爱爬哪些网站?
小白:我猜...我猜不出来...求大东东指教!

网络爬虫(图片来自网络)
二、爬虫分布图
大东:根据“python技术客栈”公开的世界“网络爬虫”分析结果,爬虫最多的就是出行软件,比如前面所说的12306就是他们的目标之一;紧随其后的是社交软件、电商软件。
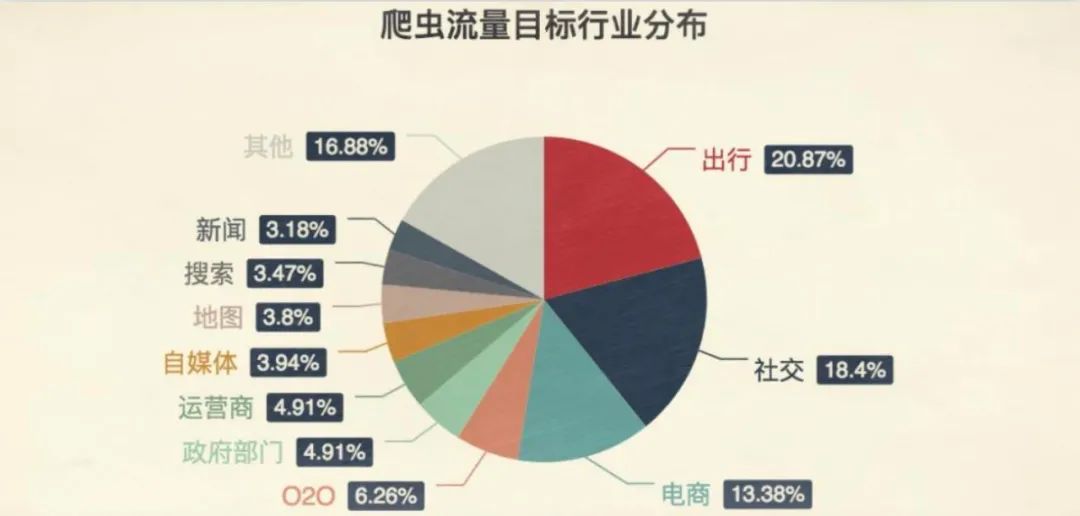
“爬虫”流量目标行业分布(图片来自网络)
小白:没想到“爬虫”种类还不少呢!
1、“爬虫”最大聚集地——出行软件
大东:出行行业中“爬虫”的占比最高,在出行的“爬虫”中,有89.02%的流量都是冲着 12306 去的。
小白:哇哦,全中国卖火车票的独此一家别无分号,也难怪呢。
大东:小白你有没有发现,12306的验证码比其他网站的更为复杂呢?
小白:没错,有时候我甚至觉得自己智商不够用了。
大东:这些东西不是为了故意难为卖票的普通用户,而恰恰是为了阻止抢票软件这种“爬虫”的点击。简单的“爬虫”无法正确识别复杂二维码,因此就能够被挡在门外。
小白:不对啊,可现在还是可以用抢票软件抢到票啊。
大东:没错。抢票软件也不是吃素的,它们在和12306搞“对抗”。“打码平台”,你听说过吗?
小白:那是啥?
大东:打码平台雇佣了很多叔叔阿姨,他们的工作就是帮人识别验证码。当抢票软件遇到了验证码,系统就会自动把这些验证码传到他们面前,以人工的方式完成识别,然后再把结果传回去。这期间总共只需要几秒时间。
小白:厉害了啊!
大东:这样的打码平台还有记忆功能,当遇到已经标记过的图,系统能直接判断它是验证答案。时间一长,12306 系统里的图片就被标记完了,机器自己都能认识,人工环节就可以省略了。
小白:人工击败数据库啊这是!
