
「 点击图片查看近两年的爆款好文 」
」
作者:吴叶磊 原文:https://aleiwu.com/post/prometheus-alert-why/
-
我的 Prometheus 为啥报警? -
我的 Prometheus 为啥不报警?
从 for 参数开始
我们首先需要一些背景知识:Prometheus 是如何计算并产生警报的?
- alert: KubeAPILatencyHigh annotations: message: The API server has a 99th percentile latency of {{ $value }} seconds for {{ $labels.verb }} {{ $labels.resource }}. expr: |
cluster_quantile:apiserver_request_latencies:histogram_quantile{job="apiserver",quantile="0.99",subresource!="log"} > 4 for: 10m labels: severity: critical

为什么不报警?
为什么报警?
采样间隔
这其实都源自于 Prometheus 的数据存储方式与计算方式。
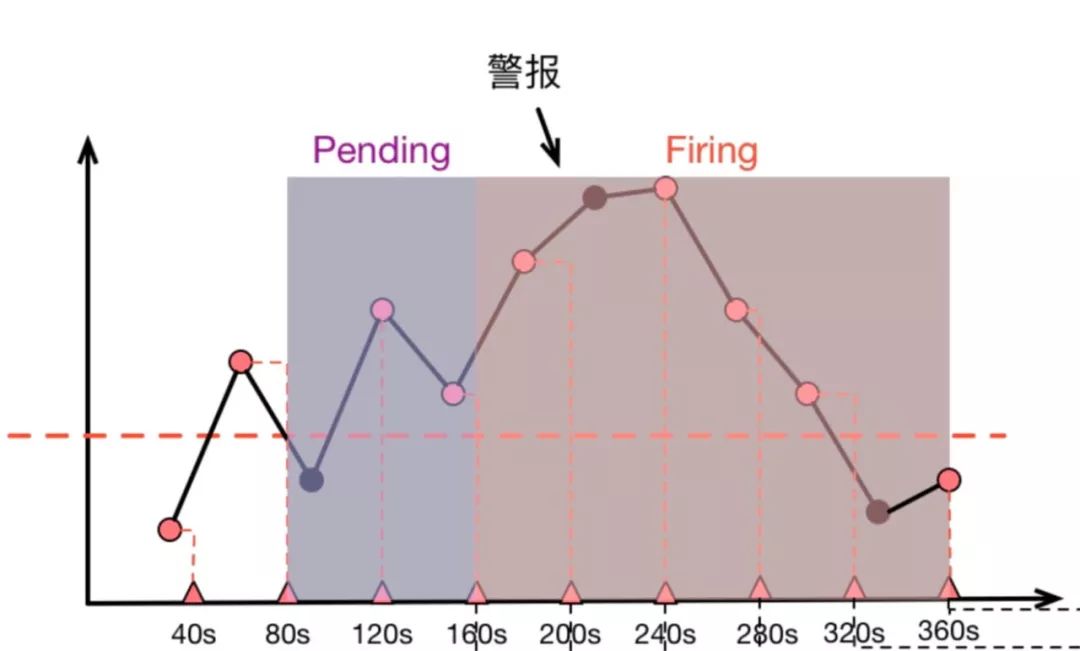
-
40s 时,第一次计算,低于阈值 -
80s 时,第二次计算,高于阈值,进入 Pending 状态 -
120s 时,第三次计算,仍然高于阈值,90s 处的原始采样点虽然低于阈值,但是警报规则计算时并没有”看到它“ -
160s 时,第四次计算,高于阈值,Pending 达到 2 分钟,进入 firing 状态 -
持续高于阈值 -
直到 360s 时,计算得到低于阈值,警报消除
如何应对
首先嘛, Prometheus 作为一个指标系统天生就不是精确的——由于指标本身就是稀疏采样的,事实上所有的图表和警报都是”估算”,我们也就不必 太纠结于图表和警报的对应性,能够帮助我们发现问题解决问题就是一个好监控系统。当然,有时候我们也得证明这个警报确实没问题,那可以看一眼 `ALERTS` 指标。`ALERTS` 是 Prometheus 在警报计算过程中维护的内建指标,它记录每个警报从 Pending 到 Firing 的整个历史过程,拉出来一看也就清楚了。
到此为止了吗?
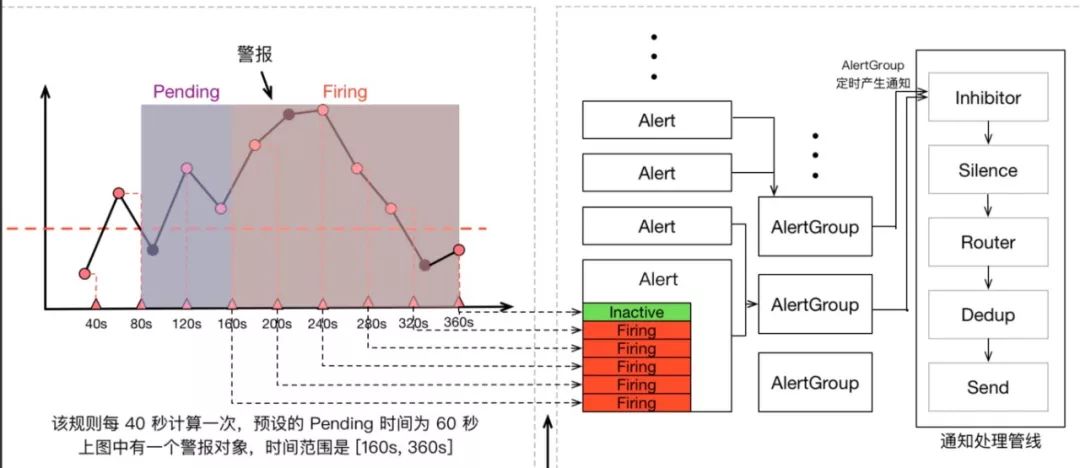
Prometheus 警报不仅包含 Prometheus 本身,还包含用于警报治理的 Alertmanager,我们可以看一看上面那张指标计算示意图的全图:
最新整理的 2TB 技术干货:包括系统运维、数据库、redis、MogoDB、电子书、Java基础课程、Java实战项目、架构师综合教程、架构师实战项目、大数据、Docker容器、ELK Stack、机器学习、BAT面试精讲视频等。在「 民工哥技术之路」微信公众号对话框回复关键字:1024 即可获取全部资料。
精彩文章推荐:
不就是SELECT INSERT UPDATE ?我竟然被面试官问的脸都绿了

点击【阅读原文】发现更多精彩
点个在看、转发支持一下吧↓↓↓

文章评论