前言
任何刚接触爬虫编程的朋友可能都熟悉或者或多或少了解过基于 Python 异步框架 Twisted 的爬虫框架 Scrapy。Scrapy 发展了将近 7 年,是爬虫框架中的开山鼻祖,自然而然成为最受欢迎的也是应用最广的爬虫框架。对于 Scrapy 来说,其天然的优势是支持并发,而且集成了 HTTP 请求、下载、解析、调度等爬虫程序中常见的功能模块,让爬虫工程师只专注于页面解析和制定抓取规则,在当时极大的简化了爬虫开发流程,提高了开发效率。
但是,「Scrapy 并不是完美的,它仍然有不少缺点」。其中,它的模版定制化成为了制约 Scrapy 爬虫项目的双刃剑:一方面,Scrapy 抽象出了各种必要的模块,包括爬虫(Spider)、抓取结果(Item)、中间件(Middleware)、管道(Pipeline)、设置(Setting)等,让用户可以直接上手按照一定规则编写自己想要开发的爬虫程序;另一方面,这些高度抽象的模块让整个爬虫项目显得比较臃肿,每个爬虫项目都需要按照相应的模版生成好几个文件,导致配置、爬虫等管理起来相对比较混乱。而且,Scrapy 在一些特殊场景例如分布式抓取时显得心有余而力不足,因此很多高级爬虫工程师甚至需要更改 Scrapy 源码来满足业务要求。
为了解决这些问题,基于静态语言 Golang 的爬虫框架 Colly 在 2017 年末诞生了。虽然它的名气和受欢迎程度还不及 Scrapy,但在试用之后我发现它有一个最特别的优势:「简单(Easiness)」。根据 Colly 官网上的特性介绍,它有清爽的 API(Clean API),快速(Fast),天然支持分布式(Distributed),同步/异步/并行抓取(Sync/async/parallel scraping),丰富的扩展(Extensions),以及更多特性。作者在简单的看了 Colly 的文档之后,尝试用 Colly 编写一些相对简单的爬虫程序,发现编写完毕后,每个网站的代码只包含一个文件。简而言之,「它相当轻量级,不需要特别多的冗余代码就可以实现自己想要的逻辑」。
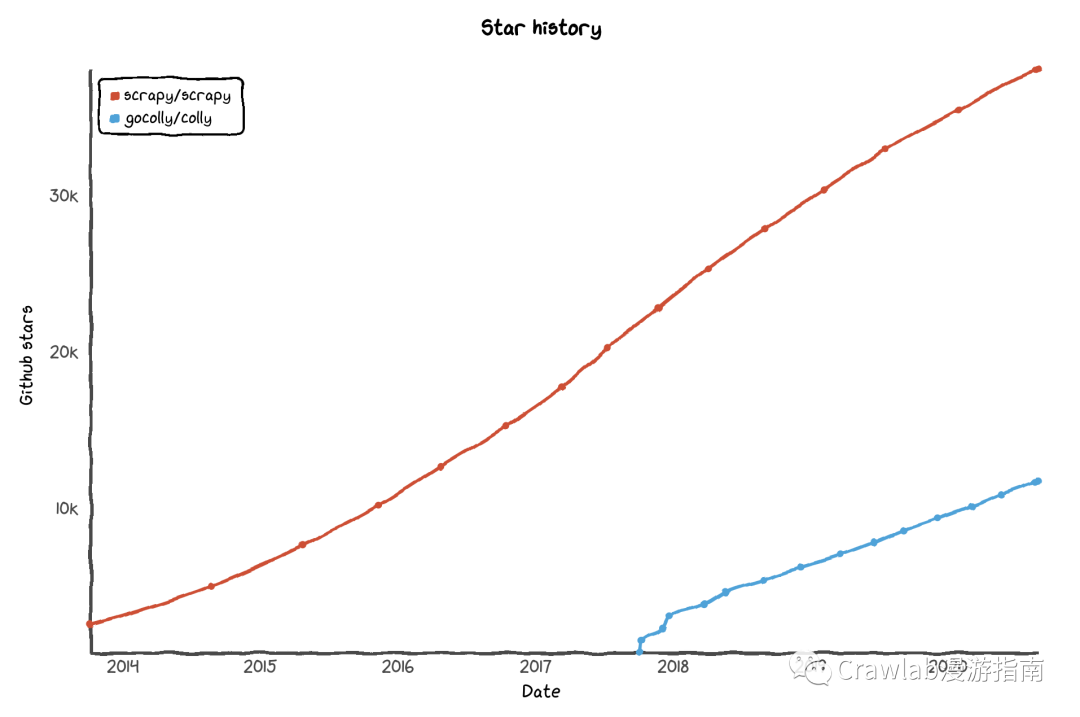
下图是 Colly 和 Scrapy 在 Github 的 Star 数对比。可以看到 Colly 发展较晚,star 数不到 Scrapy 的三分之一,但还在高速增长当中。本文将着重介绍这个年轻而强大的爬虫框架: Colly。
静态语言 Golang
Colly 是基于静态语言 Golang 开发的。众所周知,Golang 也是一个比较年轻的语言,仅有 13 年历史(相较而言,Python 有将近 30 年历史)。Golang 天然支持并发(Concurrency),要起一个协程(Coroutine),只需要在调用函数前加一个 go 关键词即可,非常简单。当然,Golang 还有其他很棒的特性,例如通道(chan)。不过对于爬虫来说支持并发是非常重要的,因为一个高效的爬虫需要尽可能多的占用网络带宽资源,「Golang 的并发特性给编写爬虫框架来说带来了优势」。反观 Python,如果要实现并发的话需要做很多工作,包括利用 asyncio 库和从 JavaScript ES7 借鉴过来的 async/await 语法,并不是很直观。
下面是 Golang 的异步语法例子。
func run() {
fmt.Printf("hello world")
}
func main() {
go run()
}
下面是 Python 的异步语法例子。
import asyncio
async def main():
print('Hello ...')
await asyncio.sleep(1)
print('... World!')
# Python 3.7+
asyncio.run(main())
