
下面就来详细讲解如何一步步操作,文末附完整代码。
Selenium介绍
Selenium是一个用于web应用程序自动化测试的工具,直接运行在浏览器当中,可以通过代码控制与页面上元素进行交互,并获取对应的信息。Selenium很大的一个优点是:不需要复杂地构造请求,访问参数跟使用浏览器的正常用户一模一样,访问行为也相对更像正常用户,不容易被反爬虫策略命中,所见即所得。而且在抓取的过程中,必要时还可人工干预(比如登录、输入验证码等)。
Selenium常常是面对一个严格反爬网站无从入手时的保留武器。当然也有缺点:操作均需要等待页面加载完毕后才可以继续进行,所以速度要慢,效率不高(某些情况下使用headless和无图模式会提高一点效率)。
需求分析和代码实现
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 导入第2-4行是为了马上会提到的 显式等待
import time
import datetime
driver = webdriver.Chrome()
driver.get('https://weixin.sogou.com/')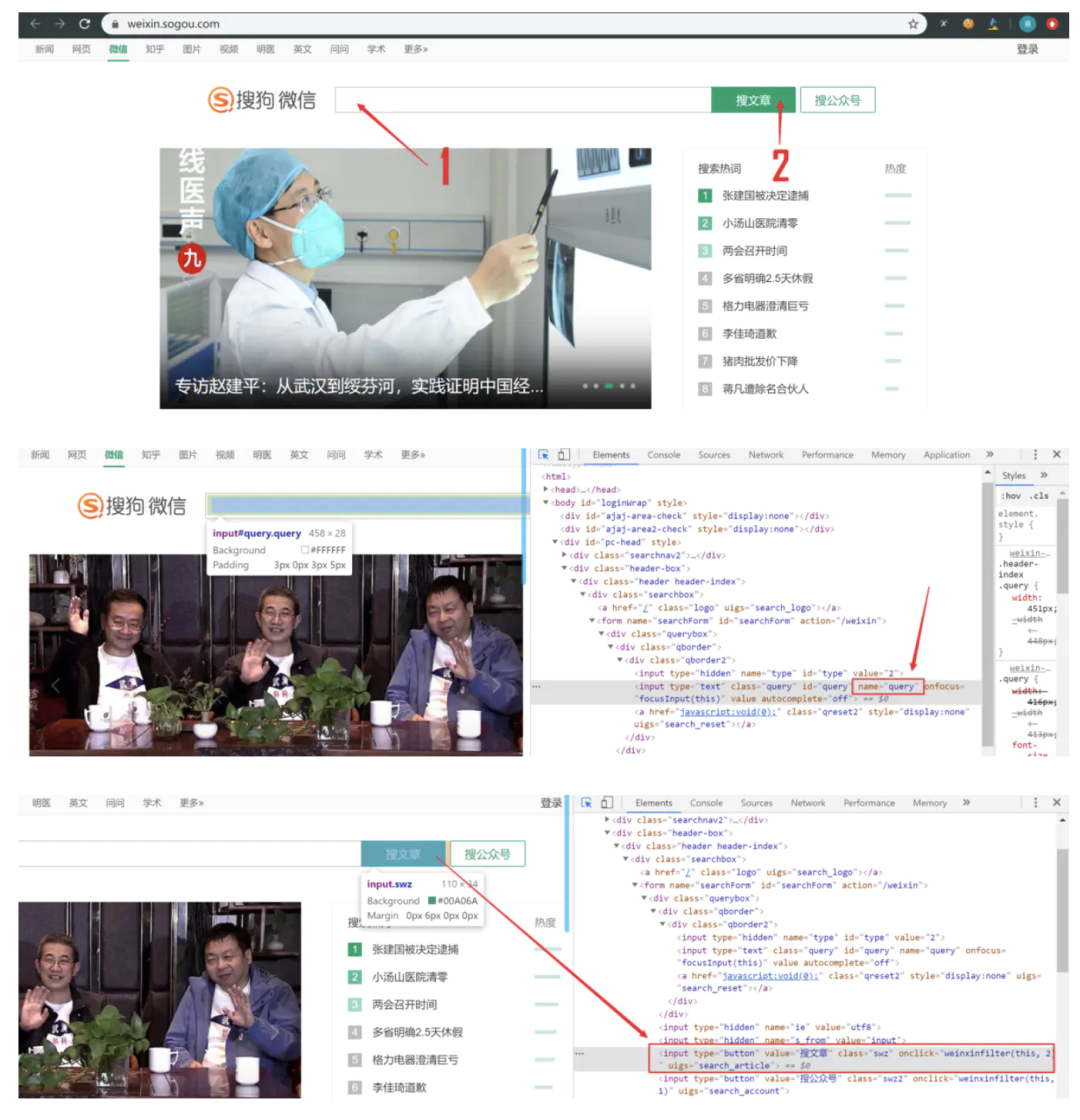
wait = WebDriverWait(driver, 10)
input = wait.until(EC.presence_of_element_located((By.NAME, 'query')))
input.send_keys('早起Python')
driver.find_element_by_xpath("//input[@class='swz']").click()driver.implicitly_wait(10),显示等待明确了等待条件,只有该条件触发,才执行后续代码,如这里我用到的代码,当然也可以用time模块之间设定睡眠时间,睡完了再运行后续代码。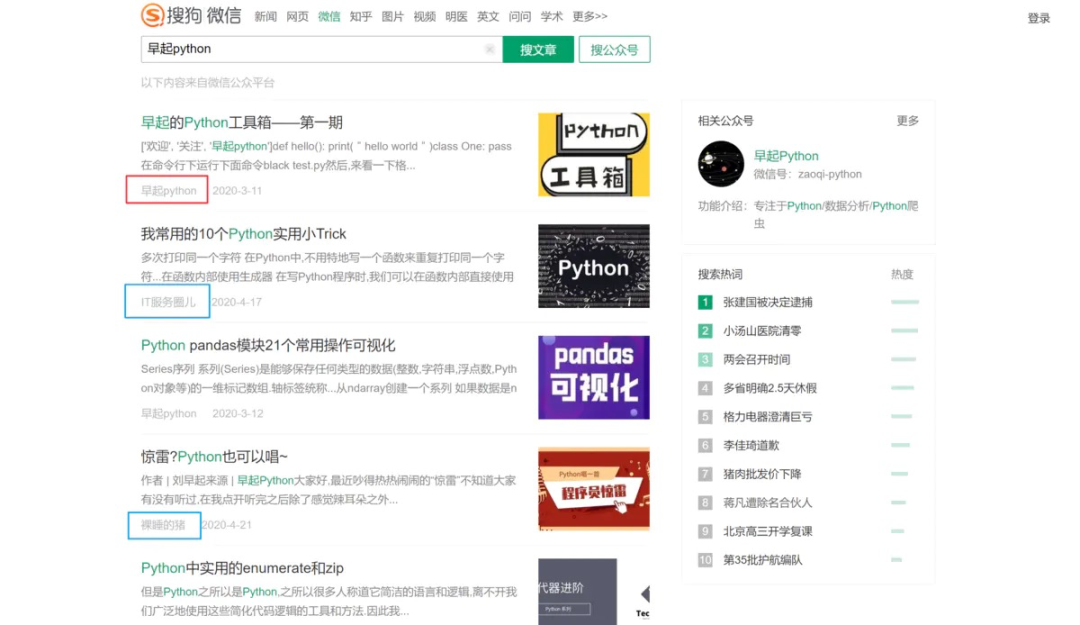
另外只能获取前10页100条的结果,查看后续页面需要微信扫码登录:

因此从这里开始,代码的执行逻辑为:
-
先遍历前10页100个文章的作者名字,如果不是“早起Python”则跳过,是则获取对应的标题名字、发布日期和链接
-
