

分享嘉宾:陈迪豪 第四范式 架构师
编辑整理:刘璐
出品平台:第四范式天枢、DataFunTalk
-
大规模推荐系统
-
Spark SQL应用与FESQL
-
基于LLVM的Spark优化
-
总结
1. 业界推荐系统的应用

众所周知,推荐系统在业界有着许多成功的应用,据统计,亚马逊40%的销售在推荐系统的作用下产生;Netflix 75%的用户使用推荐系统寻找他们喜爱的视频;30%的用户进行在线购物前会使用关键词搜索他们需要的商品。目前,几乎所有的新闻、搜索、广告、短视频应用都是基于推荐系统建立的。
2. 推荐系统的架构
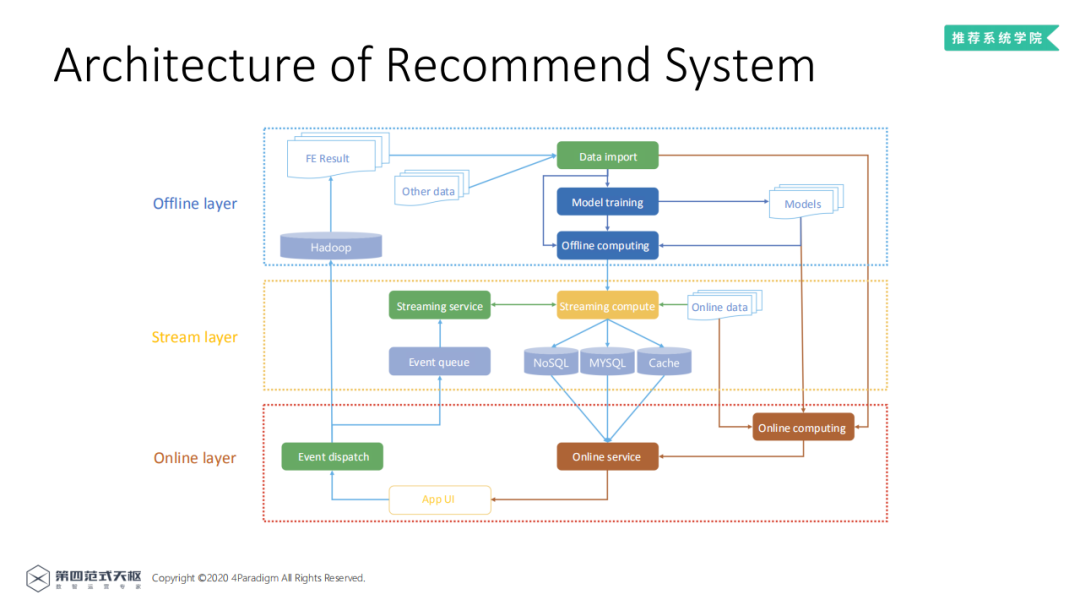
业界成熟的推荐系统架构一般分为三层:离线层 ( offline layer ),近实时的流式层 ( stream layer ) 和在线层 ( online layer ) 三部分。
离线层:一般用于大规模的数据预处理、特征抽取与模型训练,通常用Hadoop HDFS进行数据存储,使用Spark,MapReduce等分布式计算引擎进行特征抽取与计算以及数据管理,再使用离线模型训练框架TensorFlow、Pytorch、MXNet等进行离线的模型训练,模型结果可用于线上预测。
近实时的流式层:主要是为了提升推荐系统的时效性,对于一些时序特征,可以使用消息队列收集近实时的数据,结合流式计算服务如Flink对数据进行补全,把结果存入NoSQL、MySQL等存储服务中,存储结果供线上服务使用。
在线层:用户产生的数据可以通过Flink生成流式特征,也可以使用HDFS进行数据归档。在线预估时从NoSQL或MySQL中提取流式特征,通过离线训练的模型即可进行线上预估。
3. 大规模推荐系统的特征抽取

大规模推荐系统的数据处理通常分为两类:
-
ETL ( Extract, Transform, Load ):进行数据数据补全、格式转换等;
-
特征抽取:对原始数据特征进行处理,得到模型易于学习的样本特征,如离散化,embedding化等方法。
常用工具包括:
-
SQL/Python:针对一般规模的数据,通常可以通过使用SQL/Python进行处理;
-
Hadoop/Spark/Flink:针对大规模数据,通常要借助Hadoop/Spark/Flink等计算框架。
1. Spark简介
Spark 是专为大规模数据处理而设计的快速通用的计算引擎,依托强大的分布式计算能力,在Spark上可以开发机器学习、流式学习等应用。Spark提供了SparkSQL,使其能与SQL、Hive兼容,提供PySpark接口可以让开发者使用Python进行分布式应用开发,提供了MLlib包,可以用于机器学习应用的开发。同时Spark也提供诸如Catalyst/Tungsten等方式的优化。