Golang 作为静态语言还有另一个非常重要的优势,也就是其代码的「可预测性(Predictability)」。静态语言要求变量、参数以及函数返回结果都指定相应的类型,并且在编译的时候会检查类型的正确性,保证代码的可靠性。用静态语言编写的一个好处,就是可以让自己避免很多因为类型错误导致的 bug。因此,对于可靠性和健壮性要求较高的大型项目来说,用静态语言编写会是比较合理的选择。编写 Golang 程序的时候,IDE 会根据类型或变量自动补全潜在的代码,是不是很香。相反,以 Python 为代表的动态语言,就没那么严格了。虽然 Python 是强类型语言,但它并不存在预编译的过程,因此无法在编译时(Compile)检测出类型错误。很多时候如果类型传入不对,都会在运行时(Runtime)导致错误。网上流传的 “动态一时爽,重构火葬场”,说的也是这个道理。虽然动态语言(例如 Python)给抓取结果赋予了一定的灵活性,但在我看来,「大型爬虫项目用静态语言(例如 Golang)会是个更合理的选择」。
Colly
之前也介绍了,Colly 是一个由 Golang 编写的爬虫框架。Colly 其实是 Collector 或 Collecting 的昵称。它精简易用而强大高效,正在逐渐成为 Scrapy 以外的爬虫框架选择。
咱们下面用一个例子来看一下它是如何做到的。(本文不是 Colly 的参考文档,仅希望通过一些例子来介绍 Colly 的优势和特性,要看所有 API 请参考 Colly 官网文档)
在任意目录创建 baidu_spider.go 文件,并输入下列代码。
package main
import (
"fmt"
"github.com/crawlab-team/crawlab-go-sdk/entity"
"github.com/gocolly/colly/v2"
)
func main() {
// 生成 colly 采集器
c := colly.NewCollector(
colly.AllowedDomains("www.baidu.com"),
colly.Async(true),
colly.UserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36"),
)
// 抓取结果数据钩子函数
c.OnHTML(".result.c-container", func(e *colly.HTMLElement) {
// 抓取结果实例
item := entity.Item{
"title": e.ChildText("h3.t > a"),
"url": e.ChildAttr("h3.t > a", "href"),
}
// 打印抓取结果
fmt.Println(item)
// 取消注释调用 Crawlab Go SDK 存入数据库
//_ = crawlab.SaveItem(item)
})
// 分页钩子函数
c.OnHTML("a.n", func(e *colly.HTMLElement) {
_ = c.Visit("https://www.baidu.com" + e.Attr("href"))
})
// 访问初始 URL
startUrl := "https://www.baidu.com/s?wd=crawlab"
_ = c.Visit(startUrl)
// 等待爬虫结束
c.Wait()
}
上面这个爬虫脚本,仅有 40 行代码。如果要用 Scrapy 来完成同样的功能,可能需要更多代码和文件目录。
可以从代码中看到,Colly 的爬虫程序编写非常简单,主要包含四个部分:
-
生成 Colly 采集器(Collector) c,并传入一些配置信息; -
OnHTML钩子函数,包含colly.HTMLElement元素实例,这里主要是处理抓取结果的逻辑; -
c.Visit访问函数,类似 Scrapy 中的yield scrapy.Request; -
c.Wait等待函数,等待 Colly 爬虫程序执行完毕。
创建好之后,在所在目录执行 go run baidu_spider.go,即可运行百度搜索 “crawlab” 关键词爬虫。运行结果类似如下。
...
