点击上方“朱小厮的博客”,选择“设为星标”
当当满200减40优惠码「J2KNAE」

来源:r6d.cn/2Zrc
Zabbix 适合的监控场景
监控的维度

可用性监控:它的状态是一个布尔型,即只有 1 或者 0。比方说,一个服务是处于停止状态还是运行状态,一个端口是 Up 还是 Down,根据可用性监控我们可以获知监控对象是否处于正常状态。
性能监控:是基于可用性监控的更进一步监控。比如说我们监控某个 IP 地址,在可用性监控中我们会去 Ping 这个 IP。
如果通,就说明这个 IP 可达;更进一步,Ping 延迟就是这个 IP 的性能监控。通过性能监控,我们可以获知监控对象的健康程度以及负载水平。CPU、内存使用率,磁盘的 IOPS,网络的吞吐量,都是常见的性能监控指标。
日志监控:不管是可用性监控还是性能监控,都基于一定的轮询周期进行采样,在两个采样点之间的监控其实是缺失的,因此在两个采样点之间可能会遗漏一些异常监控数据。
通过日志监控,可以记录下每一个操作或者行为,确保监控的完整性。常用的日志监控会分为安全日志、系统日志、应用日志和操作日志等。
自定义的监控:顾名思义,根据我们自身的情况去定义一些符合我们监控需求的监控指标。比如订单数、网络设备流量的聚合运算等等。
监控选型

不过,通常情况下我们的环境中还充满了网络设备、Linux、存储等其他监控对象。
这个时候使用 System Center 去监控可能就比较难以实施了,即使能实施,仍然会存在较高的成本或者技术局限性。同样 Solarwind 更加适合网络设备的监控。