Spark的优势就在于:计算速度快,能够处理PB级别的数据,分布式计算和自动容错机制,提供便于使用的SQL/Python/R API,同时,Spark提供的机器学习库也可以应用于推荐系统,所以在业界,几乎所有公司都会使用Spark作为离线层数据处理框架。
2. 大规模推荐系统中的Spark应用

以IBM的一个推荐系统开源项目来说明Spark在推荐系统中的应用。首先是数据加载,使用read.csv即可加载本地或HDFS数据。使用select即可进行特征列选择。

然后是对数据进行预处理以及简单的特征抽取,该项目中使用了Spark UDF对字符串进行处理,抽取出其中的年份信息,将年份信息作为特征进行使用。

得到全部特征预处理的结果后即可进行模型训练,可以使用Spark内置机器学习API进行模型训练。训练完成后,模型即可上线进行线上预估。

线上的预估服务需要提供实时计算的预估接口,但是在实践中,Spark并不适合直接用于线上预估。原因有三:
-
Driver-exexutor结构只适合进行批量处理,不适合在线处理
-
Spark的批处理模式不适合提供长时间运行的在线服务,也不能保证低延时的计算效率(Spark 3.0的Hydrogen可以部分支持)
-
RDD接口只适合迭代计算,不适合做实时计算
因此,业界的通常做法是使用Java、C++等后端语言实现在线的预估服务,这就带来了另一个线上特征抽取的一致性问题,由于必须要保证线上线下特征的一致性,所以必须同时开发线上使用的特征处理模块,并人工保证计算结果没有差异。
3. Spark的优缺点

