
阿里妹导读:Flink 在机器学习领域的进展一直是众多开发者关注的焦点,今年 Flink 迎来了一个小里程碑:机器学习算法平台 Alink 开源,这也宣告了 Flink 正式切入 AI 领域。
阿里资深算法专家杨旭(花名:品数),将为大家详细介绍本次Alink主要功能和特点,希望与业界同仁共同携手,推动Flink社区进一步发展。
 Github 下载地址:
https://github.com/alibaba/Alink
Github 下载地址:
https://github.com/alibaba/Alink
背景
随着大数据时代的到来和人工智能的崛起,机器学习所能处理的场景更加广泛和多样。构建的模型需要对批量数据进行处理,为了达到实时性的要求还需要直接对流式数据进行实时预测,还要具备将模型应用在企业应用和微服务上能力。为了取得更好的业务效果,算法工程师们需要尝试更多更复杂的模型,需要处理更大的数据集,使用分布式集群已经成为常态;为了及时对市场的变化进行反应,越来越多的业务选用在线学习方式直接处理流式数据、实时更新模型。
我们团队一直从事算法平台的研发工作,感受到了高效能的算法组件和便捷操作平台对开发者的帮助。针对正在兴起的机器学习广泛而多样的应用场景,我们在2017年开始基于Flink研发新一代的机器学习算法平台,使得数据分析和应用开发人员能够轻松搭建端到端的业务流程。项目名称定为Alink,取自相关名称(Alibaba, Algorithm, AI, Flink, Blink)的公共部分。
什么是 Alink ?
Alink 是阿里巴巴计算平台事业部PAI团队从 2017 年开始基于实时计算引擎 Flink 研发的新一代机器学习算法平台,提供丰富的算法组件库和便捷的操作框架,开发者可以一键搭建覆盖数据处理、特征工程、模型训练、模型预测的算法模型开发全流程。
借助Flink在批流一体化方面的优势,Alink能够为批流任务提供一致性的操作。在实践过程中,Flink原有的机器学习库FlinkML的局限性显露出来(仅支持10余种算法,支持的数据结构也不够通用),但我们看重Flink底层引擎的优秀性能,于是基于Flink重新设计研发了机器学习算法库,于2018年在阿里集团内部上线,随后不断改进完善,在阿里内部错综复杂的业务场景中锻炼成长。
从我们研发Alink的第一天开始,就一直与社区紧密交流合作。多次在Flink Forward大会上介绍我们在机器学习算法库研发方面的最新进展,分享技术心得。
作为业界首个同时支持批式算法、流式算法的机器学习平台,Alink 提供了 Python 接口,开发者无需 Flink 技术背景也可以轻松构建算法模型。
Alink 已被广泛运用在阿里巴巴搜索、推荐、广告等多个核心实时在线业务中。在刚刚落幕的天猫双 11 中,单日数据处理量达到 970PB,每秒处理峰值数据高达 25 亿条。Alink 成功经受住了超大规模实时数据训练的检验,并帮助提升 4% CTR(商品点击转化率)。
开源
去年 Blink 开源的时候,我们就在考虑是否把 Alink 一起开源了。但是后来觉得,第一个开源还没做,不敢一下子步子迈得这么大,要一步步来,而且 Blink 开源也要准备很多东西。当时我们没有办法做到两个大的项目同时开源,所以就先把 Blink 开源做好。
Blink 开源以后,我们想是不是把 Alink 的算法推到 Flink 就好了。但是发现往社区贡献确实是比较复杂的过程,Blink 在推的时候已经占用了很大的带宽,而社区的带宽就那么多,没有办法同时做多件事情。社区也需要一段时间消化,所以决定先把 Blink 消化掉,贡献完了,社区吃得下,然后再把 Alink 逐步贡献回社区。这是没有办法跨越的一个过程。
FlinkML 和 Alink 的关系
FlinkML 是 Flink 社区现存的一套机器学习算法库,这一套算法库已经存在很久而且更新比较缓慢。Alink 是基于新一代的 Flink,完全重新写了一套,跟 FlinkML 没有代码上的关系。Alink 由阿里巴巴计算平台事业部PAI团队研发,开发出来以后在阿里巴巴内部也用了,然后现在正式开源出来。
未来我们希望 Alink 的算法逐渐替换掉 FlinkML 的算法,可能 Alink 就会成为新一代版本的 FlinkML,当然替换还需要一个比较漫长的过程。今年上半年我们积极参加新版FlinkML API的设计,分享Alink API设计的经验;Alink的Params等概念被社区采纳;6月份开始贡献FlinkML代码,已提交了40余个PR,包括算法基础框架、基础工具类及若干算法实现。
Alink 包含了非常多的机器学习算法,往 Flink 贡献或发布的时候也需要比较大的带宽,我们担心整个过程耗时会比较长,所以先把 Alink 单独开源出来,大家如果有需要的可以先用起来。后面贡献进展比较顺利的情况下,Alink 应该能完全合并到 FlinkML,也就是直接进入 Flink 生态的主干,这对于 Alink 来说是最好的归宿,到这个时候 FlinkML 就可以跟 SparkML 完全对应起来了。
相比 SparkML,Alink 的亮点是什么?