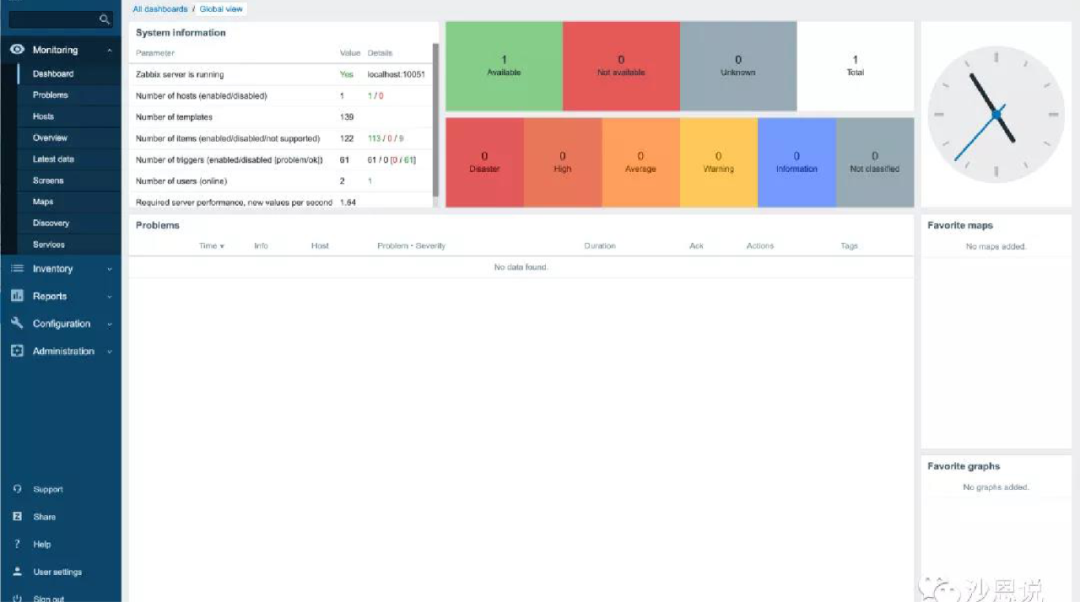
的确,在 Zabbix 早些的版本比如 1.8,2.2 中,它的 UI 并没有那么友善和好看。
但是官方团队始终在不断迭代和完善 UI,5.0 的 UI 已经非常现代化,而且图形图表的展现也更丰富多彩。
同时 Zabbix 90% 以上的配置管理操作都可以通过 Zabbix 的 Web 端实现,仅有一部分基础配置需要通过配置文件处理。
这样有一个很大的好处:所有的维护都会有统一的入口,而且只要通过简单的点击、拖拽操作就可以完成,大大提升了运维团队的效率。
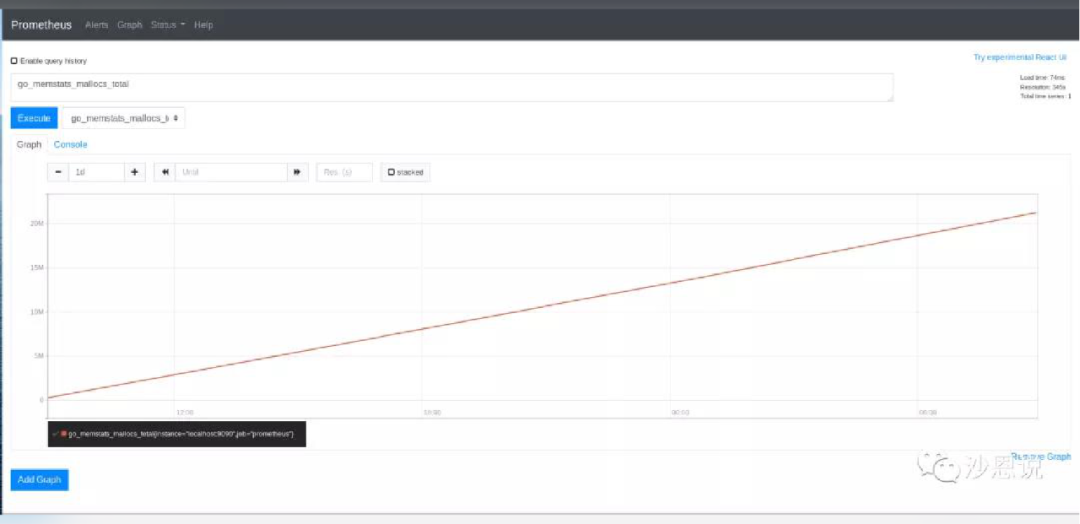
Prometheus 的界面相对比较基础,提供类似 SQL 的查询界面,可以简单查询某些指标。大家更常用的是 Grafana 作为 Prometheus 的前端。
Zabbix 本身也可以把 Grafana 作为前端,但就原生的 UI 进行对比,Prometheus 稍微简单了点。
Zabbix 架构图如下:
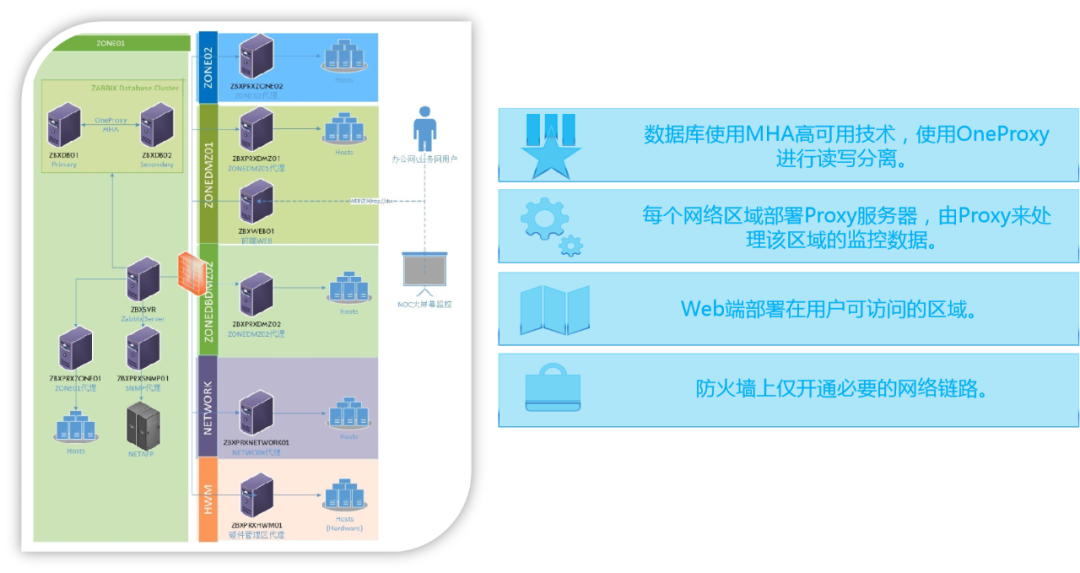
同时 Zabbix Proxy 会和 Zabbix Server 打通,把收集到的数据提供给 Zabbix Server 进行后续处理,比如触发告警。
我们也会把 Web 端部署在一个用户可以访问的区域,这样做的好处是用户可以在正常的办公环境而不是机房中访问 Zabbix。
对于 Zabbix 使用的数据库,使用 one proxy 或者 mycat 方式,能够提高它的高可用性,同时也确保数据库的主从分离。