Spark支持大规模数据的批处理,提供标准的SQL接口的优点使其成为离线层数据处理的不二之选,但是,Spark不支持线上服务,不能保证线上线下特征一致性,同时在AI场景下的性能没有经过优化,所以在AI场景下,Spark仍有许多不足。针对这些不足,第四范式开发了FESQL执行引擎。
4. FESQL线上线下一致性执行引擎
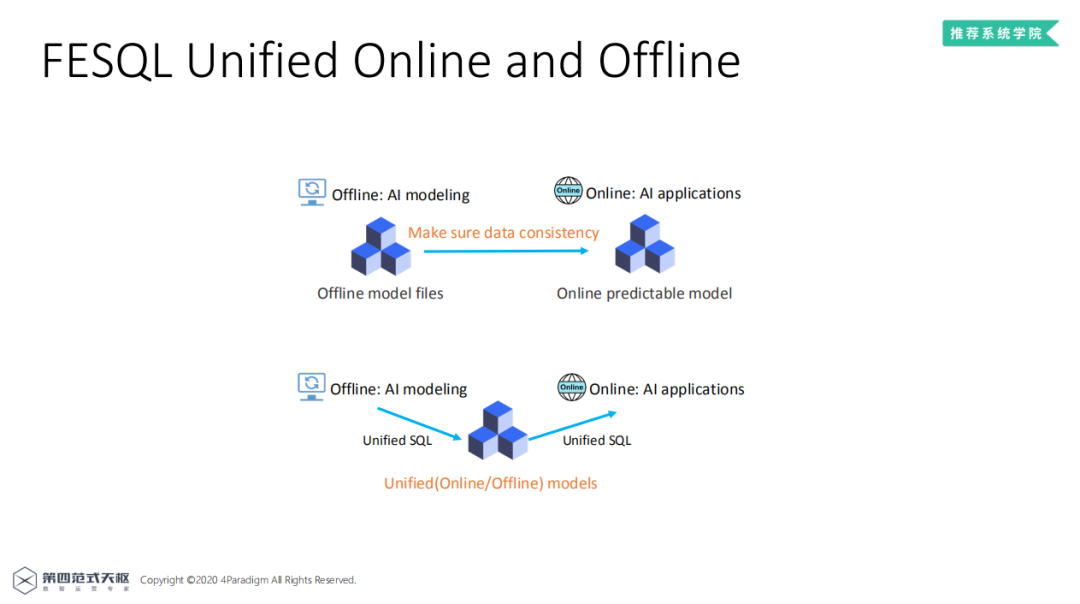
FESQL——保证离线在线特征一致性的SQL执行引擎。上图表示传统的上线过程,生成离线模型文件后,由应用开发者开发线上预估服务,将Spark、SQL中的特征处理逻辑翻译成后端语言代码,实现线上服务,每新增一个特征,都要开发对应的特征抽取模块,同时需要用户和业务开发者保证特征数据的一致性。下图是使用FESQL的上线过程,由于线上线下使用统一的SQL服务进行特征抽取,因而保证了特征在线上和线下的一致性。
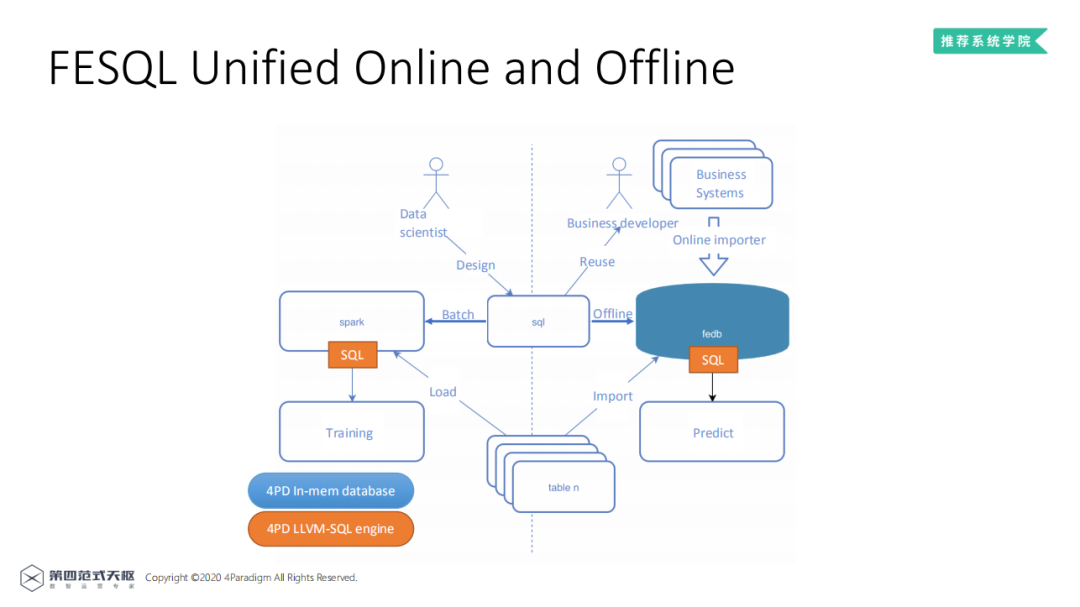
图中所示为FESQL基本框架,左边离线部分和SparkSQL的用法基本一致,由数据科学家设计SQL语句,基于Spark进行离线批处理。橙色框表示第四范式开发的基于LLVM优化的SQL引擎,性能大大优于原生Spark,同时能够更好的支持线上服务,尤其对于SQL语句进行了拓展,使之能够更好的支持机器学习场景下的线上特征处理。