 图雀社区推荐搜索
图雀社区推荐搜索
在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息;
在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息;
今天我们要讲的是,如何抓取多个网页里的多类信息。
这次的抓取是在简易数据分析 05的基础上进行的,所以我们一开始就解决了抓取多个网页的问题,下面全力解决如何抓取多类信息就可以了。
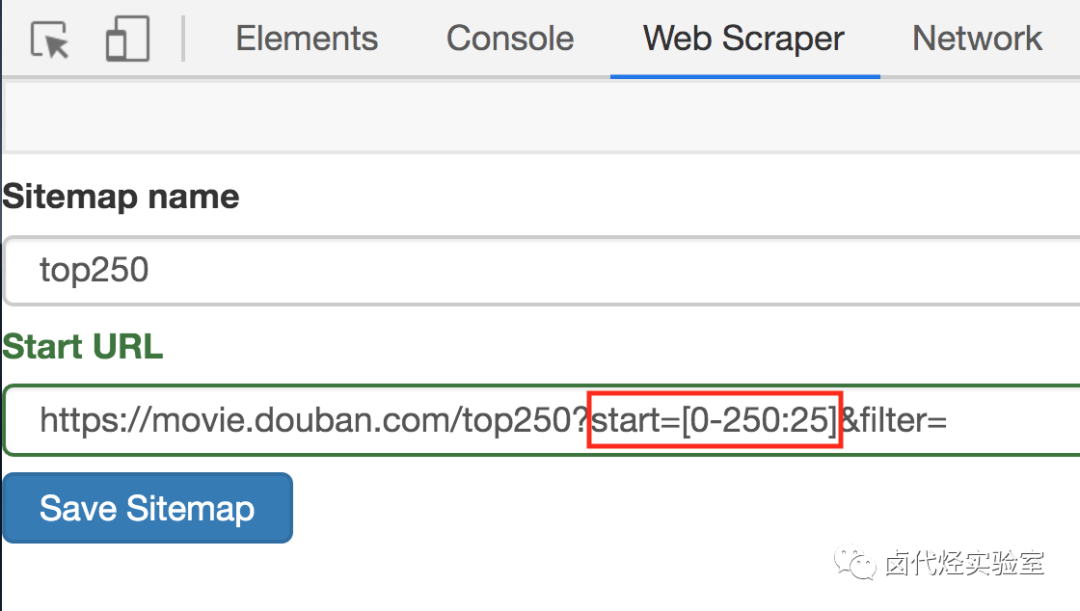
我们在实操前先把逻辑理清:
上几篇只抓取了一类元素:电影名字。这期我们要抓取多类元素:排名,电影名,评分和一句话影评。
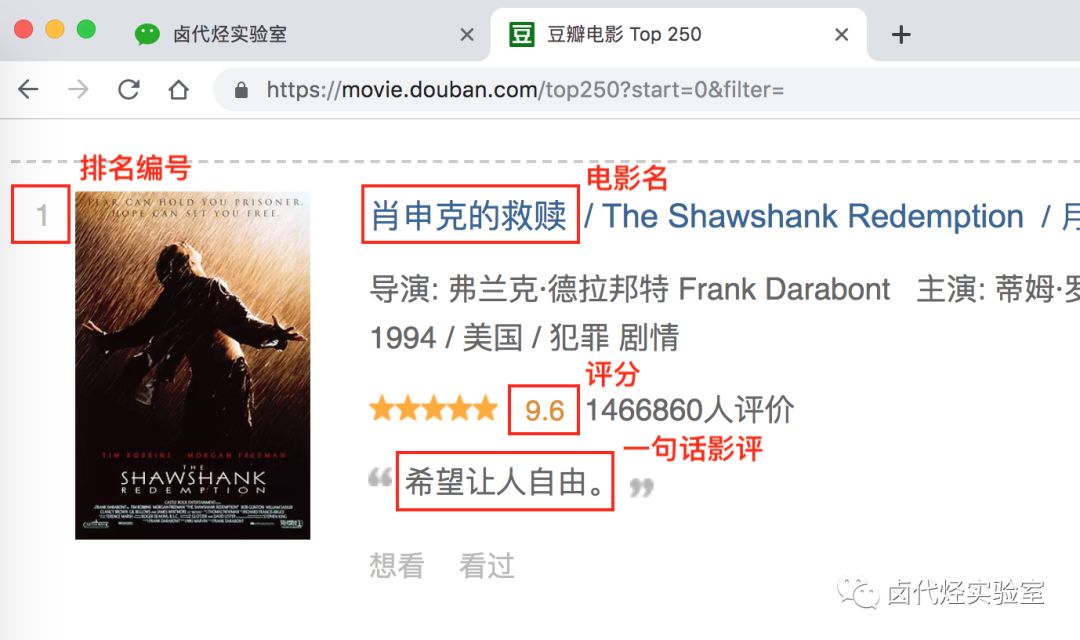
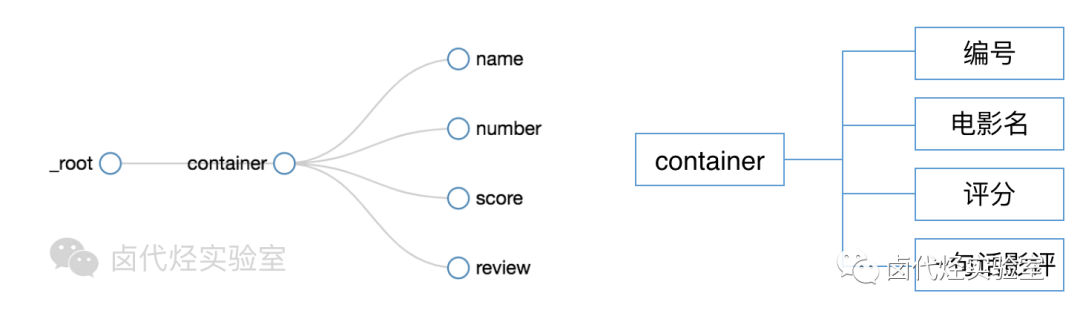
