
本文只适合对python感兴趣的初学者(因为我也是),只是单纯的小分享。代码不严谨的地方请见谅
疫情期间在家闲来无事,每天打游戏荒废了一段时间。我觉得自己不能在这么颓废下去,就立马起身写了一点python代码(本人只是python新手)。
找来找去突然找到一个不错的网站(你懂得),看见上面的照片于是起来自己写了一个小程序能够自动爬取这个网站照片的小程序来练练手
上网站:
https://www.meizitu.com/a/xinggan_2_1.html
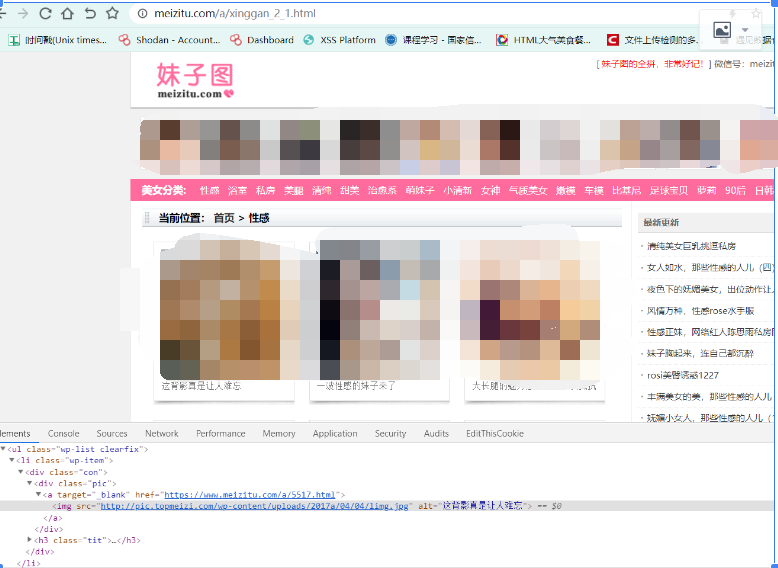
画面过于美好先打上一波马赛克,马赛克之前的模样。
自己想象一下
第一打开网站 我们按f12查看源代码发现,这里的图片的xpath只有缩略图,但是他的a标签里的href的网址有他大照片的地址,我们点进去查看后,发现img里面有src。
这里 如果只是单纯的爬取他的src,那我们爬取的就只有这一个页面,如果还要在爬取其他页面还要在修改地址很麻烦。
所以第一步我们用xpath先来定位缩略图里面a标签里面的href,将他生成一个列表,同时我们发现所有缩略图的xpath都是有规律的所以这样无疑减少了很多难度。
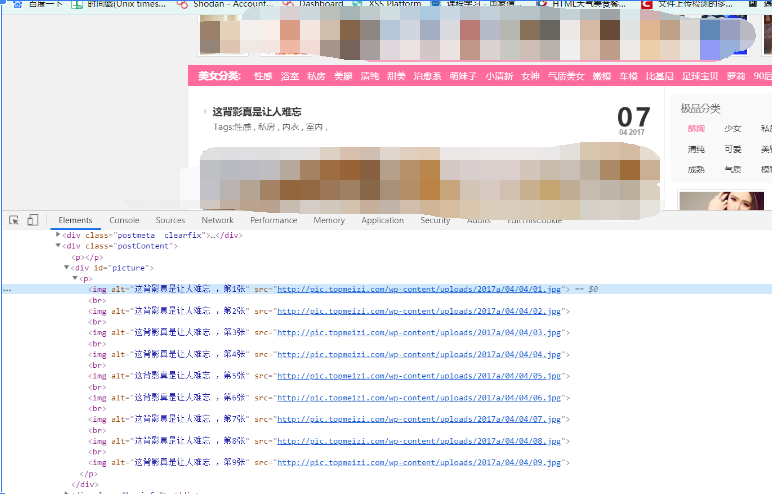
其二打开缩略图,发现图片的xpath也是很好获取
好了上源码
import requests
from lxml import etree
import time
class sprider(object):
def __init__(self):
self.header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
def url(self):
url = 'https://www.meizitu.com/a/xinggan_2_1.html'
response = requests.get(url,headers=self.header)
selector = etree.HTML(response.content)
for i in range(1,31):
url2 = selector.xpath('//*[@id="maincontent"]/div[1]/ul/li[%d]/div/div/a/@href' %(i))[0]
response2 = requests.get(url2,headers=self.header)
selector2 = etree.HTML(response2.content)
self.pc(selector2)
def pc(self,selector2):
for i in range(1,12):
time.sleep(2)
src = selector2.xpath('//*[@id="picture"]/p/img[%d]/@src' %(i))
title = selector2.xpath('//*[@id="picture"]/p/img[%d]/@alt' %(i))
print(title)
print(src)
self.write(src,title)
def write(self,src,title):
for a,b in zip(src,title):
name = b ".jpg"
print("正在抓取",name)
photo = requests.get(a,headers=self.header)
time.sleep(5)
with open(name,"wb") as f:
f.write(photo.content)
s = sprider()
s.url()
ps:这个只是我自己编写的一个小程序 仅供学习 想自己用的话还要结合自己的实际情况 比如User-Agent头 要替换成自己的
开始运行之后啊就可以看见一张张照片存放在自己的文件夹里了可能会比较慢 没加多线程 后续有时间我会在写一篇多线程的文章
见谅见谅
默认存放在这个程序所在的文件夹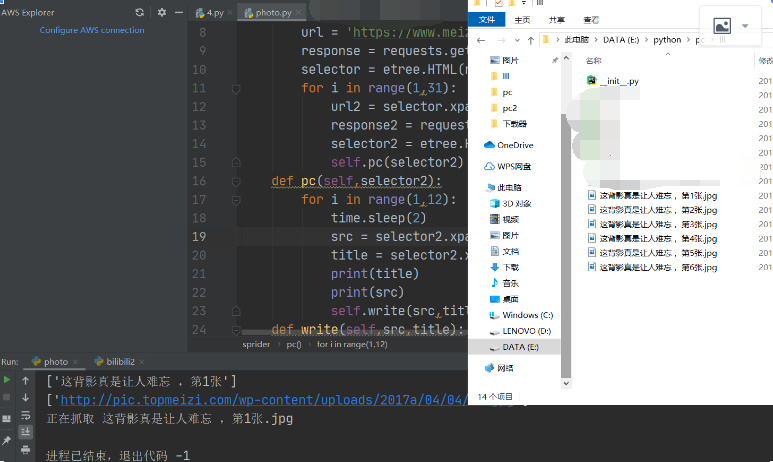
注:本文只提供技术分享,请勿用作其他非法用途。如果造成任何法律部后果与本文作者无关

推荐文章++++



文章评论