
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
本文是 InfoQ“解读 2019”年终技术盘点系列文章之一。
从 TIOBE Index 来看,Go 语言最近在全球的热度似乎有所下滑。不过,如果看总体排名的话,截止到 2019 年的 12 月,Go 语言依然排在第 15 位,仍处于主流之列。虽然中途存在一些起落,但总体上还是与去年同期持平的。
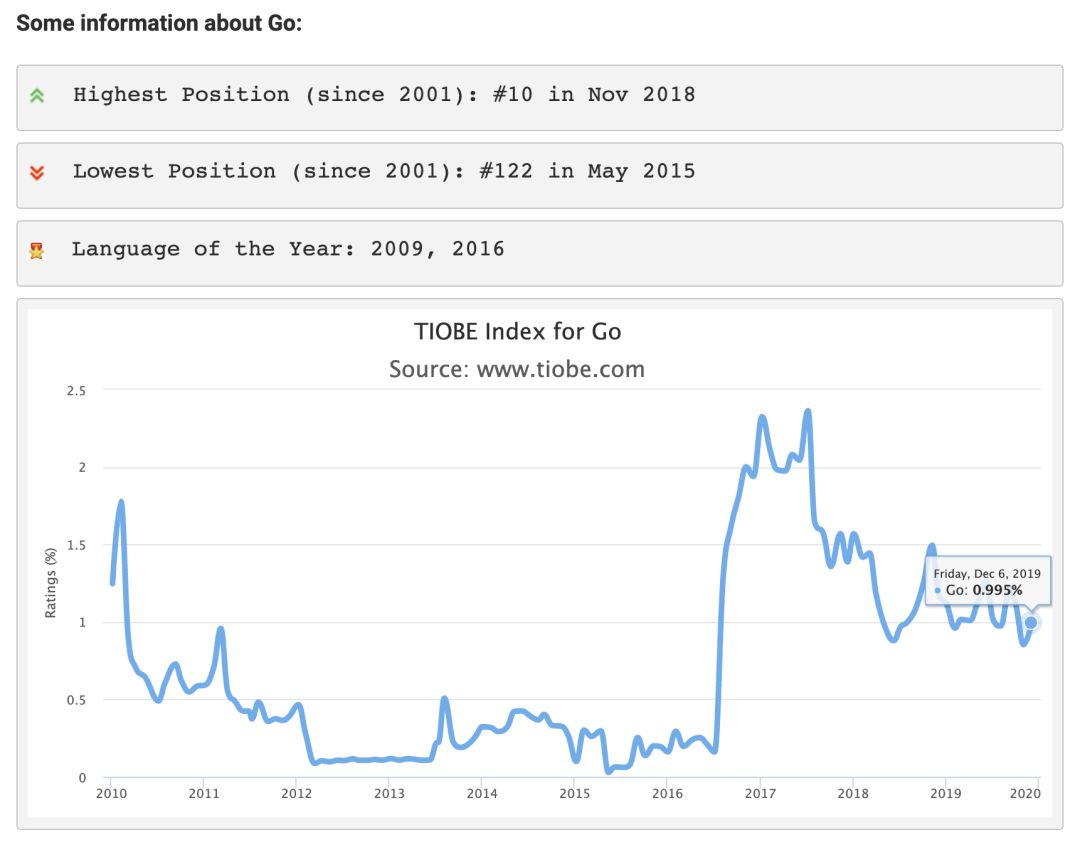 图 1:TIOBE Index 之 Go 语言(2019 年 12 月)
图 1:TIOBE Index 之 Go 语言(2019 年 12 月)
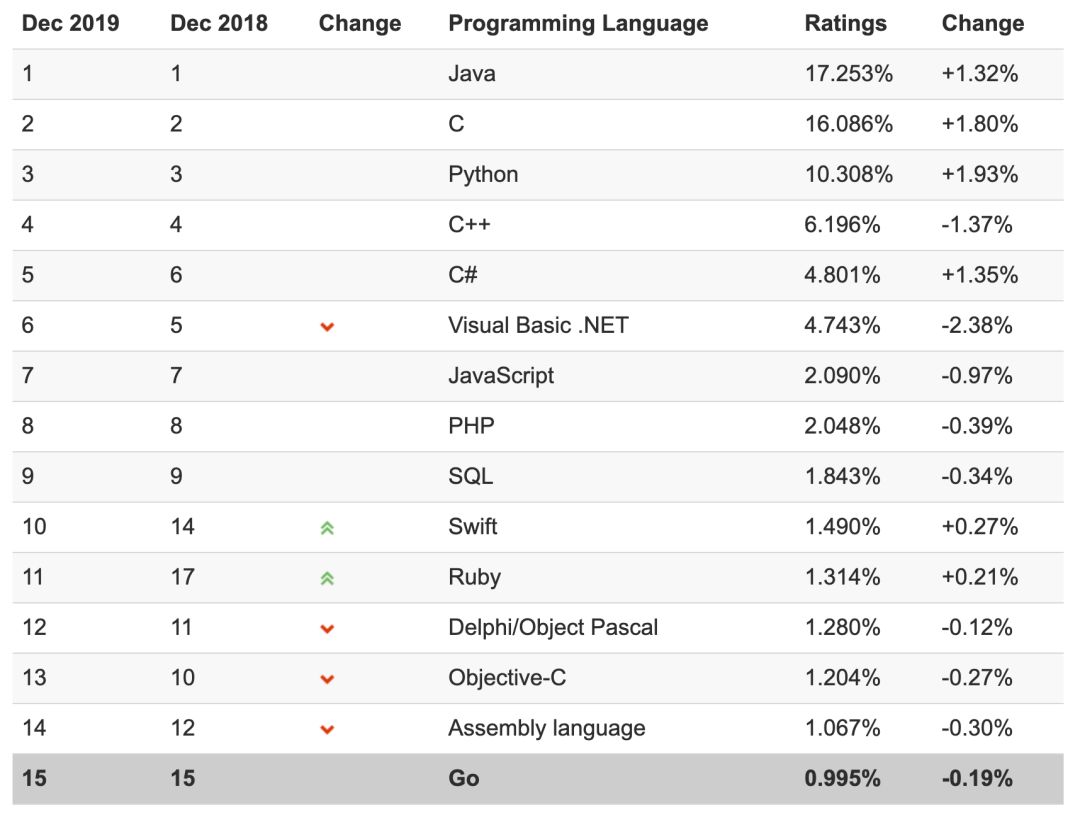 图 2:TIOBE Index(2019 年 12 月)
图 2:TIOBE Index(2019 年 12 月)
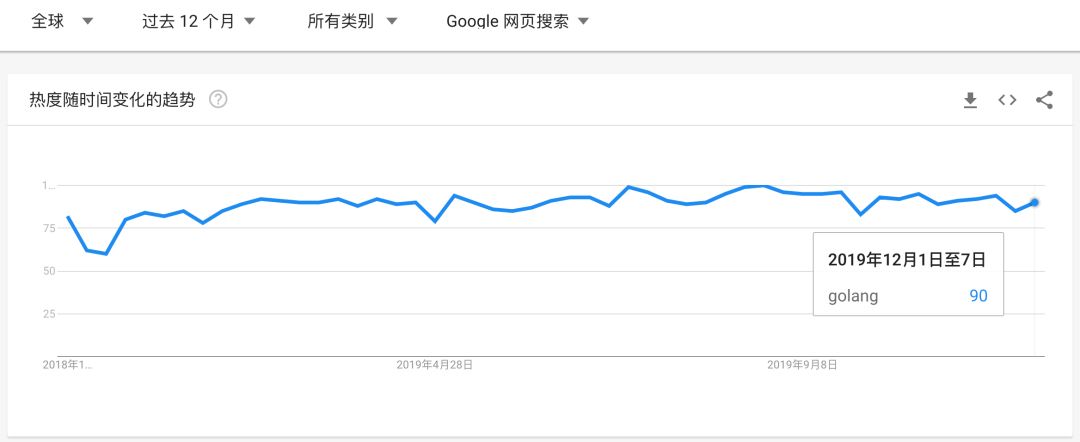 图 3:Google Trends 之 Go 语言趋势(2019 年 12 月)
图 3:Google Trends 之 Go 语言趋势(2019 年 12 月)
如果我们把目光聚焦在国内,那么就可以看到,北京依然是 Go 语言使用者的主要聚集地,没有之一。但不得不说,深圳、杭州、成都、上海、广州等城市也有很多优秀的 Go 程序开发者。
 图 4:Google Trends 之 Go 语言热度(2019 年 12 月)
图 4:Google Trends 之 Go 语言热度(2019 年 12 月)从我的观察来看,Go 语言已经过了第二波快速推广期,并且进入了稳定发展期,起码在国内是这样。已经在使用 Go 语言的技术团队逐渐开始专注于埋头写代码,而刚开始使用 Go 语言的团队也没有进行大肆的宣传。Go 语言已经悄悄地变成了我们的家常便饭。
Go 语言目前所擅长的领域仍然在服务端的 Web 系统、API 网关、中间件、缓存系统,以及数据库、容器技术和云计算等方面。在这些方面,我们有非常多的框架可以选择。其中最受欢迎的框架和软件如下:
-
Web 框架:Gin、Beego、Echo 等。
-
微服务框架:go-kit、go-micro 等。 -
数据库连接库:go-sql-driver/mysql、go-redis/redis、mongo-go-driver、go-elasticsearch,以及 gorm、xorm 等。 -
中间件软件:etcd、Consul、NSQ、Caddy 等。 -
数据库软件:TiDB、Cockroach、InfluxDB、Cayley 等。 -
数据爬取软件:Pholcus、Colly 等。
此外,还有大名鼎鼎的 Kubernetes 及其生态圈中的那些知名项目。更多的优秀 Go 语言项目可以参考我在极客时间专栏 《Go 语言核心 36 讲》 中的思维导图。如果你只是想知道国内的 Go 程序开发者都发布了哪些开源项目,那么也可以参考我发起的 awesome-go-China 项目。
另一方面,对于那些面向企业的管理系统,Go 语言更是不在话下。在最近发布的一份 2019 年十大企业级编程语言榜单 中,Go 语言排在第 4 位。在它前面的只有 JavaScript、Java 和 Python 这三门历史悠久的编程语言。由于 Go 语言在软件的开发、构建、测试、部署等方面做得都非常好,所以它对于企业级软件研发来说也有很强的竞争力。