根据 Web Scraper 的特性,想抓取多类数据,首先要抓取包裹多类数据的容器,然后再选择容器里的数据,这样才能正确的抓取。我画一张图演示一下:
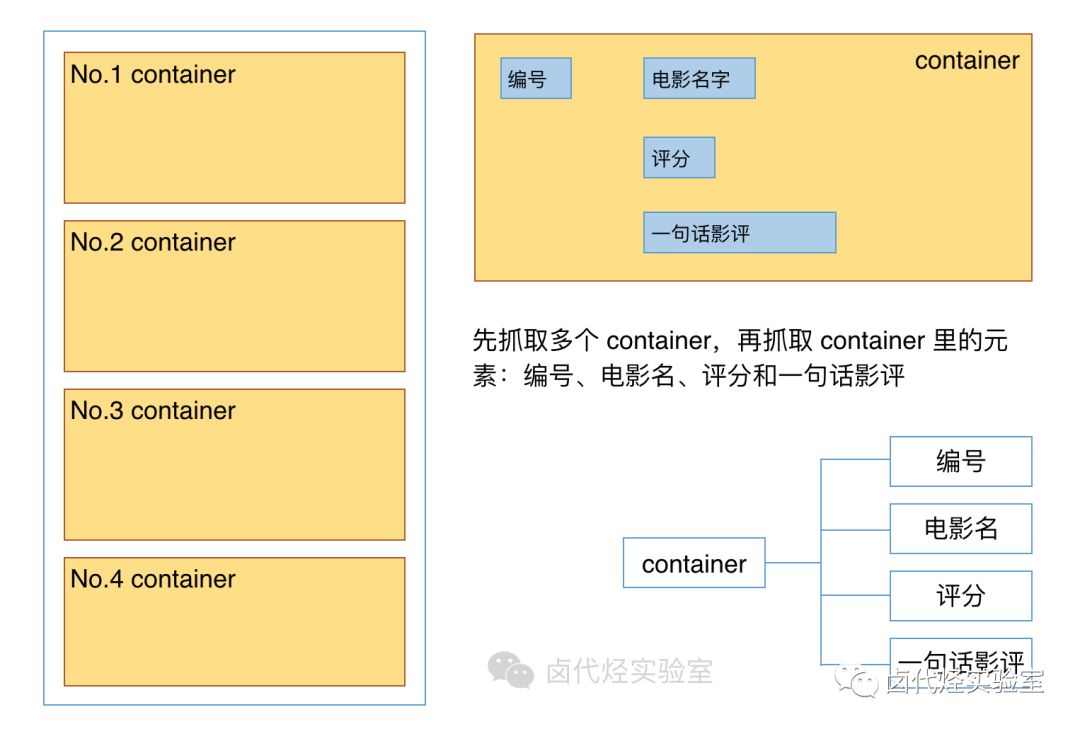
我们首先要抓取多个 container(容器),再抓取 container 里的元素:编号、电影名、评分和一句话影评,当爬虫运行完后,我们就会成功抓取数据。
概念上搞清楚了,我们就可以讲实际操作了。
如果对以下的操作有疑问,可以看 简易数据分析 04 的内容,那篇文章详细图解了如何用 Web Scraper 选择元素的操作
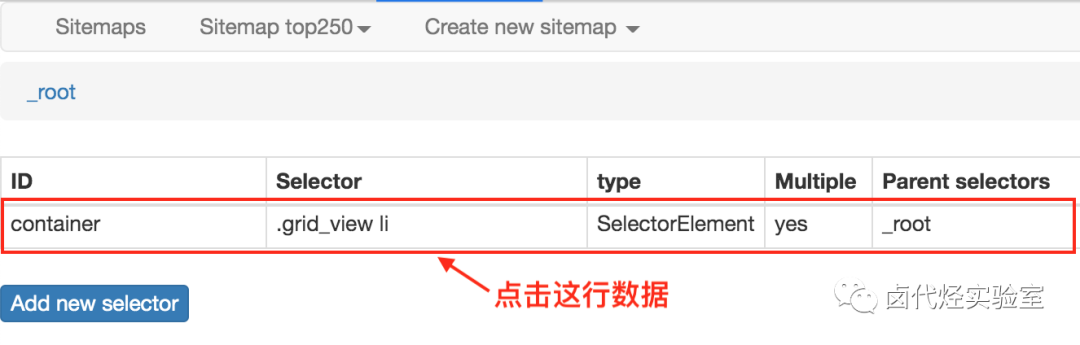
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据

2.删除掉旧的 selector,点击 Add new selector 增加一个新的 selector