Alink 一是依赖于 Flink 计算引擎层;第二 Flink 框架中有 UDF 的算子,Alink 本身对算法做了很多优化,包括在算法实现上做了细节的优化,比如通信、数据访问、迭代数据处理的流程等多方面的优化。基于这些优化可以让算法运行的效率更高,同时我们还做了很多配套工具,让易用性更好。同时 Alink 还有一个核心技术,就是做了在线学习算法。在线学习需要高频快速更新的迭代算法,这种情况下 Alink 有天然的优势,像今日头条、微博的信息流都会经常遇到这样的在线场景。
在离线学习上 Alink 跟 SparkML 对比基本上差不多,只要大家工程化都做得足够好,离线学习无法打出代差,真正的代差一定是设计上的理念不一样。设计上、产品形态、技术形态不一样才会有代差明显的优势。
相比 SparkML,我们的基调是批式算法基本一致,包括功能和性能,Alink 可以支持算法工程师常用的所有算法,包括聚类、分类、回归、数据分析、特征工程等,这些类型的算法是算法工程师常用的。我们开源之前也对标了 SparkML 所有的算法,做到了 100% 对标。除此之外,Alink 最大的亮点是有流式算法和在线学习,在自己的特色上能做到独树一帜,这样对用户来说没有短板,同时优势又很明显。
主要功能和优势
丰富高效的算法库
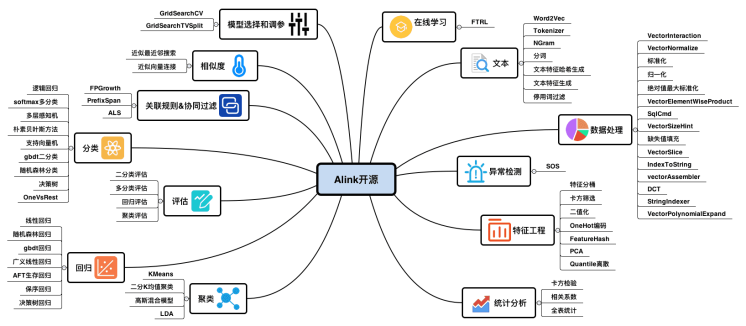
Alink拥有丰富的批式算法和流式算法,不仅实现了丰富高效的算法,还提供了方便的python使用接口,帮助数据分析和应用开发人员能够从数据处理、特征工程、模型训练、预测, 端到端地完成整个流程。
如下图所示,Alink提供的开源算法模块中,每一个模块都包含流式和批式算法。比如线性回归,包含批式线性回归训练,流式线性回归预测和批式线性回归预测。

友好的使用体验
为了提供更好的交互式和可视化体验,我们提供了PyAlink on notebook,用户可以通过PyAlink的python包使用Alink。支持单机运行,也支持集群提交。并且打通Operator(Alink算子)和DataFrame的接口,从而使得Alink整个算法流程无缝融入python。PyAlink也提供使用Python函数来调用UDF或者UDTF。