其中FEDB是有第四范式开发的全内存数据库,相比于Spark读取HDFS这种高延时的数据载入方式,FEDB可以提前载入模型预估所需数据,效果接近开发的线上特征抽取模块,同时支持时序特征。线上线下的数据一致性由同一套的SQL执行引擎保证。
5. 性能对比
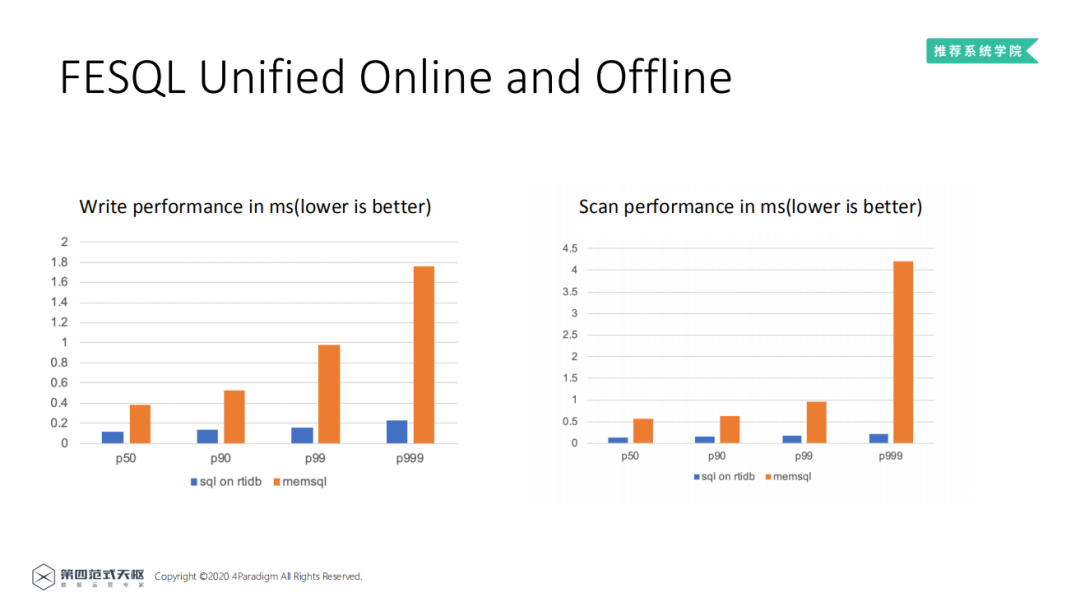
与兼容SQL的全内存数据库memsql的方式进行性能对比可以发现,LLVM优化后的SQL之心引擎在读和写的性能上都要更高。
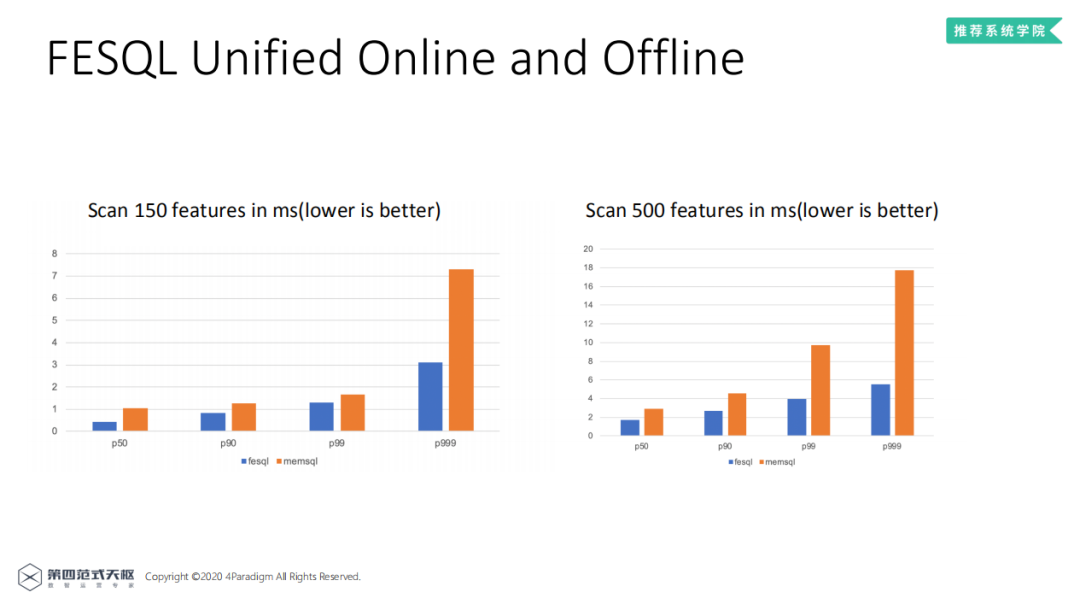
对于机器学习场景下的列聚合 ( 生成时序特征 ) 场景,LLVM优化后的SQL引擎也比memsql快很多,耗时基本小于memsql的50%。
1. Spark Catalyst和Tungsten优化
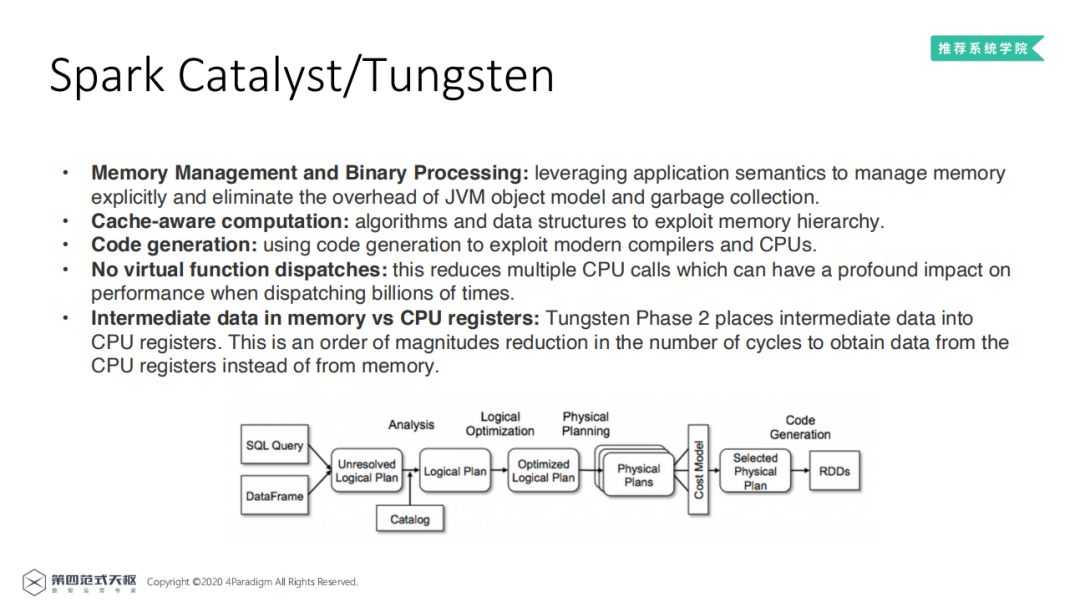
Spark2.0之后提供了Catalyst和Tungsten优化。图为Catalyst从SQL解析到生成物理计划的流程图,由SQL语句或DataFrame接口通过编译器技术 ( 语法解析等 ) 生成Unresolved Logical Plan,Catalyst通过解析Catalog对Unresolved Logical Plan处理得到Logical