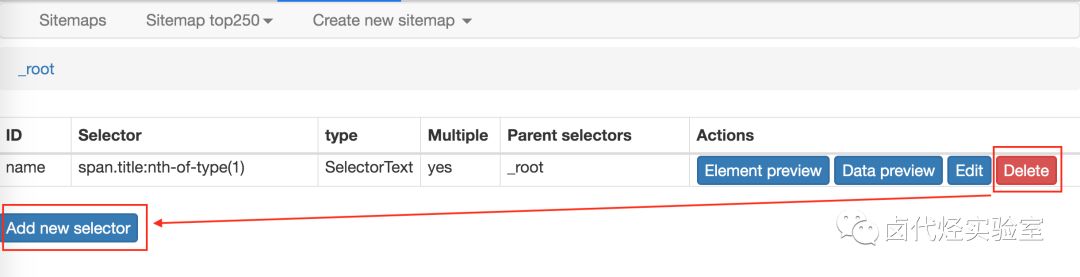
3.在新的 selector 内,注意把 Type 类型改为 Element(元素),因为在 Web Scraper 里,只有元素类型才能包含多个内容。
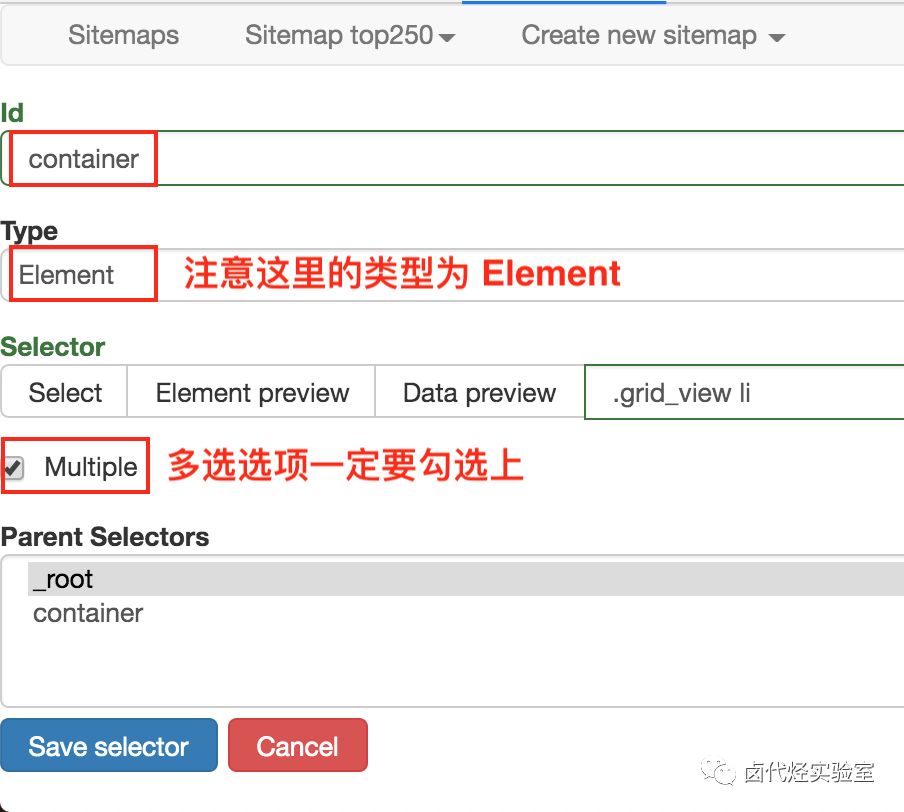
我们勾选的元素区域如下图所示,确认无误后点击 Save selector 按钮,就会回退到上一个操作面板。
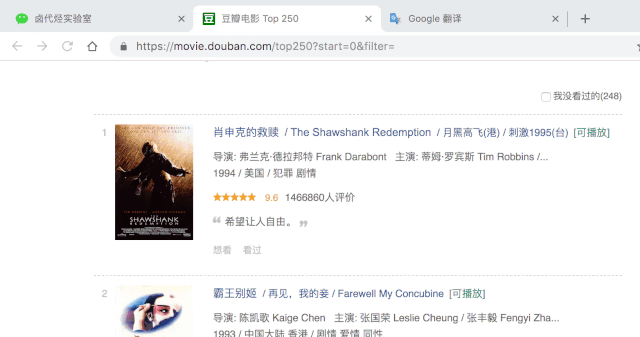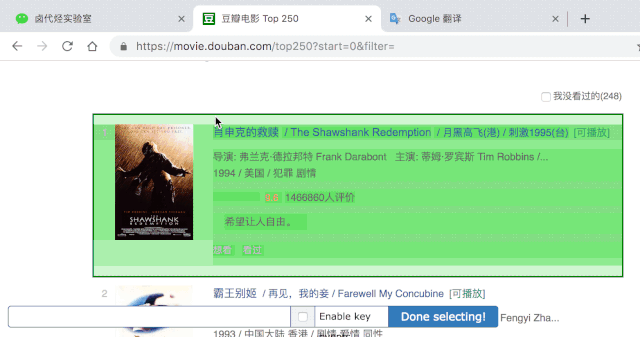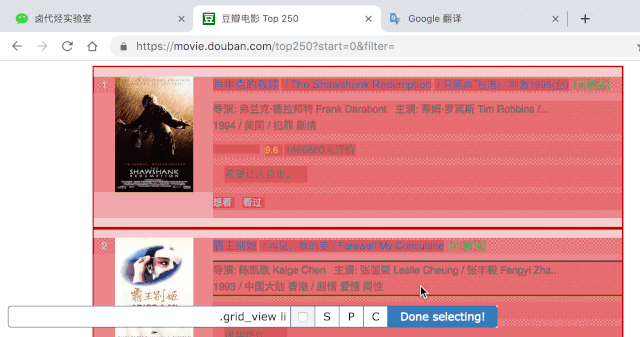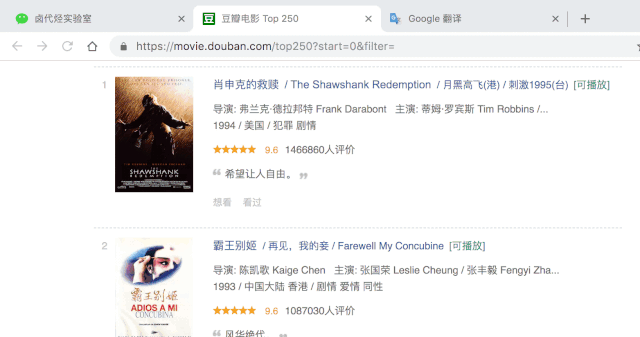