第10页遍历完成后自动点击登录,此时需要人工介入,扫码完成登录
-
代码检测登录是否完成(可以简化为识别“下一页”按钮是否出现),如果登录完成则继续从11页遍历到最后一页(没有“下一页”按钮)
由于涉及两次遍历则可以将解析信息包装成函数:
num = 0
def get_news():
global num # 放全局变量是为了给符合条件的文章记序
time.sleep(1)
news_lst = driver.find_elements_by_xpath("//li[contains(@id,'sogou_vr_11002601_box')]")
for news in news_lst:
# 获取公众号来源
source = news.find_elements_by_xpath('div[2]/div/a')[0].text
if '早起' not in source:
continue
num += 1
# 获取文章标题
title = news.find_elements_by_xpath('div[2]/h3/a')[0].text
# 获取文章发表日期
date = news.find_elements_by_xpath('div[2]/div/span')[0].text
# 文章发表的日期如果较近可能会显示“1天前” “12小时前” “30分钟前”
# 这里可以用`datetime`模块根据时间差求出具体时间
# 然后解析为`YYYY-MM-DD`格式
if '前' in date:
today = datetime.datetime.today()
if '天' in date:
delta = datetime.timedelta(days=int(date[0]))
elif '小时' in date:
delta = datetime.timedelta(hours=int(date.replace('小时前', ' ')))
else:
delta = datetime.timedelta(minutes=int(date.replace('分钟前', ' ')))
date = str((today - delta).strftime('%Y-%m-%d'))
date = datetime.datetime.strptime(date, '%Y-%m-%d').strftime('%Y-%m-%d')