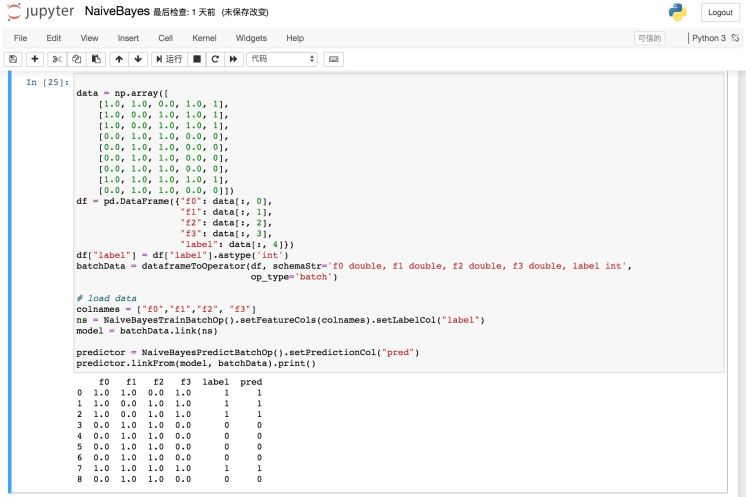
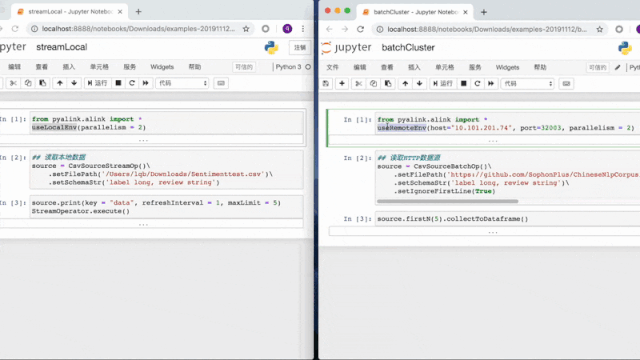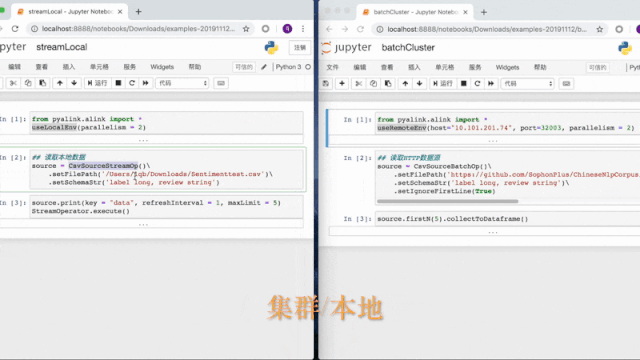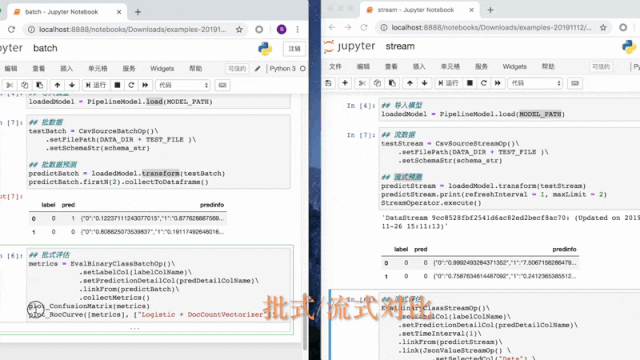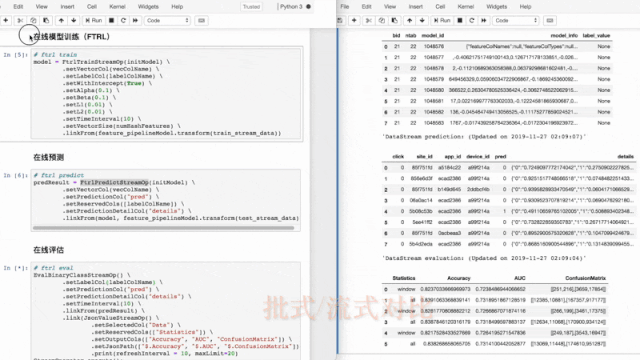
PyAlink在notebook中使用如下图,展示了一个模型训练预测,并打印出预测结果的过程:
★ PyAlink 的下载安装
PyAlink提供了下载安装包,需要Python 3.5及以上版本。
https://github.com/alibaba/Alink#%E5%BF%AB%E9%80%9F%E5%BC%80%E5%A7%8B--pyalink-%E4%BD%BF%E7%94%A8%E4%BB%8B%E7%BB%8D
★ PyAlink的使用
我们在github上放了5个示例,为ipynb格式,大家可以直接运行体验。
https://github.com/alibaba/Alink/tree/master/pyalink
这里也通过动画形式,展示一组PyAlink的使用示例:
高效的迭代计算框架
我们也开源了Alink的中间函数库,它是在我们基于Flink开发机器学习算法,不断优化性能的过程中总结和积累下来的。对于Flink社区的算法开发者会有非常大的帮助,可以基于我们的中间函数库,快速地开发出新的算法,而且相对于直接使用Flink的基本接口开发,性能上会有成倍的提升。
中间函数库中最重要的是 Iterative Communication/Computation Queue (简称ICQ),是我们面向迭代计算场景总结的一套迭代通信计算框架,它集成了内存缓存技术和内存数据通信技术。我们把每个迭代步抽象为多个ComQueueItem(通信模块与计算模块)串联形成的队列。 相对于Flink基础的IterativeDataSet有显著的性能提升,而且代码量相当,可读性更强。