Plan,在经过SQL常用优化方案,得到Optimized Logical Plan,优化之Catalyst后可以生成多个基于Spark运行的Physical Plan,最终选择其中最高效的进行运行。该方式适合于计算节点优化,对于SQL的优化也同样效果显著。
Tungsten是另外一种优化方案。主要的优化点在于:
-
内存管理与堆外存储避免了多余的内存使用,同时减少了GC;
-
引入code generation技术,通过JIT编译运行,Spark动态生成Java字节码来计算这些表达式,而不是为逐行解析执行,减少了原始数据类型的装箱操作,更重要的是避免了Overhead较大的虚函数调用。
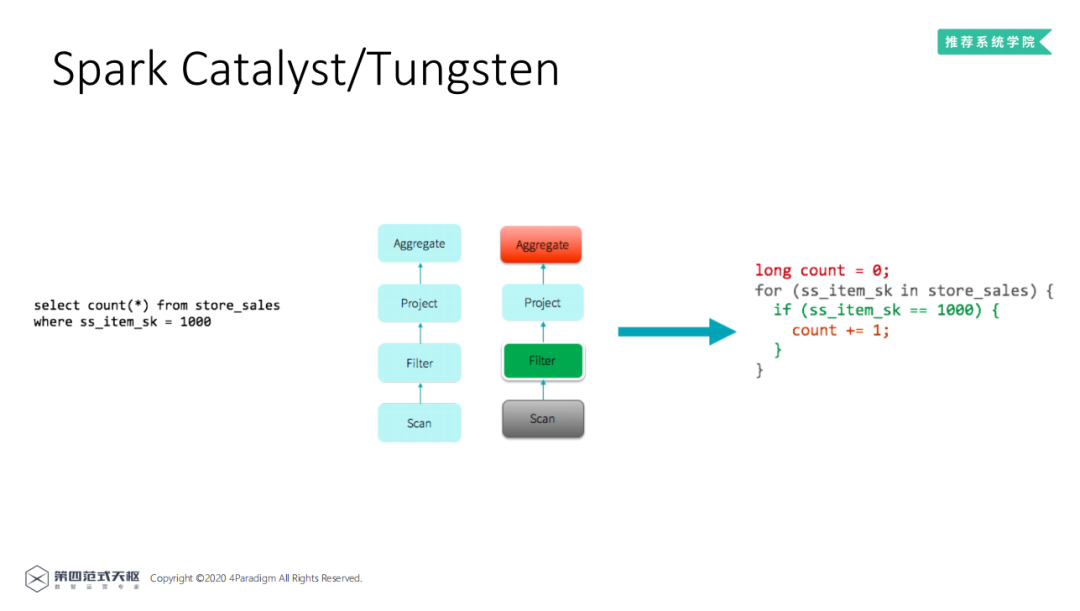
以一个经典实例来介绍Tungsten的原理。左侧的SQL命令可以翻译成在Spark上运行的Logical Plan,由下往上分为4个计算节点,传统的SQL执行引擎中,四个节点分别由四个迭代器实现 ( 可以理解为四个循环 ),循环没有合并优化以及节点的虚函数调用对于CPU Cache非常不优化,导致传统的SQL引擎计算性能比较差。右侧为Tungsten优化后的结果,使用了whole staged code generation,对多节点的循环进行了合并,性能有着明显的提升。
2. Catalyst/Tungsten的不足