这种架构的好处在于从库作为读库提供给其他系统访问,比如 CMDB 或者报表系统,同时不会影响主库的性能。
Prometheus 架构图如下:
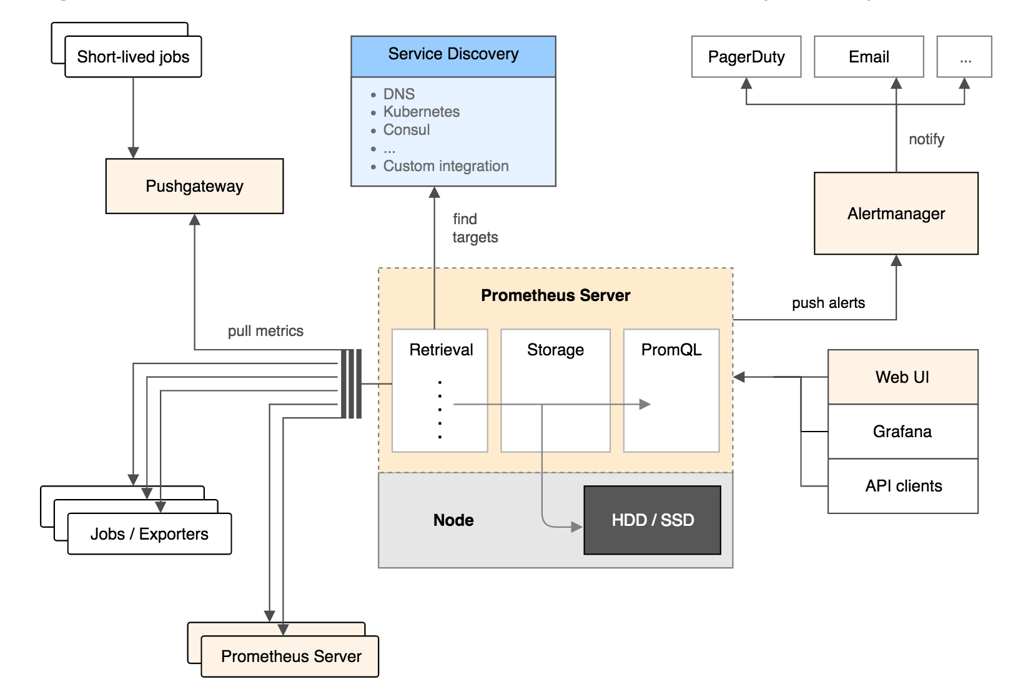
-
Prometheus 使用各种 Exporter 进行监控,Exporter 的功能类似于 Zabbix 的 Agent,负责收集监控对象端的数据。
-
Prometheus 的 AlertManager 类似于 Zabbix 的 Action,可以进行报警触发,比如发送短信和邮件。
存在不同的一点是:Prometheus 使用的数据库是 TSDB 时序数据库,Zabbix 使用的是 MySQL 或者 PgSQL 的关系型数据库。
TSDB 在存储监控的性能会优于传统关系型数据库,因此 Zabbix 也开始尝试性的支持 TSDB 作为后端的数据存储。
而 Zabbix 本身不仅开源,而且不存在商业版和社区版之分,官方保持着定期版本更新的频率,在每一个新版本中也会修复问题或改善用户体验。
同时,Zabbix 除了原厂团队以外,也会有社区的支持,在中国也有活跃的用户社区,以及每年定期的 Zabbix 大会等活动。
低级别发现:低级别发现能帮助我们发现一台设备上所有的监控对象。
试想一个场景,我们有 100 台服务器,每台服务器上至少有 2 块硬盘,最多有 20 块硬盘。
如果我们要监控这些磁盘的 IOPS、剩余磁盘空间 1、磁盘队列长度等 10 个指标,需要怎么去添加监控?