map[title:docker安装爬虫管理工具crawlab - kindvampire - 博客园 url:http://www.baidu.com/link?url=ueCY-MwzzGwaVqXw3Q18Fz8rEodI1P_mv60lRd8H0UZdFC4xVnVwWtsh-HpiwaOFI1zVjZFeVca]
map[title:crawlab python脚本关联mongodb结果集,实例_kai4024589..._CSDN博客 url:http://www.baidu.com/link?url=2wFQZaLoEk7OOTHrf1LOJcPiBAZEFETQYbjrqnrJi_Wfqdx-gPFIyjt2q3f7lTC-8A6SWz_l8zE6D8SBs1j0c4DOIwbdAw8i]
map[title:手把手教你如何用Crawlab构建技术文章聚合平台(一)_wei..._CSDN博客 url:http://www.baidu.com/link?url=nr9NOz2dqYFuaU5E1Zjz0OIfeeixSADNBNcHwj4dw9zypIky-9dVxd4RdzdS8-JMP7_X-LYpo0ydWmB8VNBmqq]
map[title:tikazyq-crawlab-master crawlab爬虫平台 适合scrapy分布式部署... url:http://www.baidu.com/link?url=VibsGu0BinYAUR_96pWCmcELObAXIPn7rKprlc9HR_607_cuEbxlcShUHqXjOoV6dnc4pND5F0K]
map[title:手把手教你如何用Crawlab构建技术文章聚合平台(一) - 个人文章... url:http://www.baidu.com/link?url=SG6dJcLc20xIuiesjRIXu2XzGSR0N674BEnUTveJhYe5mRc9SFtggk-NL0pmAAa]
map[title:爬虫管理平台Crawlab v0.3.0发布(Golang版本) - 个人文章... url:http://www.baidu.com/link?url=TItw3zWB4jHCoGmoQMm01E7oP2WlwfX7BRMsA9WDhaxHeQZZDi3I8bZh_kgTfpNx4fhtf42_]
map[title:Crawlab 单节点服务集群搭建部署简明教程 - 个人文章 - Segment... url:http://www.baidu.com/link?url=cuYEFA1zjqK1GiEmDCjwRMLDGFVKDsz6u4ljYjQol-VwDdr_cBS9Y3UlgChkyCuO7A_]
...
你可能会纳闷,Pipeline 和 Middleware 等 Scrapy 中定义的模块去哪里了?其实,你需要注意的是,这些模块并不是必须的,只是大佬们在开发爬虫过程中总结出来的一些实用的逻辑,抽象出来了而已。如果要在 Colly 中实现 Pipeline,直接在 c.OnHTML 钩子函数中的回调函数中调用一下后续处理函数即可,例如下面代码。
...
c.OnHTML(".result.c-container", func(e *colly.HTMLElement) {
item := entity.Item{
"title": e.ChildText("h3.t > a"),
"url": e.ChildAttr("h3.t > a", "href"),
}
// 后续处理抓取结果
PostProcess(item)
})
...