ComQueueItem包括计算和通信两种类型。同时,ICQ还提供了初始化功能,用于将DataSet缓存到内存中,缓存的形式包括Partition和Broadcast两种形式。前者将DataSet分片缓存至内存,后者将DataSet整体缓存至每个worker的内存。默认支持了AllReduce通信模型。此外,ICQ还允许指定迭代终止条件。
DataSet <Row> model = new IterativeComQueue() .initWithPartitionedData(OptimVariable.trainData, trainData) .initWithBroadcastData(OptimVariable.model, coefVec) .initWithBroadcastData(OptimVariable.objFunc, objFuncSet) .add(new PreallocateCoefficient(OptimVariable.currentCoef)) .add(new PreallocateCoefficient(OptimVariable.minCoef)) .add(new PreallocateLossCurve(OptimVariable.lossCurve, maxIter)) .add(new PreallocateVector(OptimVariable.dir, new double[] {0.0, OptimVariable.learningRate})) .add(new PreallocateVector(OptimVariable.grad)) .add(new PreallocateSkyk(OptimVariable.numCorrections)) .add(new CalcGradient()) .add(new AllReduce(OptimVariable.gradAllReduce)) .add(new CalDirection(OptimVariable.numCorrections)) .add(new CalcLosses(OptimMethod.LBFGS, numSearchStep)) .add(new AllReduce(OptimVariable.lossAllReduce)) .add(new UpdateModel(params, OptimVariable.grad, OptimMethod.LBFGS, numSearchStep)) .setCompareCriterionOfNode0(new IterTermination()) .closeWith(new OutputModel()) .setMaxIter(maxIter) .exec();
案例
案例1、情感分析
情感分析是对带有情感色彩(褒义贬义/正向负向)的主观性文本进行分析,以确定该文本的观点、喜好、情感倾向。这个案例中,我们对一个酒店评论的数据集进行分析。
https://raw.githubusercontent.com/SophonPlus/ChineseNlpCorpus/master/datasets/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv
首先,我们定义一个pipeline,这个pipeline包含了缺失值填充、中文分词、停用词过滤、文本向量化、逻辑回归等组件。
接着,我们使用上述定义的pipeline进行模型训练、批式预测,以及结果评估。
采用不同的文本向量化方式和分类模型,可以迅速直观地比较模型的效果:
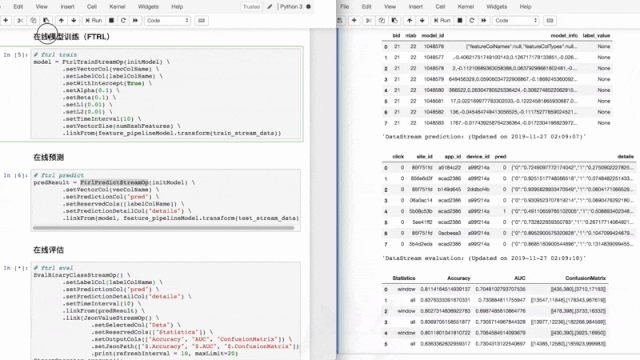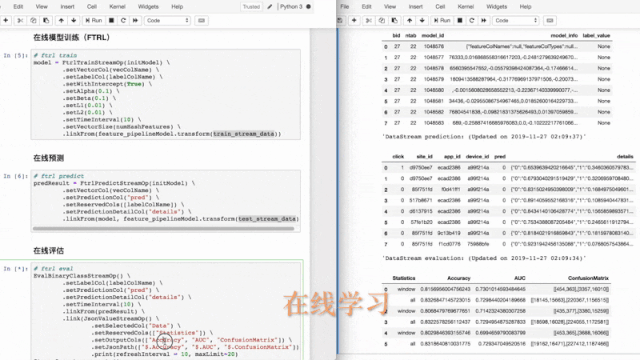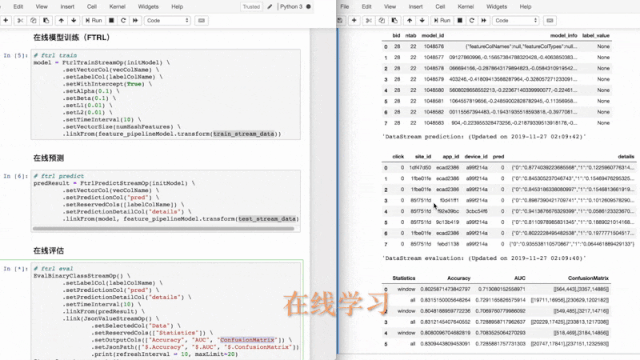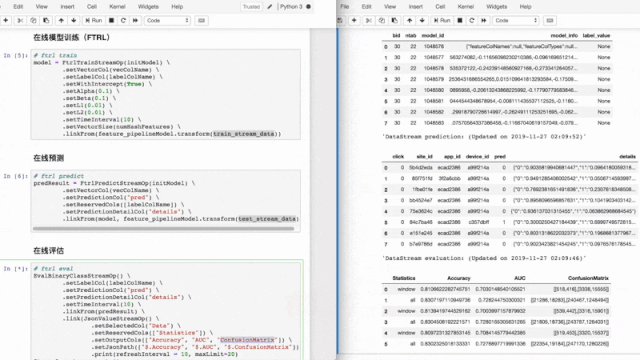
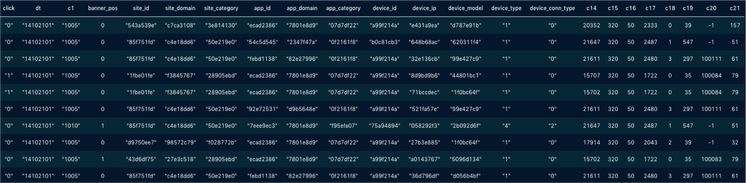