常规的做法是,我在每 1 台服务器上,根据服务器实际的磁盘数量,为每一块磁盘添加监控,如果平均每台 10 块磁盘,那么就是要增加 100*10*10 个监控项,总计 10000 个监控项。
不止于此,还要继续为这 10000 个监控项配置触发器和告警规则。
而在 Zabbix 中,我们只需创建一个模版,定义低级别发现的规则,并将这个模版同这 100 台需要监控的服务器关联即可。
Zabbix 会根据服务器上实际的磁盘数量自动生成对应的监控项,大大提升了添加监控的效率,同时也减少了手动添加监控的纰漏。
全栈级监控:就像刚才所介绍的,Zabbix 在监控的广度和深度之间做了一个比较好的权衡,它是一个全栈级的监控平台。
从底层的硬件、操作系统、中间件、数据库,到上层的应用、业务,都可以纳入到 Zabbix 的监控范围中。
Zabbix 全栈自动化监控实践案例
分布式自动化监控
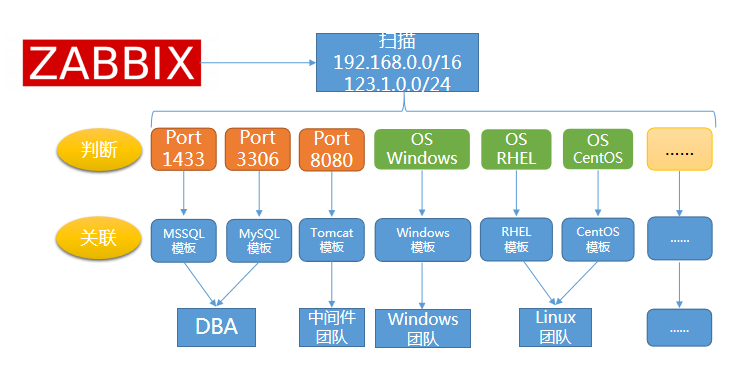
因此,我们通过已经配置好的规则,将发现的这个开放着 1433 端口的 IP 和 SQLServer 模版进行关联。
SQLServer 的模版是我们预先定制好的对于微软数据库的监控模版,通过自动发现,我们能达到两个目的:
-
所有的微软数据库都被监控到了。
-
所有被监控的数据库使用了同一套监控基线,实现了标准化监控。
同样的,我们也可以通过定制不同的规则,来添加不同类型的监控,比如 3306 是 MySQL 的监控等。
除了关联模版,我们会把监控对象添加到不同的组中,确保每个组关联了对应的运维人员。
这样做的好处在于,我们不需要频繁的更新告警策略,而当故障发生的时候,对应的管理员也能第一时间收到告警。
双维度管理(平台维度/业务维度)
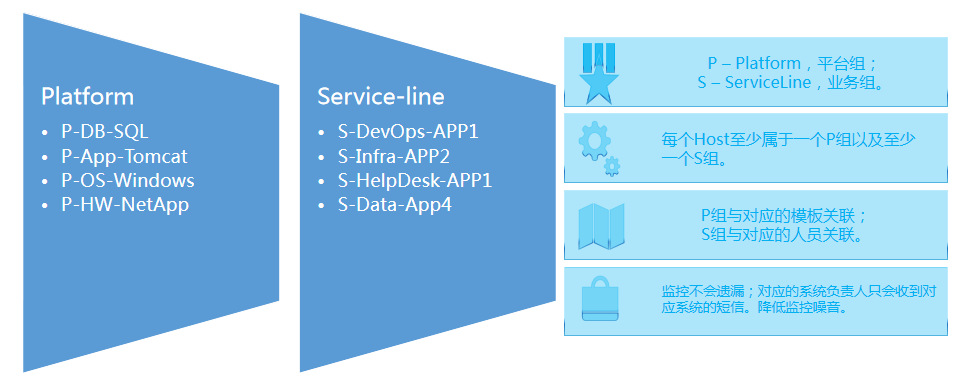
DBA 会负责所有数据库相关的运维工作,而且不在乎这个数据库属于那个应用系统。
因此所有的数据库服务器,比如所有的 MySQL,都会放到一个叫做 P-DB-MySQL 的组中。