Catalyst/Tungsten给Spark带来了明显的性能能提升,但Catalyst/Tungsten的优化仍然是基于Java进行的,如果能使用更底层的指令集,如汇编、二进制码效果会更好;JVM难以支持循环展开等优化方式;而且并非所有的节点都支持code generation,例如图中的WindowExec节点就不支持code generation。
3. FESQL

鉴于以原因,Catalyst/Tungsten的优化仍有不足,第四范式基于LLVM技术进一步优化得到FESQL。SparkSQL架构如黄色部分所示,FESQL架构如蓝色框所示,根据SparkSQL语句生成FESQL Logical Plan,再由LLVM JIT生成平台二进制码直接执行,相比于Spark少了JVM一层,性能也会有明显提升。
4. LLVM简介
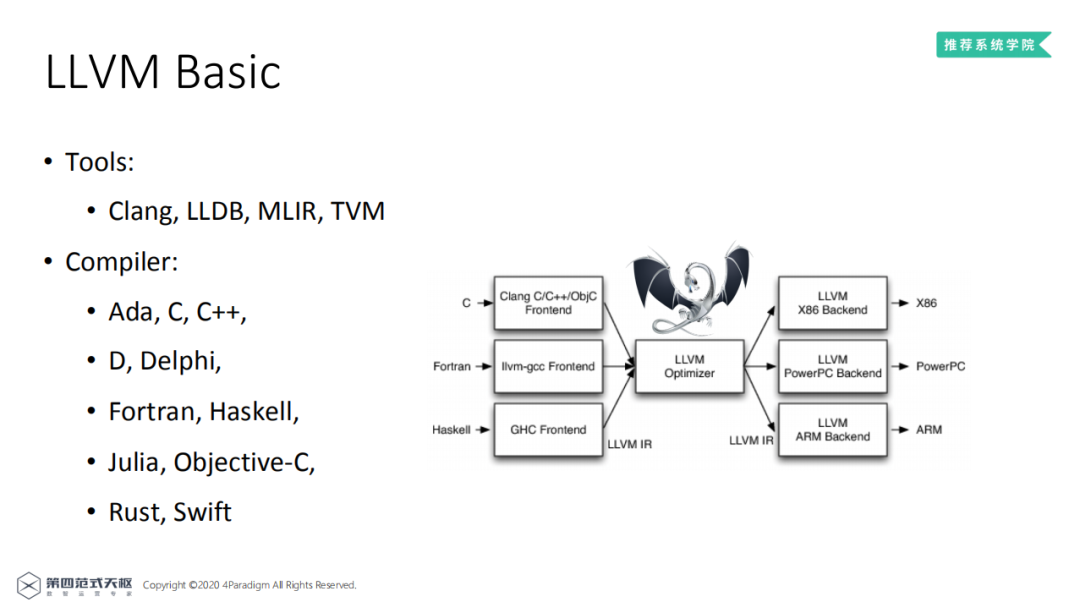
LLVM项目是一个模块化的、可重用的编译器和工具链集合,可以方便的实现编译器和代码生成的工作。提供了许多有用的工具,如Clang、LLDB、MLIR、TVM等,能够实现多种编程语言的编译器。