当然了,Go 语言明显不擅长的领域也有几个。虽然 Go 语言已经对一些移动端和嵌入式设备有所支持,但终归还未成熟。 况且,在这些方面至今还没有出现过杀手级别的应用项目。如果非要找出来一个的话,我觉得只有 Gobot 项目才够资格。另外,Go 语言在科学计算、数据科学、机器学习等领域的介入依旧非常少。对于作为前沿中的前沿的人工智能,Go 语言也少有涉足。 我目前只知道有一个用于科学计算的 Gonum 项目发展得还算可以。不过,不要忘了,人工智能以及将来会与之相伴的物联网依然需要服务端软件、需要云计算。而 Go 语言早已在这里站稳了脚跟。
最后,我们再来说一说区块链。区块链的名声源自数字货币。而数字货币之乱从未停息过。所以,区块链在人们的心中早已不那么纯洁了。恐怕它已经成为了计算机软件领域的哈姆雷特。几乎每一个知道区块链的人在谈论到它的时候心里都会描绘着不同的情景。尽管如此,一些有情怀的厂商正在使用区块链技术做着造福大众的事情,比如:支付宝、轻松筹等等。不得不说,Go 语言是区块链顶级技术的有力竞争者,而且它也早已成为了区块链领域中必不可少的技术技能。我们在这方面可以选择的平台或框架已经有不少了,如 Go Ethereum、Fabric、Cosmos、Eris 等。另外,还有一些不错的基于区块链技术的数据存储项目,如 CovenantSQL、Sia 等。
在 2019 年,Go 语言的版本已经更新到了 1.13。然而,由于它在语言规范方面已经趋于稳定,所以只有一些小幅变化。其中,与我们最贴近的就是它在数值字面量方面的改进。
Go 语言的数值字面量现在可以通过一些前缀来表明不同的制式了。前缀 0b 和 0o 分别可以用于表示二进制整数和八进制整数,比如 0b1110 代表整数 14,0o770 代表整数 504,等等。而前缀 0x 是之前就有的,它可以用于表示十六进制整数。不过,它现在还可以表示十六进制的浮点数,比如 0x10p+1 代表 32.000000。这实际上属于科学记数法。其中的 p+1 是这个浮点数的指数部分。我们可以在 p 的后面追加正负号和代表指数的十进制整数,以表明需要在前一个部分的基础上再乘以 2 的几次方。因此,p+1 表示需要再乘以 2 的 1 次方。又由于 0x10 代表整数 16,所以 0x10p+1 表示的就是浮点数 32.000000。同理,0x10p+2 代表浮点数 64.000000,而 0x10p-1 代表浮点数 8.000000,以此类推。不仅如此,以上的这些表示法现在也都可以被用来表示虚数,如 1.e+3i 等。
除此之外,Go 语言终于开始支持数字分隔符了!这个改进点虽然小,但却是一个千呼万全的优化。它其实是一个语法糖,让我们可以在一长串的数字之间插入分隔符“_“,以便使人们更加容易地读出或写入这些数字。更赞的是,这个分隔符被插入到哪里都是可以的。比如,对于整数 123456789,我们写成 123_456_789 或者 1_2345_6789 都是没有问题的。甚至,我们还可以在上述的各种表示法中运用这个分隔符,如 0x67_89 和 3.14_15,等等。别担心,虽然这样的数值字面量都包含了这么一个明显的非数字字符,但是却不会影响到 Go 语言对它们的解析。Go 语言会在适当的时候忽略掉其中的分隔符。