这个组所有的告警会发送给指定的 DBA 而不是 Windows 管理员,同时会和对应的 MySQL 监控模版进行关联。
这样做的收益在于 DBA 只会收到他们所负责系统的告警,同时监控也实现了标准化。
而业务人员关注的是整体业务应用是否正常运行。比如一个登陆系统,它可能有前端的 Tomcat 中间件,还有一台 MySQL 存放着用户登录信息,底层跑着一台 HP 的服务器。
那么我们会把这三个监控对象放在一个叫做 S-Department1-Login 的组中。
这样做的好处在于,一旦一个监控对象出现任何问题,我们可以第一时间知道它影响什么系统。
告警方式

Zabbix 支持非常多的告警方式,这点类似于 Prometheus 的 AlertManager。
首先我们会对报警进行分级,Zabbix 原生提供了 5 种级别的告警,即 Disaster,High,Warning,Average 和 Info。
我们使用了其中的三种,并给出了这三种级别告警的定义:
-
Disaster:触发后需要立即处理,如不处理会直接影响生产系统的告警。
-
Warning:触发后需要尽快处理,短期不处理不会直接影响生产系统。
-
Info:提示性的告警。
不同级别的报警会对应不同的策略,比如 Disaster 告警会发送给 IT 负责人和系统管理员;Warning 告警只会发送给系统管理员;Info 不会发送告警,但会在监控大屏上展现。
具体的告警分级和策略可以根据企业内部的实际情况和监控需求进行定制。
持续集成/持续交付
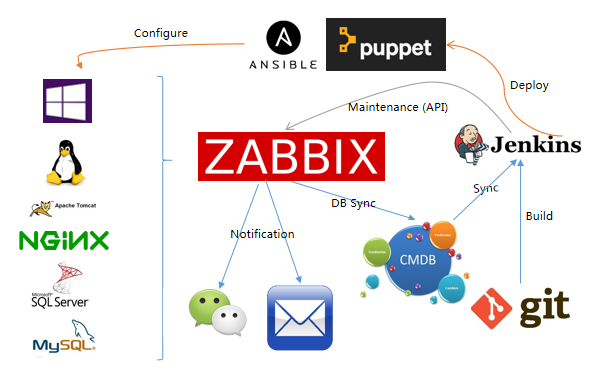
自动化带外管理
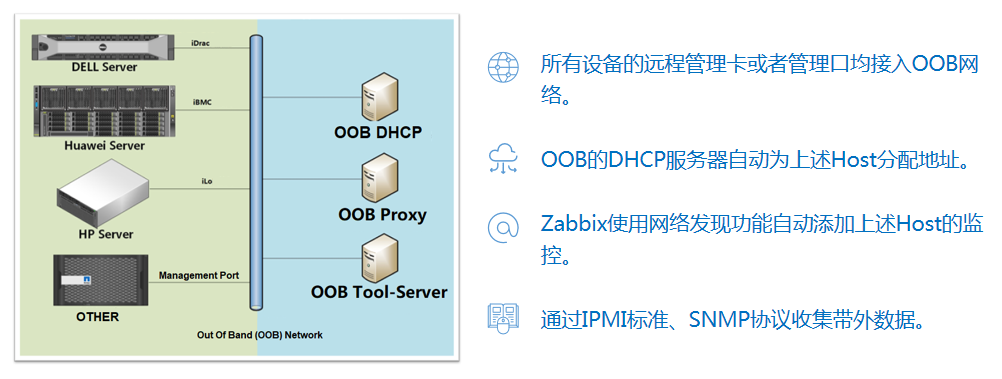
当一个机房里面有多种服务器的时候,如果只是依靠这些平台,除了昂贵的 License 授权,管理成本也非常高昂。
即使这些问题解决了,那么那些只支持 SNMP 的网络设备、存储怎么办呢?