案例2、FTRL在线学习
在网络广告中,点击率(CTR)是衡量广告效果的一个非常重要的指标。因此,点击预测系统在赞助搜索和实时竞价中具有重要的应用价值。该 Demo 使用 Ftrl 方法实时训练分类模型,并进行实时预测和实时评估。
https://www.kaggle.com/c/avazu-ctr-prediction/data
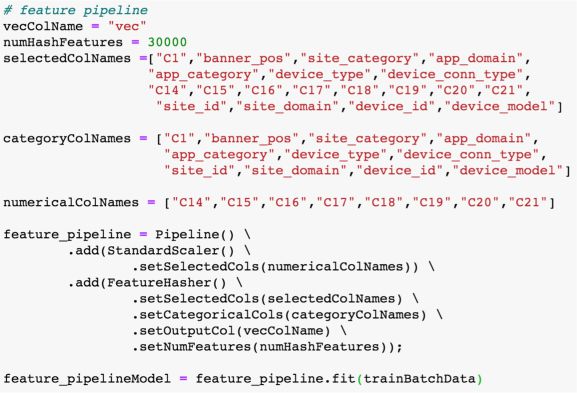
首先,我们搭建一个用于做特征工程的pipeline,它由标准化和特征哈希两个组件串联而成,并通过训练得到一个pipeline model。
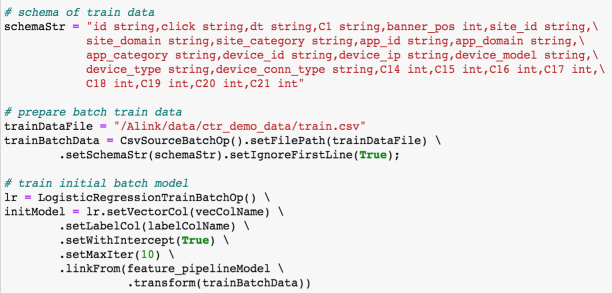
其次,我们用逻辑回归组件进行批式训练,得到一个初始模型。
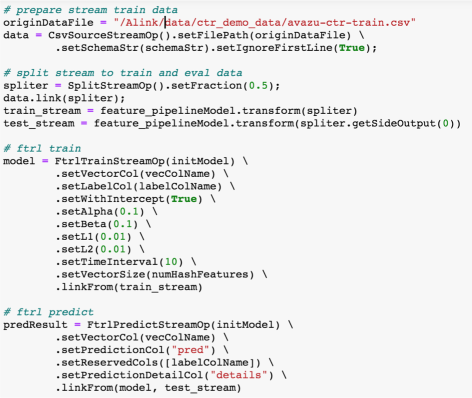
接着,我们使用FTRL训练组件进行在线训练,用FTRL预测组件进行在线预测。
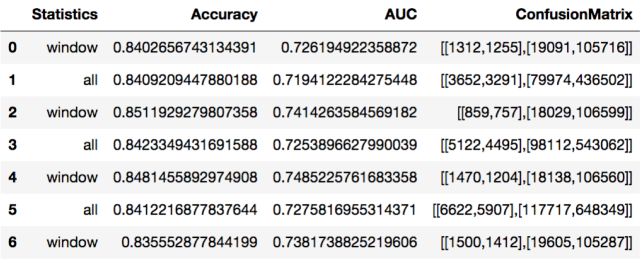
评估结果可实时展现在notebook,方便开发人员实时监控模型状况。
未来的规划
Alink迈出了开源的第一步,接下来我们会继续和社区合作,根据用户的反馈,在功能、性能、易用性等方面,发展完善Alink,解决Flink用户在使用机器学习算法方面的问题;另一方面,我们还会继续积极向FlinkML提交算法代码,后面贡献进展比较顺利的情况下,Alink 应该能完全合并到 FlinkML,也就是直接进入 Flink 生态的主干,这对于 Alink 来说是最好的归宿,到这个时候 FlinkML 就可以跟 SparkML 完全对应起来了。
我们衷心的希望更多的人加入,一起把Apache Flink开源社区做得更好!
长按识别二维码,立刻报名
去年Flink Forward China峰会上,阿里宣布将开源Blink,一年后的今天,阿里是否兑现了去年所作的承诺?Blink的合并工作进展如何?识别下方二维码或点击文末“阅读原文”立即查看。















文章评论