在新的面板里,点击刚刚创建的 selector 那行数据:
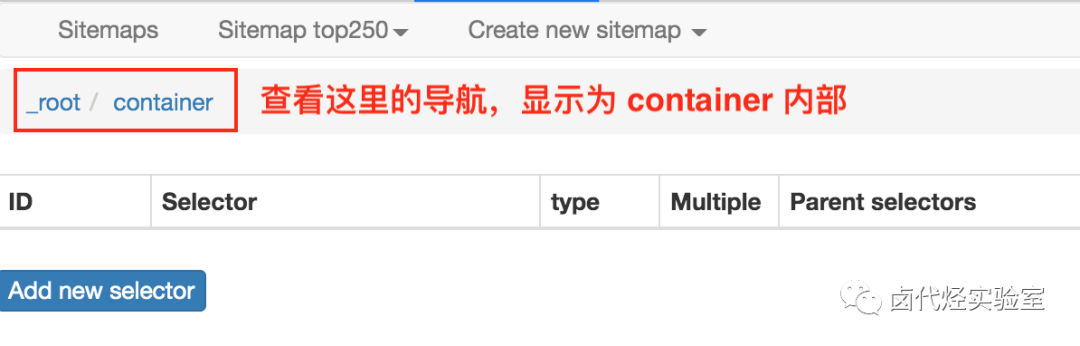
点击后我们就会进入一个新的面板,根据导航我们可知在 container 内部。
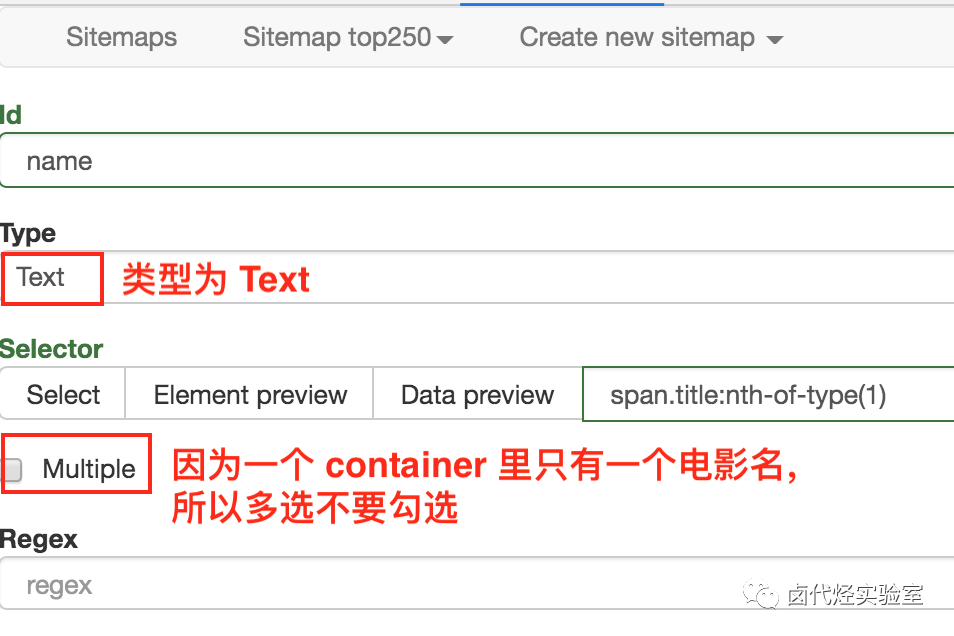
在新的面板里,我们点击 Add new selector ,新建一个 selector,用来抓取电影名,类型为 Text,值得注意的是,因为我们是在 container 内选择文字的,一个 container 内只有一个电影名,所以多选不要勾选,要不然会抓取失败。
选择电影名的时候你会发现 container 黄色高亮,我们就在黄色的区域里选择电影名就好了。
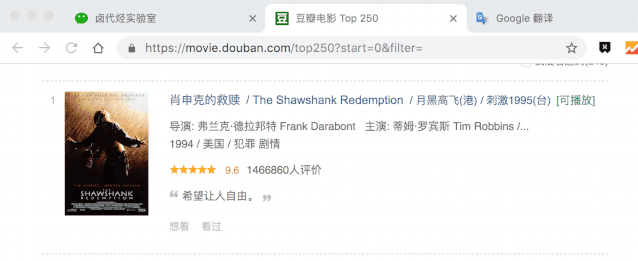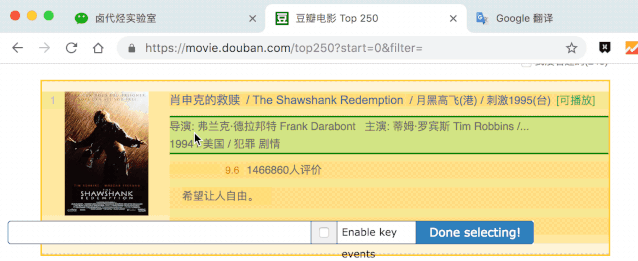