-
我们将 Zabbix 部署在带外管理网络中,这个网络会有一台 DHCP 服务器自动为所有的设备分配 IP 地址。
-
Zabbix 在这个带外网络中会有一台 Proxy 代理服务器,通过 Zabbix 的自动发现功能,将所有的带外地址增加到 Zabbix 中;通过 IPMI 或者 SNMP 的标准协议套用监控模版,实现统一监控。
-
收集到的带外数据可以作为 CMDB 配置管理数据库中重要的硬件信息。
总结
如何选择监控平台
如果我们只是在 Prometheus 和 Zabbix 中选择,应该如何选择一个合适的监控平台?

-
当环境是一个纯容器的环境,毫无疑问 Prometheus 是更适合的选择,Prometheus 是天生为容器化平台打造的监控系统。
-
而当我们环境很复杂,有各种操作系统、硬件、中间件、数据库等,那么 Zabbix 是更适合的监控平台,Zabbix 兼顾了监控的深度和广度,实现了统一监控平台的目的。
-
当整个环境中又有容器、又有其他的系统,而又希望之用一套监控系统,那么 Zabbix 更合适,因为 Zabbix 的最新版本中已经强化了容器化监控的功能。
-
当然,有余力的话,也可以使用两台监控系统互相补足。
使用 Zabbix 的收益

Zabbix 有简单易用的 UI,自带的 Graph 和 Screen 也可以满足企业级的展现需求。
90% 以上的配置可以通过 Web 端统一操作和实现,这一点比强依赖于配置文件的 Prometheus 要更为方便。
当然,如果对于 Zabbix 的原生 UI 不满意,仍然可以和 Prometheus 一样,接入 Grafana,大大降低了二次开发的成本。
基于平台组和业务组的双维度分组,也使得 Zabbix 可以在同一组织内为不同团队提供更个性化的展现。
Zabbix 的开源、免费等特性使得越来越多的企业,尤其是自研能力不是那么强的中小企业快速实现全栈级监控。
Zabbix 几乎可以覆盖 80% 甚至更多的监控需求,它的高级特性也大大减少了人工介入,提升了自动化能力,并可以其他系统和平台进行持续集成。
目前 Zabbix 的社区非常活跃,拥有丰富的学习资源,大大降低了学习成本。
也欢迎大家积极反馈在使用 Zabbix 中碰到的问题或者改善建议给到我或者 Zabbix 社区,我们也希望通过不断的迭代和优化使其成为更加优秀的监控平台。
作者:蔡翔华。出处:公众号 DBAplus社群(ID:dbaplus)


当当1024图书优惠活动,“实付满200再减40”的优惠码「J2KNAE」,囤书薅羊毛再走一波~~(使用时间:10月20日~11月3日,使用渠道:当当小程序或当当APP)
-
原创|OpenAPI标准规范
-
如此简单| ES最全详细使用教程
-
ClickHouse到底是什么?为什么如此牛逼!
-
原来ElasticSearch还可以这么理解
-
面试官:InnoDB中一棵B+树可以存放多少行数据?

文章评论