这些在数值字面量方面的改进可以让 Go 语言更好的融合到新领域的软件开发当中。比如,我们在开发财务软件和金融系统的时候就很需要这些特性。一方面,这样的字面量可以大大地降低我们在编码时出错的概率。而另一方面,它们还可以明显地提高程序的可读性,从而减少维护者的认知成本和工作量。
Go 语言中的移位操作可以对处在移位运算符左侧的数值(或称操作数)进行二进制移位,移位的具体次数会由处在移位运算符右侧的数值(或称移位计数)决定。下面是一些简单的例子:
operand1 := -2
count1 := 1
fmt.Printf("%d << %d: %d\n", operand1, count1, operand1<<count1)
fmt.Printf("%d >> %d: %d\n", operand1, count1, operand1>>count1)
输出内容:
-2 << 1 // -4
-2 >> 1 // -1
在 Go 1.13 发布之前,移位计数的类型必须是某个无符号的整数类型。对于 Go 的语言规范和具体实现来说,这样做确实可以减少一定的工作量。但是,对于应用程序的开发者而言,这里却隐藏着无法忽略的的工作成本。当我们想把一个整数作为移位计数的时候,必须要保证它的类型是无符号的。如果它不是,那么我们就不得不进行某种手动的类型转换,否则程序在被编译时就会出错。即使这个整数确实是一个正数,也是如此。我相信大多数的程序开发者都会觉得这很麻烦,而且没有必要。
然而,更重要的还不是这个工作量的问题。如果我们在将要进行移位操作的时候强行地把某个负数转换为无符号整数类型的值,那么就很有可能遇到非预期的情况,从而在程序中埋下一个非常不易察觉和定位的 BUG。示例如下:
operand2 := -1
count2 := -8
count2u := uint8(count2)
fmt.Printf("%d << %d: %d\n", operand2, count2u, operand2<<count2u)
输出内容:
-1 << 248: 0
显然,把 -1 向左移位 248 次很可能并不是我们想要的。
鉴于上述原因,Go 语言团队在 Go 1.13 中修正了这个问题。移位计数不再被要求必须是无符号整数类型的值了,只要是整数值就可以。我们可以想象一下,当设定的移位计数小于零时,如果 Go 程序会立即抛出一个运行时恐慌(panic),而不是悄悄地吞没了 BUG 并改变了我们的意图,那么我们是不是会更开心一些呢?因为程序中的 BUG 被更早地暴露了出来,而且 BUG 的定位和修复还都很容易。
顺便说一下,针对移位操作的这一改变使得 Go 语言的一些行为更加一致了。比如,虽然 len 函数一定会把某个正整数作为其结果值,但它的结果类型却是 int。又比如,我们在创建一个切片的时候可以使用 make 函数。虽然它的第二个参数值必须是某个正整数,但是这个参数的类型却也是 int。之所以它们没有通过类型来严格地约束被传递的值,正是因为那可能会催生出一些额外的类型转换代码。我们很难保证对于任何值的类型转换都一定会产生符合预期的结果。况且,这还很可能会掩盖掉一些本来应该暴露出来的错误。
当然了,这一改变也带来了一个新的问题,那就是我们需要自行保证移位计数为正数。不过,这并不困难,也是我们应该做的。而且,当移位计数是由一个常量代表的时候,Go 语言的编译器会先对它进行检查。如果这个常量不是一个正整数,那么程序是不会通过编译的。因此,这个新问题所带来的影响就基本上可以忽略不计了。