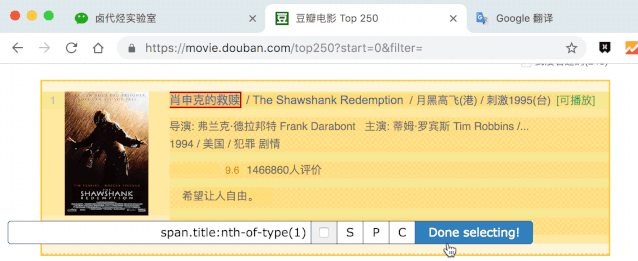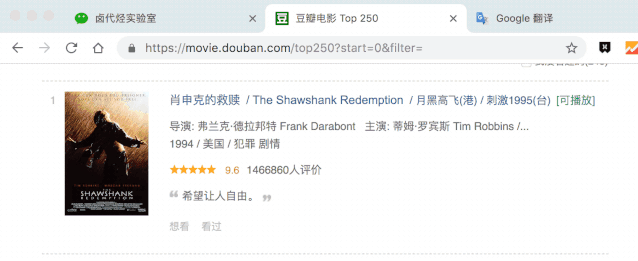
点击 Save selector 保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评,因为操作和上面一模一样,我这里就省略讲解了。
排名编号:
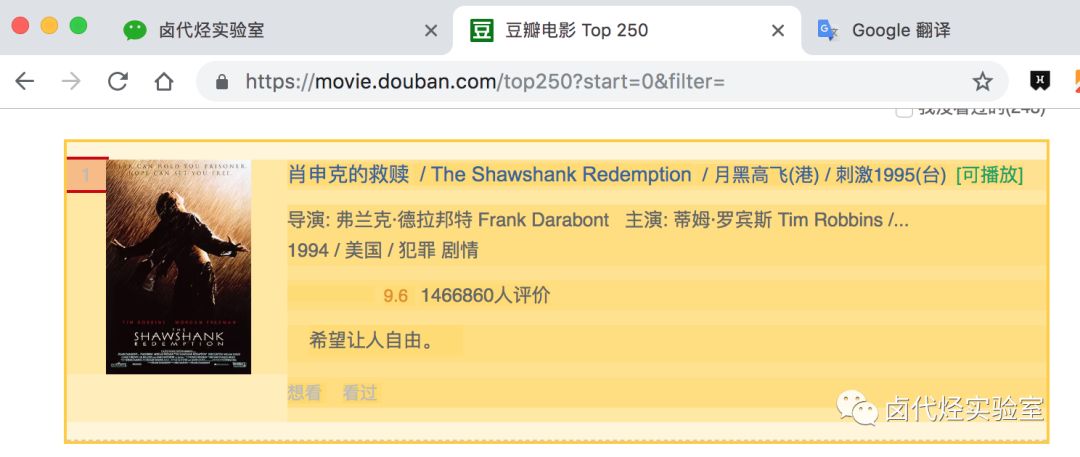
评分:
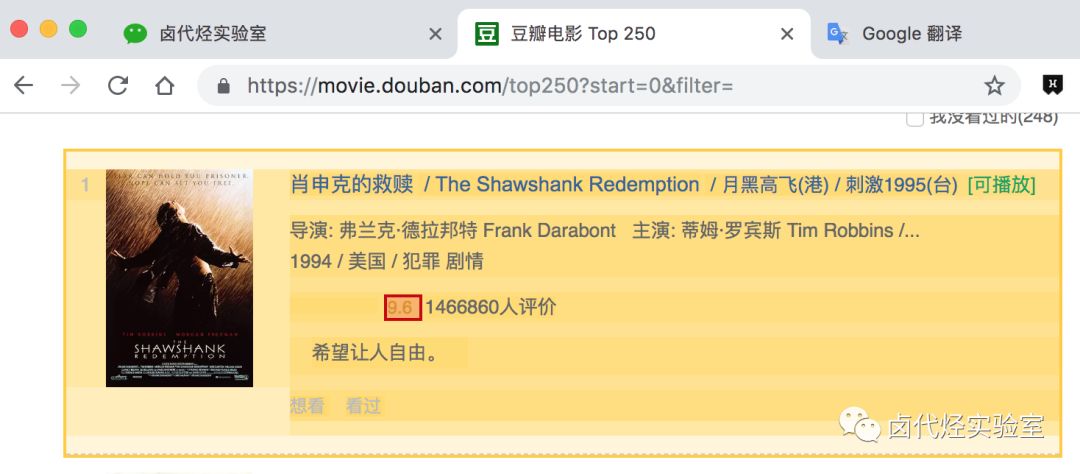
一句话影评:
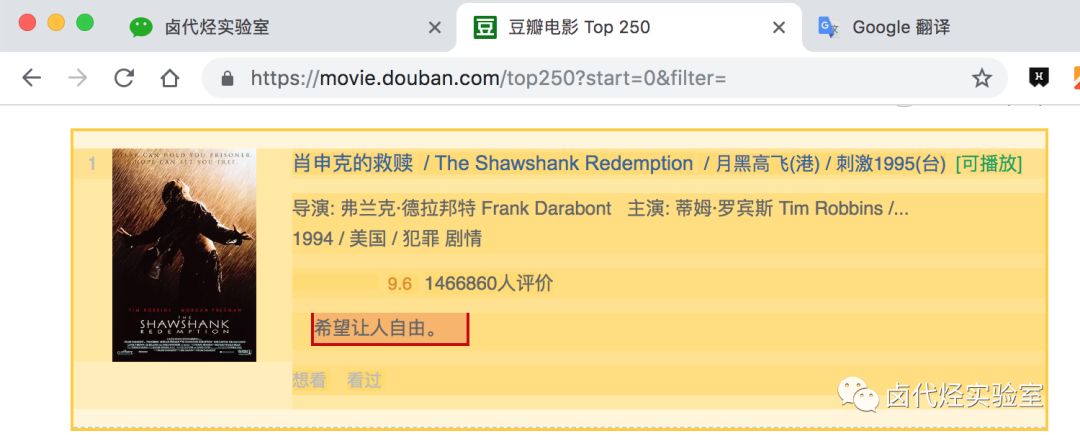
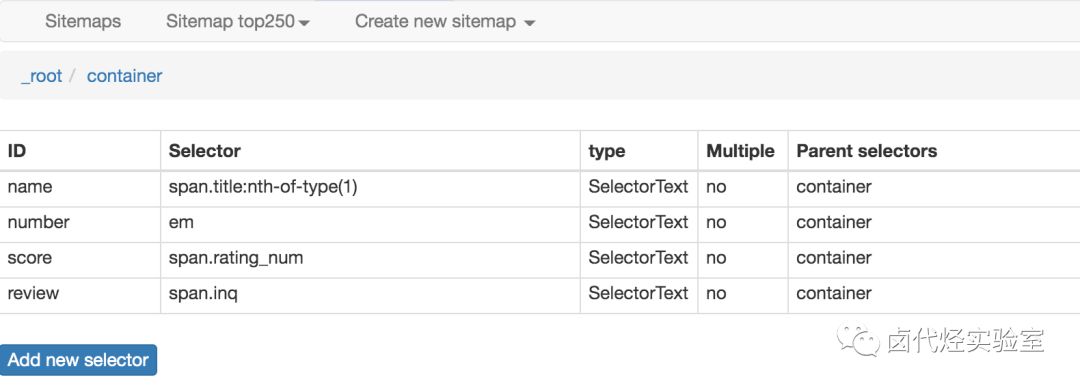