大东:每当过年前,就是12306最繁忙的时候。据公开数据表示:“最高峰时1天内页面浏览量达813.4亿次,1小时最高点击量59.3亿次,平均每秒164.8万次。”这还是加上验证码防护之后的数据,可想而知被拦截在外面的爬虫还有多少。
小白:天呐,我回家的票就是被他们抢走的。
大东:被抢票软件把票抢走,对我们父母那样的不会抢票的人来说,是不是公平呢?
小白:太过分了!
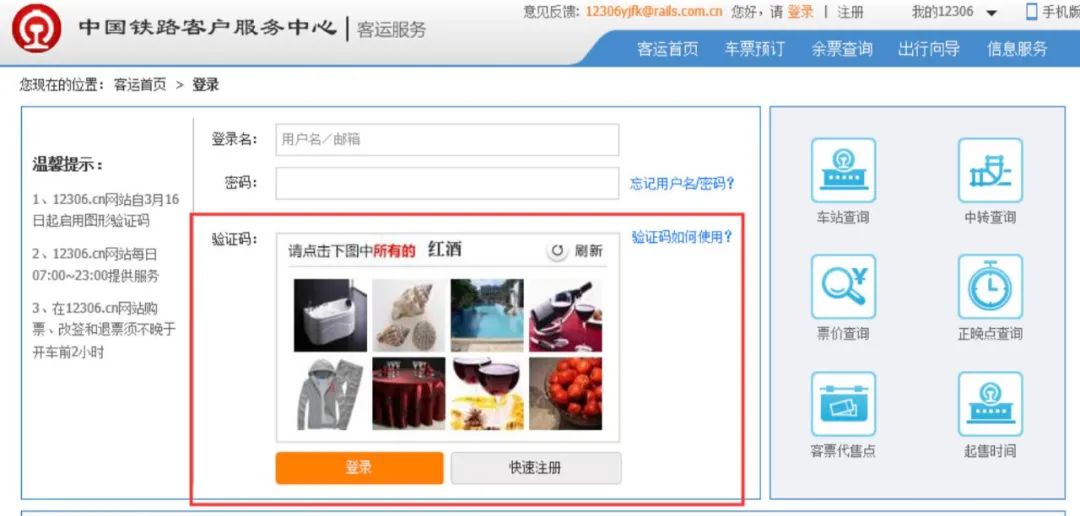
12306验证码(图片来自网络)
2、水军势力——社交软件“爬虫”
小白:社交软件也有什么可“爬”的么?
大东:你想,如果我能随心所欲地指挥一帮机器人,打开某人的微博,然后刷到某一条,然后疯狂关注、点赞或者留言……
小白:噢!僵尸粉!
大东:你想这个场景:一个路人甲的微博没人关注,于是用大量的“爬虫”给自己做了十万人的僵尸粉,一群僵尸在我的微博下面点赞评论,不亦乐乎。
小白:这有啥好乐的?
大东:接着,路人甲找到一个游戏厂商,跟他说:你看我有这么多粉丝,你在我这投广告吧。我帮你发一条游戏的注册链接,每有一个人通过我的链接注册了游戏,你就给我一毛钱。广告主说,不错,就这么办。
小白:那他发的注册链接,也没人点啊。
大东:路人甲不慌,又让十万“爬虫”继续前赴后继地点击注册链接,然后自动去完成注册动作。
小白:哇,这不是骗钱呢嘛!
大东:我只是举了个例子,数据不一定和现实吻合,具体操作也会更复杂。
小白:这种赚钱方式,太过分了!
大东:你再想象下这个场景:微博上经常有明星给粉丝发红包么,于是有人率十万僵尸粉去抢……
小白:难怪我每次打开都是“已抢完”啊!这些“爬虫”太过分啦!
3、购物“助手”——电商软件“爬虫”
大东:小白,你在网上购物是怎么挑选商品的呢?
小白:我就是在每个软件上搜索我要买的东西,然后一家一家对比。
大东:作为老网购人了,你竟然不知道有种东西叫做“比价网站”。
小白:还有这东西?