我们都知道,基本上所有的编程语言中的常规字典(或者说映射)都属于无序的容器。也就是说,它们的实例都不会对其包含的键值对的先后顺序作出任何的保证。这就意味着,虽然我们可以通过某个键快速地从字典中获取对应的值,但不能指望通过迭代快速地得到这个键值对。因为我们不知道这个键值对会在第几次迭代时被返回。字典的这一特性是由它的内部结构决定的。Go 语言中的字典也是如此。
这就导致了一个问题。我们很难有效地观察字典的即时状态。由于字典迭代的无序性,通过遍历字典进行观察就变成了一种很糟糕的方式。尤其是当字典包含了成千上万个键值对的时候,我们想用肉眼去发现前后两个状态的异同几乎是不可能的。然而,我们若要用程序去自动地识别它们的不同,其效率显然也不会太高。下面举例说明。
我们现在有一个 map[int]string 类型的字典 map1,并且已经以从小到大的顺序放入了一些键值对。其中的键都是一些正整数,而与之对应的值都是键的字符串形式,比如,整数值 1 与字符串值 “1” 会共同组成一个键值对。如此一来,下面的代码就会遍历这个字典并依据迭代的次序打印出其中的各个键值对:
fmt.Printf("Map: [\n ")
for k, v := range map1 {
fmt.Printf("%d:%s ", k, v)
}
fmt.Println("\n]")
输出内容:
Map: [
3:3 4:4 7:7 5:5 6:6 8:8 9:9 0:0 1:1 2:2
]
我们可以看到,打印出来的内容体现的是“乱序”的键值对。正因为如此,我们无法在这里用比较字符串值的方式来比较字典的多个即时状态。我相信,大多数写过 Go 程序测试代码的 gopher 们都为此苦恼过。
好消息是,从 2019 年的 2 月份开始,我们终于对此拥有了一种有效的手段。在 Go 1.12 中,官方团队对 fmt 包中的一系列打印函数进行了优化。这使得它们将会依据键的大小去依次地打印字典中的键值对。相应代码如下:
fmt.Printf("Map: %v\n", map1)
输出内容:
Map: map[0:0 1:1 2:2 3:3 4:4 5:5 6:6 7:7 8:8 9:9]
这个结果就不用我多解释了吧。这些键值对是以升序排列的。不过要注意,字典在被迭代的时候依然会以“乱序”的方式吐出一个个键值对。所以,前一种打印方式所产生的结果依旧。而有序的键值对只会体现在上面这种整体打印的情况下。
让我们再稍微深入一点。在整体打印的过程中,对于不同类型的键,打印函数的比较方式也会有所不同。具体如下:
-
先来说基本类型的键。对于整数值、浮点数值和字符串值,打印函数会利用标准的比较操作进行排序。浮点数中的 NaN 会比其他的浮点数值更小。对于复数值,打印函数会先比较实部再比较虚部。更具体的比较方式同上。而对于布尔值来说,false 肯定是比 true 更小的。
-
对于指针值和通道值,打印函数会去比较它们在内存中的地址。请注意,这里所说的指针值特指通过取址操作符获得的指针值,并不是 uintptr 类型或者 unsafe.Pointer 类型的值。对于 uintptr 类型的键,打印函数会把它们当作整数值去比较。而对于 unsafe.Pointer 类型的键,打印函数根本就无法比较它们。请记住,对一个键类型为 unsafe.Pointer 的字典进行整体打印会引发一个运行时恐慌。
-
对于结构体值和数组值,打印函数会逐一地比较其中的字段值或元素值,直到能够判断出谁大谁小为止。
-