JIT ( Just-In-Time Compiler ) 编译,可以一边运行程序一边编译二进制代码,右图为使用JIT编译的Add函数,这部分代码可以在运行时被翻译成底层代码,与直接使用C++来实现效率接近,同时JIT能够适应不同的CPU生成优化的二进制码。
5. FESQL的优化点

目前已经能使用循环展开、常数折叠、向量化和一些基于CPU本身的优化;未来,基于PTX后端还可以尝试生成CUDA代码,利用GPU进行计算的加速。
6. 性能比较
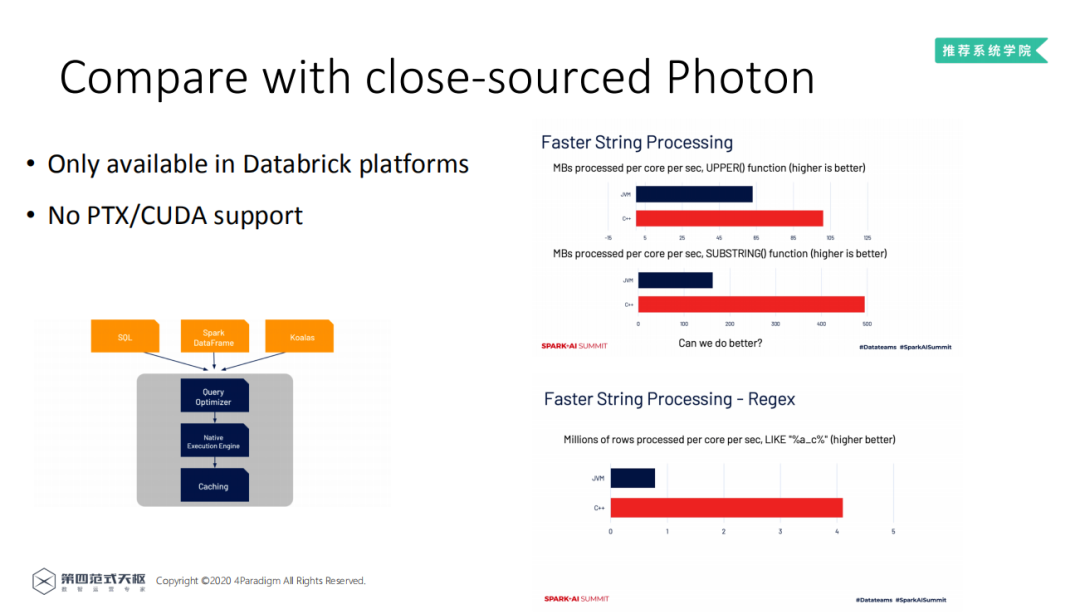
FESQL与Databrick内部的Photon非常相似 ( Photon内部由C++实现 ),因而进行对两者进行比较。Photon是Databrick的企业产品,仅能在Databrick的平台上使用,且不支持PTX/CUDA。对比由C++和由JVM实现的处理引擎的性能,发现C++实现的处理引擎性能非常优越。
7. FESQL的节点优化
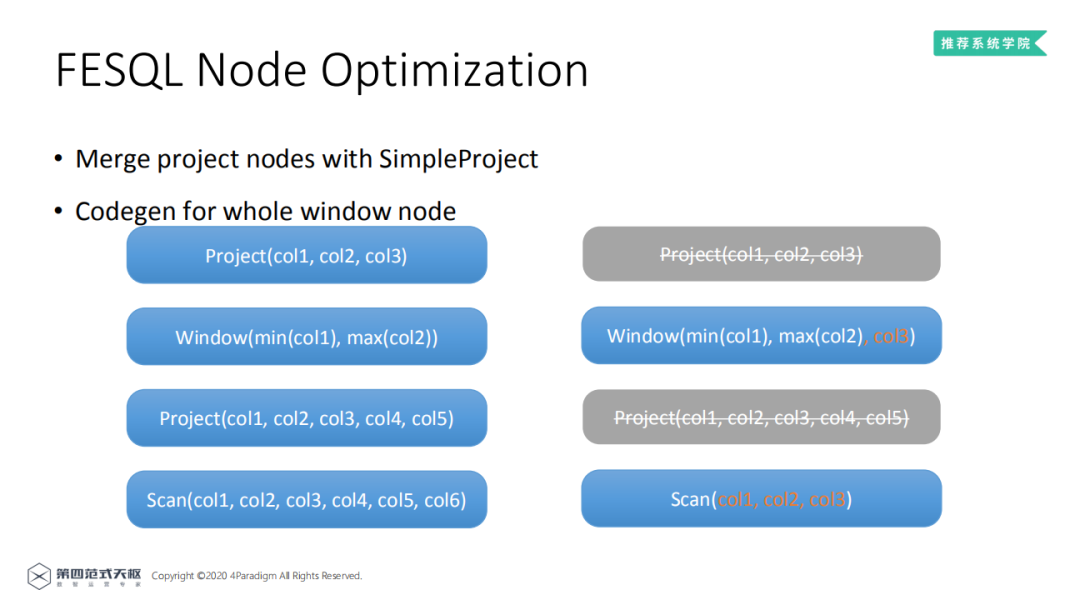
FESQL使用了节点优化,使用SimpleProject对Project节点进行合并优化,对窗口节点使用code generate进行优化。下图说明了对于节点的优化可以明显减少执行的流程。
8. FESQL的表达式优化