从这个例子中,你可以看到 Colly 的 API 非常简单、清爽,而正是这种简单赋予了其极高的「灵活性(Flexibility)」,让开发者可以在框架内做很多复杂的事情。
当然,Colly 也是有缺点的。从目前的开发进度来看,Colly 似乎还无法支持动态渲染内容的抓取,例如 Ajax 数据渲染,而这个在 Scrapy 中是有现成的不少解决方案的。不过从最近的 Github 上的 Pull Request 来看,支持动态渲染内容应该会很快支持 chromedp 了,也就是支持调用 Chromium 来运行 JavaScript 内容。另外,Colly 似乎还缺少 Scrapy 中内置的日志系统和数据统计模块,似乎有些过于轻量化。
不过,我们有理由相信,随着今后不断迭代,Colly 会变得越来越全面和强大的。
与 Crawlab 集成
Crawlab 是支持任何语言和框架的分布式爬虫管理平台,理论上能运行所有类型的爬虫,包括 Colly 和 Scrapy。对 Crawlab 不了解的朋友可以查看 Crawlab 官网 以及 Github 首页)。
首先利用 Crawlab CLI 将爬虫文件上传。
~/projects/tikazyq/colly-crawlers/baidu(master*) » crawlab upload
go.mod
go.sum
baidu_spider.go
uploaded successfully
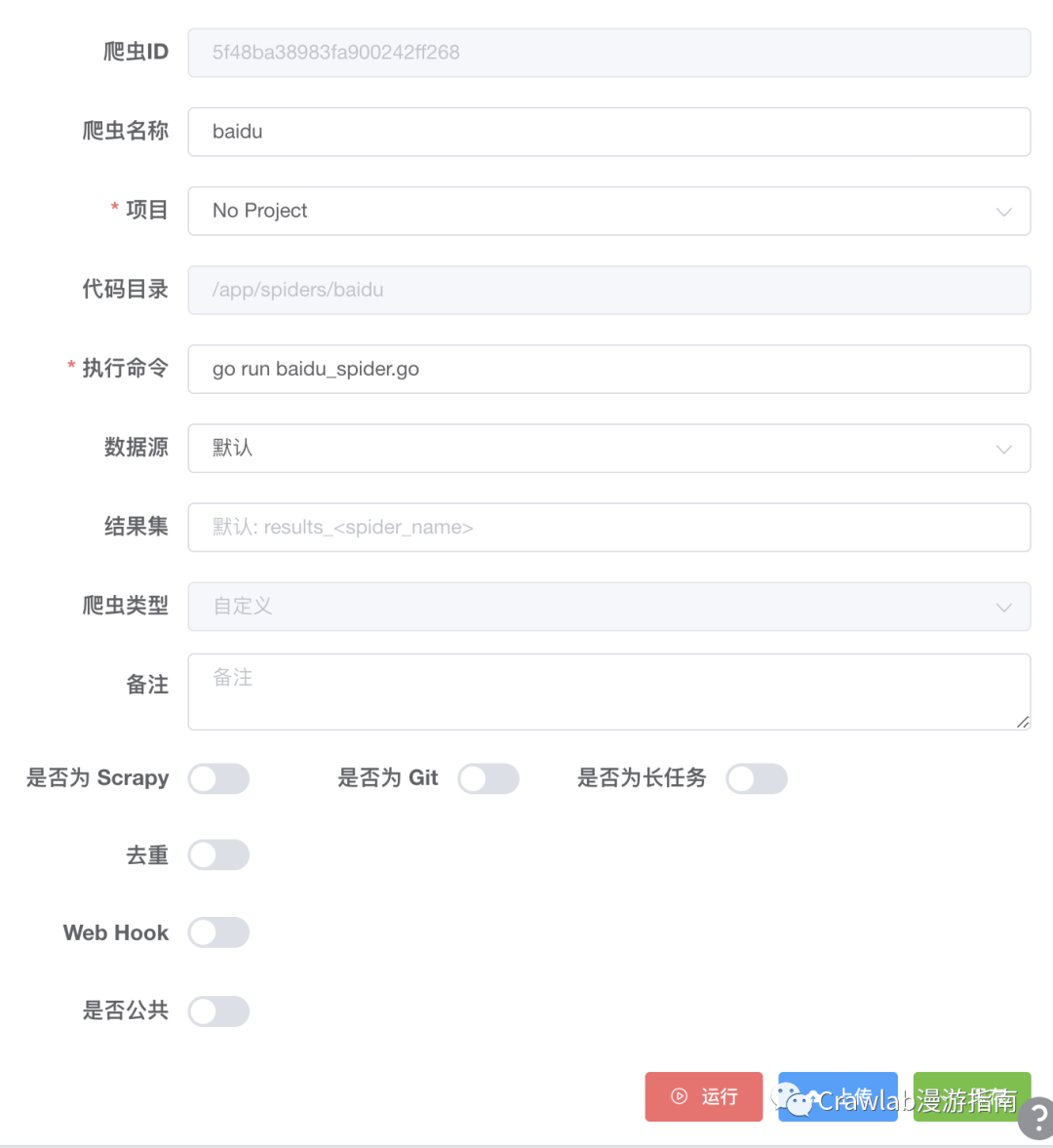
然后在 Crawlab 的爬虫详情界面中输入执行命令 go run baidu_spider.go,点击 “运行” 开启爬虫。然后爬虫就会开始运行。
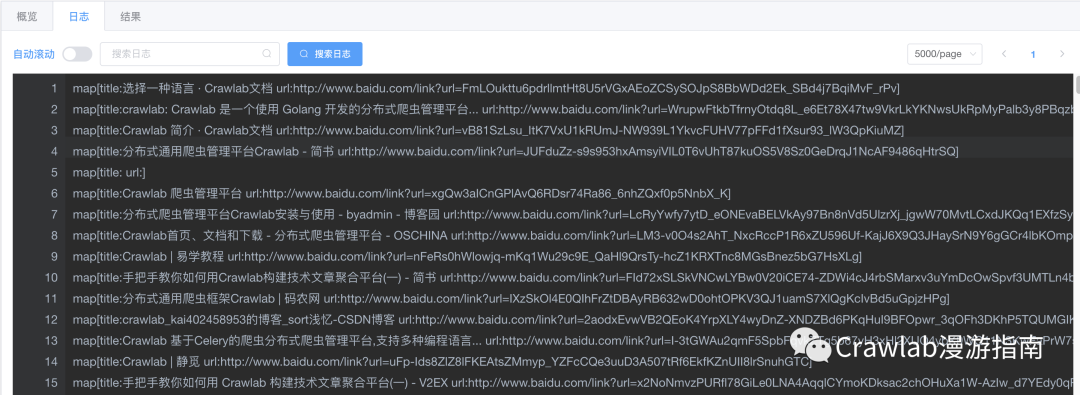
等待一段时间,爬虫运行结束。我们可以在日志中看到打印出来的结果。
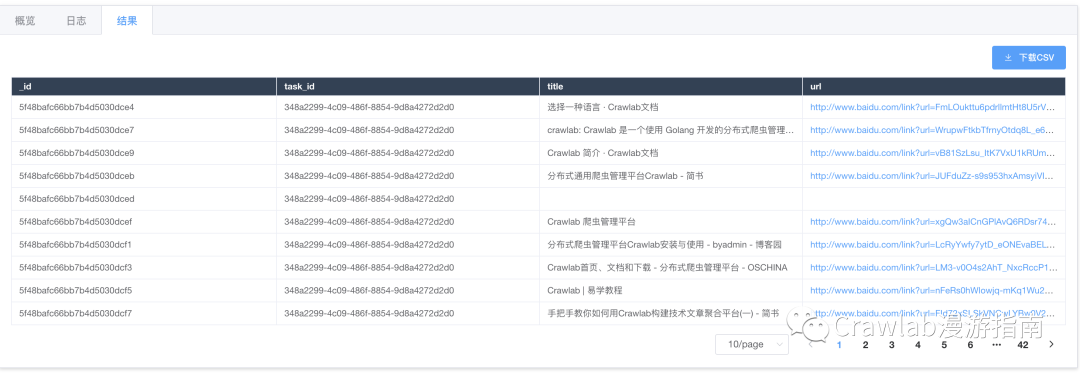