对于接口类型的值,打印函数会先利用反射识别出它们的实际类型,然后再依据上面的规则进行比较。
-
最后,如果字典的键允许为 nil,那么 nil 一定是最小的。
这些比较规则很简单,你肯定花费不了多少时间就可以记住它们。不过,即使你懒得去了解这些细则,也不会妨碍你从中受益。示例代码如下:
// 生成第一个快照。
snapshot1 := fmt.Sprint(map1)
fmt.Printf("Snapshot 1: %s\n", snapshot1)
// 修改 map1:增加一些新的键值对。
for i := max + 1; i <= max+3; i++ {
key1 := i
map1[key1] = genValueBy(key1)
}
// 修改 map1:改动一个已有的键值对。
map1[max-5] = "0"
// 生成第二个快照。
snapshot2 := fmt.Sprint(map1)
fmt.Printf("Snapshot 2: %s\n", snapshot2)
// 直接比较两个快照。
fmt.Printf("Snapshot 2 > Snapshot 1 ? %v\n", snapshot2 > snapshot1)
输出内容:
Snapshot 1: map[0:0 1:1 2:2 3:3 4:4 5:5 6:6 7:7 8:8 9:9]
Snapshot 2: map[0:0 1:1 2:2 3:3 4:4 5:0 6:6 7:7 8:8 9:9 11:11 12:12 13:13]
Snapshot 2 > Snapshot 1 ? false
面对这样整齐的输出,我们即使仅凭肉眼也可以轻易地找出两个快照的不同,不是吗?更何况,这样的输出对于测试或监测程序来说也是非常友好的。
Go 语言中的 error 值看起来很普通。它们的内部结构一般都非常简单,最多也只是会包含一些有助于定位问题的字符串信息罢了。这让我们可以轻易地对这些 error 值进行判断和比较。
不过,这样的 error 值也有一个很明显的缺点,那就是不便追溯。一旦程序出错了,我们总是想第一时间知道问题到底出在了哪里。即使 error 值包含了一些有用的字符串形式的错误信息,我们也往往只能凭借对程序的熟悉程度和以往的程序调试经验去推测出错的原因和具体位置。
不只是这样,当我们得到一个 error 值的时候,它有可能代表的并不是那个原发的错误,而是由程序内部的错误处理代码转发出来的另一个新生成的 error 值。如果那段错误处理代码编写得当的话,这个新生成的 error 值应该会包含一些描述原发错误的信息。但是,它需要包含多少原发错误信息,以及它包含的信息是否真正有用,是没有一个统一的标准的,基本上全凭那段代码的编写者说了算。这种方式显然太松散了,对于代码质量的管理是非常不利的。
也正因为如此,一些 Go 程序的优秀开发者已经在编写更好的错误处理包了。目前业界公认的比较好用的代码包有 github.com/pkg/errors 和 gopkg.in/errgo.v2,等等。
由于开发者们对更好的错误处理标准的渴望以及普遍存在的呼声,Go 语言团队在大约一年以前开始考虑对现有的 errors 包进行改进。终于,在 Go 1.13 中,新的错误处理机制开始被融入到已有的 errors 包里了。下面,我们就来一起看一看这个博众家之所长的新机制是怎样的。
首先,我们在一个 error 值中包含另一个 error 值的做法终于得到了官方的支持。并且,我们现在可以使用一种标准的方式从前者之中拿出后者。例如,我编写了两个错误类型:
// DetailedError 是一个有错误详情的错误类型。
type DetailedError struct {
msg string
}
// Error 会返回 error 的信息。
func (de DetailedError) Error() string {
return de.msg
}
// WrappedError 是一个可包装其他错误的错误类型。
type WrappedError struct {
msg string
inner error
}
// Error 会返回 error 的信息。
func (we WrappedError) Error() string {
return we.msg
}
// Unwrap 会返回被包装的 error 值。
func (we WrappedError) Unwrap() error {
return we.inne
}
我让 DetailedError 类型拥有 Error() string 方法,是为了让它实现 error 接口。Go 程序员肯定都知道这一点。然而,错误类型 WrappedError 不只有 Error() string 方法,还有 Unwrap() error 方法。后者是为了让 errors.Unwrap 函数能够支持 WrappedError 类型的值。
errors.Unwrap 函数就是我在前面提到的那个标准的方式。它可以从一个错误值中取出另一个错误值。但前提是,前者必须拥有 Unwrap() error 方法,并且该方法一定会返回该错误值包含的那个错误值。
基于上面的类型声明,下面的代码会打印出如我们所愿的内容:
err1_1 := errors.New("unsupported operation")
err1_2 := WrappedError{
msg: "operation failed",
inner: err1_1,
}
fmt.Printf("Message(outer error): %v\n", err1_2)
fmt.Printf("Message(inner error): %v\n\n", errors.Unwrap(err1_2))
输出内容:
Message(outer error): operation failed
Message(inner error): unsupported operation
我不知道你有没有发现,这使得我们可以生成一条任意长度的错误链。持有这条错误链的程序可以通过 errors.Unwrap 函数从近端的(或者说最外层的)错误值开始依次地获取到它包含的所有错误值,直到取出最远端的(或者最内层的)那个错误值为止。如此一来,我们就可以一层一层地包装错误值以反映出错误发生时的上下文状态。另一方面,拿到这样的错误值的程序也就有机会知道引发错误的根本原因是什么了。
当然了,我们让错误类型拥有 Unwrap() error 方法不只有这一点好处。这样做也会让 errors.Is 函数和 errors.As 函数开始支持此类型。
errors.Is 函数的签名是 Is(err, target error) bool。它的功能是从 err 以及它直接或间接包含的错误值中寻找等于 target 的值。它会沿着错误链由外及内地对每一个错误值进行判断。一旦找到了相等的错误值,它就会返回 true。如果在遍历完整条错误链之后仍未找到与 target 相等的错误值,那么它就会返回 false。