FESQL也实现了非常多表达式优化,保证在不同SQL场景都比传统数据库有着更好的性能表现。
9. 性能
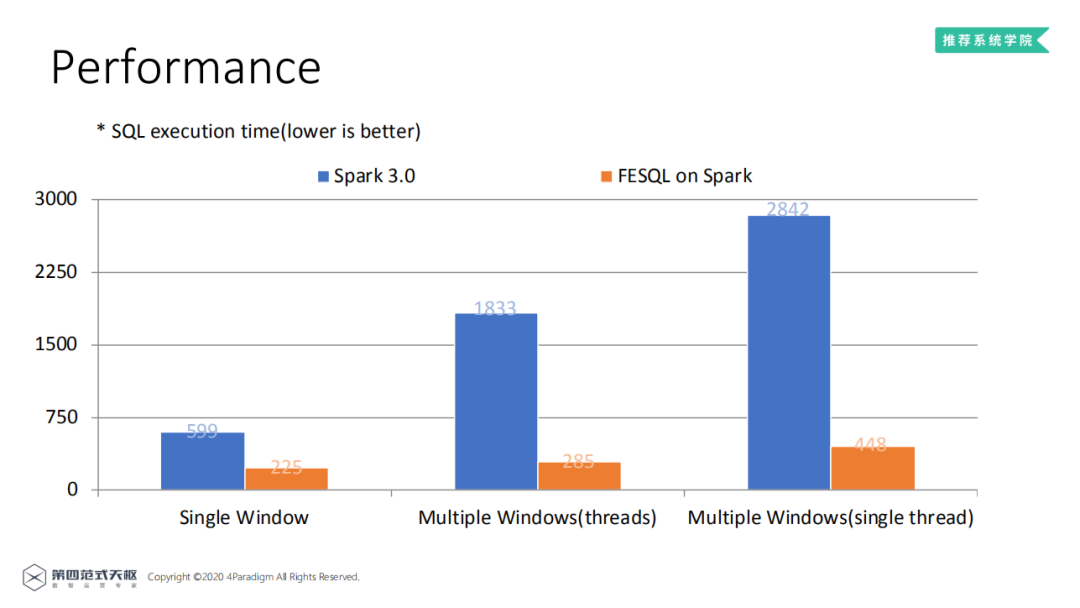
对比Spark 3.0和FESQL on Spark可以发现,FESQL的执行效率明显高于Spark 3.0,多窗口的情况下效果更明显,有着接近6倍的性能提升。
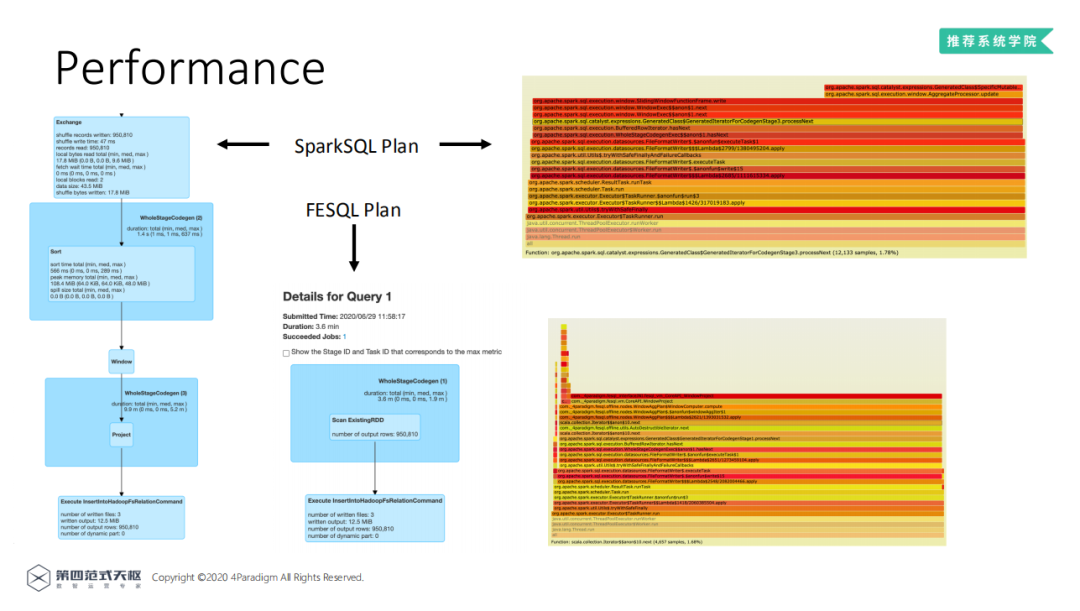
通过对比两者生成的逻辑计划图,可以发现FESQL的计划图明显更简单,通过对比两者的火焰图,底层RDD计算基本一致,FESQL取样的样本数更少,执行时间更短,因此FESQL的执行效率更高。
10. 展望

未来第四范式计划推出LLVM-enabled Spark Distribution,使开发者可以通过设置SPARK_HOME便利的实现性能加速;为开发者提供Docker、Notebook、Jar、Whl包,便于开发;提供类似Python的保证一致性的DSL语言用于UDF和UDFA实现;还有提供对CUDA和GPU的支持。

大规模推荐系统中可以使用Spark、Flink、ES、FESQL实现大规模的数据处理,其中Spark更适合离线的批处理,而不适合线上处理,FESQL能同时进行线上线下服务因为能够保证特征一致性,同时LLVM JIT实现的FESQL拥有比Spark 3.0更好的性能。
更多SQL原生计算引擎以及Spark性能优化的技术,欢迎关注我们后续的分享。今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
嘉宾介绍:

陈迪豪
欢迎加入 DataFunTalk 大数据、算法交流群,跟同行零距离交流。如想进群,请识别下面的二维码,根据提示自主入群。

文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,7万+精准粉丝。

?分享、点赞、在看,给个三连击呗!?

文章评论