大东:在比价网站上,你搜索一样商品,这类聚合平台就会自动把各个电商的商品都放在你面前供你选择,基本各大购物网站都能囊括在内。
小白:好东西呀,回头我试试!
大东:这就是“爬虫”的功劳。它们去各家电商软件上,把商品的图片和价格统统扒下来,然后在自己这里展示。
小白:电商网站知道自己被“爬”了吗?
大东:当然知道。然而电商网站是拒绝的,但是很难阻止这类事情发生。由于“爬虫”是模拟普通用户的点击行为,电商网站通常难以辨别机器行为,甚至都不能使用复杂验证码。
小白:是啊,如果每点开一个商品详情,就要做一次验证,还剁手呢,我都想剁了手机!不过为啥电商软件不喜欢被“爬”呢?
大东:对同一商品在单个电商软件内,它能决定哪个搜索结果排在前面,哪个在后面。但是如果用户一旦使用了比价平台,这个排名就失去了意义,电商软件就丧失了控制权。
小白:也是,断人财路,难怪不受欢迎。
三、“爬虫”合法吗?
小白:大东东你说了这么多,我有些疑惑了,难道爬虫一种违法行为么?
大东:这个问题还真的不简单,《网络安全法》里没有对“爬取网络公开信息被认定为违法”的条款,但是有条司法解释值得注意:“未经授权爬取用户手机通讯录超过50条记录;未经授权抓取用户淘宝交易记录超过500条;未经授权读取用户运营商网站通话记录超过500条;未经授权读取用户公积金社保记录的超过50000条的。”以上这些情况可以入刑。
小白:这个我可得注意注意,别一不小心违法乱纪啦。
大东:与被“爬”企业势不两立的爬虫,说白了,就是阻挡了对方的财路。企业也不会善罢甘休,经典的对抗方式,除了刚才说的验证码外,还有滑块验证、封禁 IP、给访问者增加一些加解密运算,耗费“爬虫”的程序资源等等。
小白:各显神通的对抗啊。
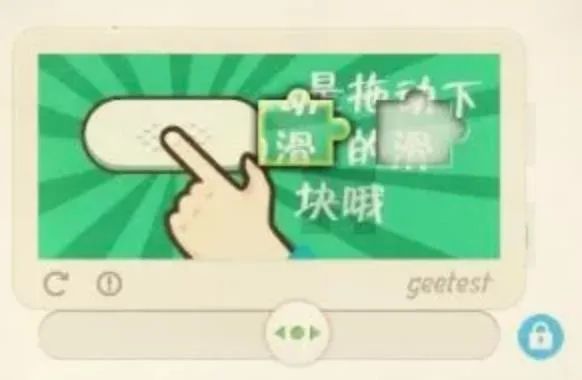
滑块验证(图片来自网络)
大东:“爬虫”是一种在广阔万维网上收集信息的技术,本身并没有好坏之分,但写“爬虫”程序的人是趋利的,当他们想用“爬虫”来达到自己不可告人的秘密时,爬虫就有了好坏之分。
小白:技术是把双刃剑啊!我们应该好好规范自己的使用,并且互相监督,让这个世界更加美好。
参考链接:
1. 中国爬虫图鉴 https://mp.weixin.qq.com/s/owfGEhjMrLmGRNatP8eDjg
2. 网络爬虫 https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711
3. Python爬虫原理 cnblogs.com/sss4/p/7809821.html
4. “来我公司写爬虫吗?会坐牢的那种!” https://blog.csdn.net/yellowzf3/article/details/102634078
5. 陈根:从爬虫技术到爬虫行为,网络爬虫的罪与非罪 https://www.sohu.com/a/414338280_124207
来源:中国科学院计算技术研究所
温馨提示:近期,微信公众号信息流改版。每个用户可以设置 常读订阅号,这些订阅号将以大卡片的形式展示。因此,如果不想错过“中科院之声”的文章,你一定要进行以下操作:进入“中科院之声”公众号 → 点击右上角的 ··· 菜单 → 选择「设为星标」


文章评论