errors.As 函数的寻找路径与 errors.Is 函数是一样的。只不过,它寻找的是在类型上与目标一致的错误值。从该函数的签名 As(err error, target interface{}) bool 我们就可以了解到,参数 target 虽然会代表某个值,但是这个值的类型才是判断的真正依据。当我们有如下的两个变量:
err2_1 := DetailedError{
msg: "unsupported operation",
}
err2_2 := WrappedError{
msg: "operation failed",
inner: err2_1,
}
那么,调用表达式 errors.Is(err2_2, err2_1) 和 errors.As(err2_2, &DetailedError{}) 返回的值就肯定都会是 true。注意,errors.As 函数的第二个参数值必须是某个错误值的指针值,而不能是错误值本身。否则将会引发一个运行时恐慌。
然而,就算已经落实了这些改进,Go 1.13 中的 errors 代码包也依然处于一个“改进中”的状态。这主要是为了做到循序渐进和保证向后兼容。充分落实了新错误处理机制的代码实际上在 golang.org/x/xerrors 包中。这个代码包在 GitHub 上也有托管,地址是 https://github.com/golang/xerrors。
利用这个代码包,我们可以很方便地让现有的打印函数逐层地打印出一条错误链中的所有错误信息。不过,这就需要我们为错误类型添加更多的方法了。代码如下:
// FormattedError 是可暴露内部错误信息的错误类型。
type FormattedError struct {
msg string
inner error
}
// Error 会返回 error 的信息。
func (fe FormattedError) Error() string {
return fe.msg
}
// Unwrap 会返回被包装的 error 值。
func (fe FormattedError) Unwrap() error {
return fe.inner
}
// Format 会打印格式化后的错误值。
func (fe FormattedError) Format(f fmt.State, c rune) {
xerrors.FormatError(fe, f, c)
}
// FormatError 会返回错误链中的下一个错误值。
func (fe FormattedError) FormatError(p xerrors.Printer) (next error) {
p.Print(fe.Error())
return fe.Unwrap()
}
错误类型 FormattedError 不但拥有 Error 方法和 Unwrap 方法,还拥有 Format 方法和 FormatError 方法。其中,Format 方法是现有的错误处理机制中的一部分,标准的打印函数在打印一个错误值的时候会试图调用该值的 Format 方法以实现打印内容的自定义。