# 获取url
url = news.find_elements_by_xpath('div[2]/h3/a')[0].get_attribute('href')
print(num, title, date)
print(url)
print('-' * 10)
for i in range(10):
get_news()
if i == 9:
# 如果遍历到第十页则跳出循环不需要点击“下一页”
break
driver.find_element_by_id("sogou_next").click()接下来就是点击“登录”,然后人工完成扫码,可以利用while True检测登录是否成功,是否出现了下一页按钮,如果出现则跳出循环,点击“下一页”按钮并继续后面的代码,否则睡3秒后重复检测:
driver.find_element_by_name('top_login').click()
while True:
try:
next_page = driver.find_element_by_id("sogou_next")
break
except:
time.sleep(3)
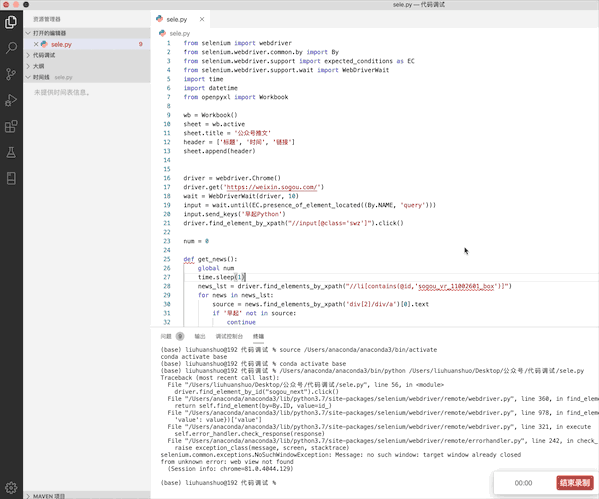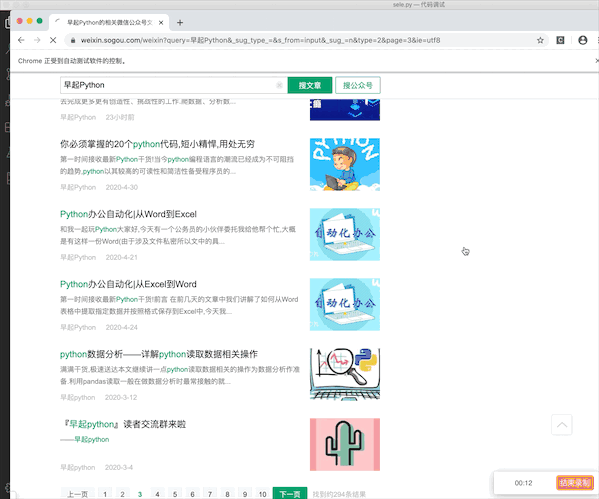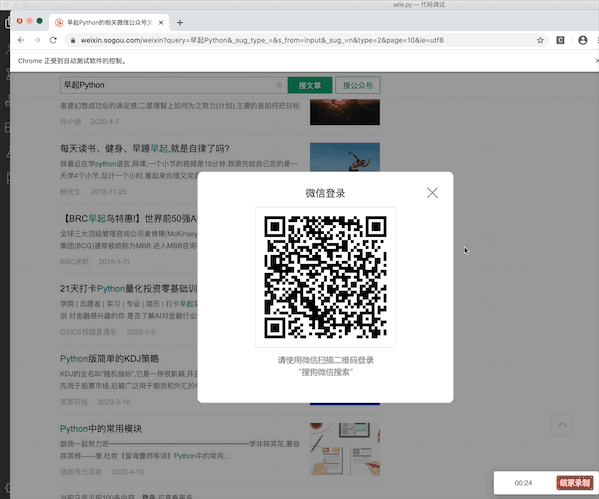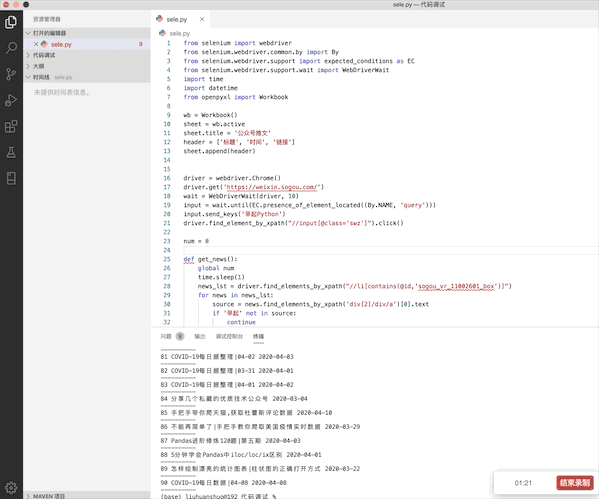
next_page.click()效果如图:
然后就是重新遍历文章了,由于不知道最后一页是第几页可以使用while循环反复调用解析页面的函数半点击“下一页”,如果不存在下一页则结束循环:
while True:
get_news()
try:
driver.find_element_by_id("sogou_next").click()
except:
break
# 最后退出浏览器即可
driver.quit()是不是少了点什么?对,就是数据存储,在爬下来数据之后和之前一样利用openpyxl存储到excel中即可(如果不想用此模块的话也可以改用 csv 或者 pandas 保存表格文件):

作者:陈熹
来源:早起Python
_往期文章推荐_


文章评论