并且,我们还可以在 “结果” 中查看抓取到的结果数据。这些结果是默认保存在 MongoDB 数据库里的。
因此,用 Crawlab 来管理 Colly 爬虫是非常方便的。
总结
本文从介绍知名爬虫框架 Scrapy 的优缺点开始,引入了基于 Golang 的高效而简单的爬虫框架 Colly。然后我们用一个百度搜索引擎抓取的例子,阐述了 Colly 的优势,也就是它精简而清爽的 API 以及静态语言的健壮性,还有很多其他实用特性。Colly 的出现,或许象征着爬虫开发者对简洁的追求,所谓 “大道至简”,就是「用简单而纯粹的东西创造巨大的价值」。爬虫技术的发展,是一个开发流程由复杂变简单、而程序功能由简单变复杂的过程。爬虫技术经历了 urllib/requests+BeautifulSoup 原始技术,到 Scrapy 的全能框架,再到如今的 Colly 的轻量级框架。而如今已经有不少所谓的 “低代码” 甚至 “无代码” 爬虫平台了,例如 Crawlab 可配置爬虫、八爪鱼/后羿采集器。而智能化的爬虫抓取也在逐渐变得流行。从这个角度来看,Colly 相对于 Scrapy 应该是进步了。不过「现在要说 Colly 能否取代 Scrapy 还为时过早,因为 Scrapy 还有很多优秀的特性和生态是 Colly 暂时无法替代的」。但是,Colly 目前正在高速发展,逐渐被开发者所了解,随着不断的反馈迭代,「Colly 非常有潜力成为另一个爬虫界的必备技术」。
参考
-
Colly Github: https://github.com/gocolly/colly -
Colly 文档: https://pkg.go.dev/github.com/gocolly/colly/v2?tab=doc -
Crawlab Github: https://github.com/crawlab-team/crawlab -
Crawlab 官网: https://crawlab.cn -
Crawlab 演示: https://demo-pro.crawlab.cn

文章评论