我们可以在面板里观察我们选择的多个元素,一共有四个元素:分别为 name、number、score 和 review,类型都是 Text,不需要多选,父选择器都是 container。
我们可以点击 Stiemap top250 下的 selector graph,查看我们爬虫选择元素的层级关系,确认正确后我们再点击 Stiemap top250 下的 Selectors,回到选择器展示面板。
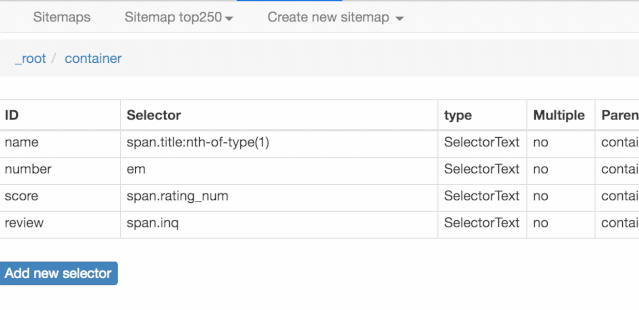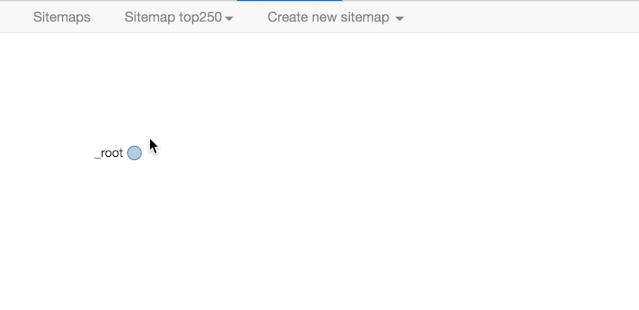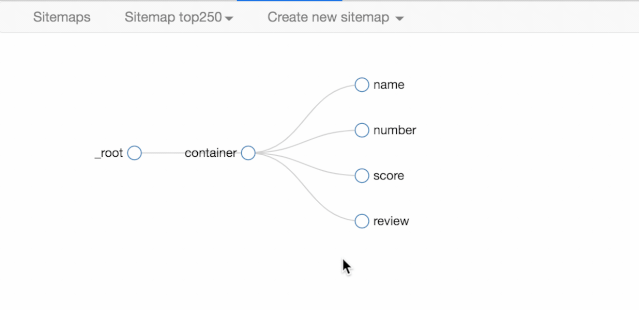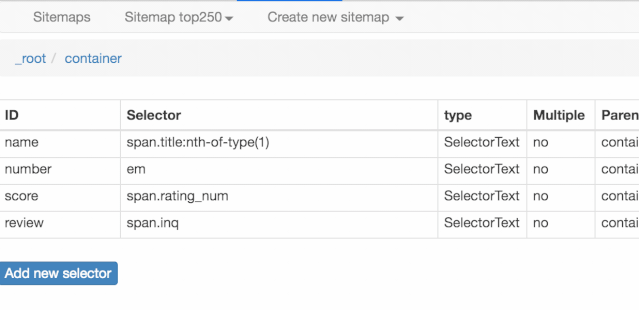
下图就是我们这次爬虫的层级关系,是不是和我们之前理论分析的一样?
确认选择无误后,我们就可以抓取数据了,操作在 简易数据分析 04 、 简易数据分析 05 里都说过了,忘记的朋友可以看旧文回顾一下。下图是我抓取的数据:
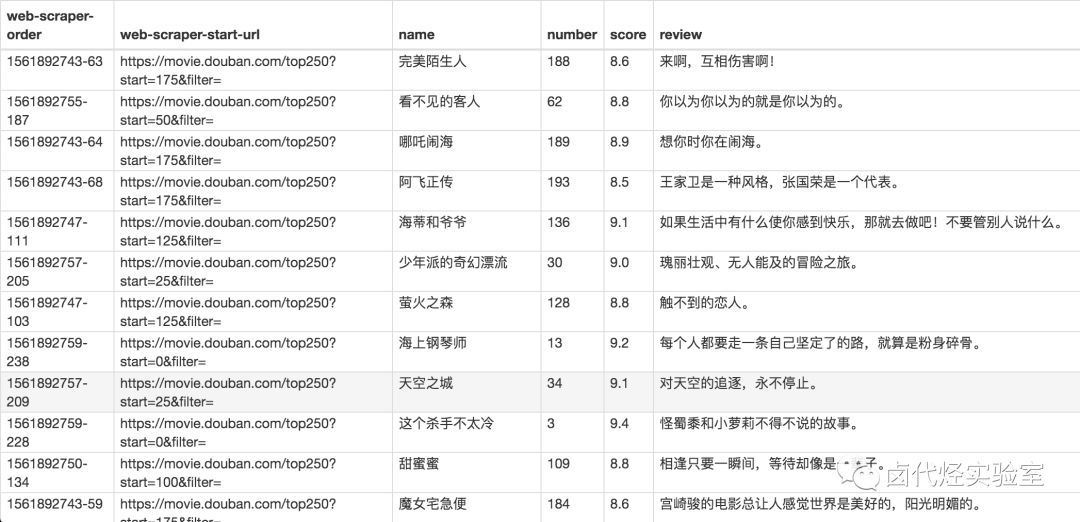
还是和以前一样,数据是乱序的,不过这个不要紧,因为排序属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
今天的内容其实还是比较多的,大家可以先消化一下,下一篇我们讲讲,如何抓取点击「加载更多」加载数据的网页内容。
Sitemap 分享:
这次的 sitemap 就分享给大家,大家可以导入到 Web Scraper 中进行实验,具体方法可以看我上一篇教程。
Sitemap:
{"id":"top250","startUrl":["https://movie.douban.com/top250?start=[0-250:25]&filter="],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"regex":"","delay":0},{"id":"score","type":"SelectorText","parentSelectors":["container"],"selector":"span.rating_num","multiple":false,"regex":"","delay":0},{"id":"review","type":"SelectorText","parentSelectors":["container"],"selector":"span.inq","multiple":false,"regex":"","delay":0}]}
● 简易数据分析(三):Web Scraper 批量抓取豆瓣数据与导入已有爬虫

·END·
汇聚精彩的免费实战教程

关注公众号回复 z 拉学习交流群
喜欢本文,点个“在看”告诉我


文章评论