可以看到,FormattedError 类型的 Format 方法中只有一行代码,即:xerrors.FormatError(fe, f, c)。这行代码很关键。因为 xerrors.FormatError 函数会在适当的时候调用参数 fe 及其代表的错误链中的所有错误值的 FormatError 方法(如果有的话)。
显而易见, FormatError 方法是 xerrors 包代表的新错误处理机制所特有的。它应有的功能是,在打印当前的错误值之后返回该值包含的那个错误值。这样的话,只要这些错误值都拥有 FormatError 方法,再加上调用了 xerrors.FormatError 函数的 Format 方法,那么即使是一个普通的打印函数也可以打印出整条错误链中的所有错误信息。请看下面的示例:
err3_1 := DetailedError{
msg: "unsupported operation",
}
err3_2 := WrappedError{
msg: "operation failed",
inner: err3_1,
}
err3_3 := FormattedError{
msg: "operation error",
inner: err3_2,
}
fmt.Printf("Error: %v\n", err3_3)
最后一条打印语句会导致如下内容的输出:
Error: operation error: operation failed
请注意,之所以这行输出内容中没有“unsupported operation”,是因为 WrappedError 类型并没有像 FormattedError 类型那样的 Format 方法和 FormatError 方法。
由于篇幅原因,关于 xerrors 包的更多情况我就不多说了。我们其实完全可以使用 xerrors 包而不用标准库中的 errors 包来创建和处理错误值。这样就可以享有新错误处理机制所带来的全部好处了。
除了上述几个比较重要的改进之外,官方团队在这一年还对 Go 语言做了很多的更新和优化。其中,值得我们特别注意的有:
-
Modules 基本上已经转正了。环境变量 GO111MODULE 的默认值已是 auto。并且,即使代码处在 GOPATH/src 目录下,Modules 机制也会奏效。这就意味着,go 命令在任何情况下都会具有模块感知能力,从而大大地简化了旧代码迁移的工作量。
-
GOPROXY 可以有多个了。环境变量 GOPROXY 的值现在可以是由英文逗号分割的多个地址了,如:GOPROXY=https://goproxy.cn,https://goproxy.io,direct 。Go 的命令行工具在从网络上获取代码包的时候会依次尝试从这些地址下载。
-
TLS 1.3 已成为缺省配置。在代码包 crypto/tls 中,TLS 1.3 已经是缺省的配置了。不过,如果你想继续使用 TLS 1.2,那么可以让环境变量 GODEBUG 的值中包含 tls13=0 。当然了,我是不建议这么做的。而且,这种倒退的选择将在 Go 1.14 中被丢弃。
-
Binary-only packages 以后将不会再受到支持。Go 1.13 将是支持它的最后一个版本。我们也可以称这种包为纯二进制包。如果你还不知道这是什么,那么以后也不用再去了解了。但倘若你正在使用这种包,请尽快作出相应的替换和更改。
-
代码运行的性能又有大幅提升。这包括:defer 语句的性能提高了 30%;sync.Once 类型的 Do 方法快了一倍,互斥锁和读写锁的方法也提速了 10%。Go 运行时中的计时器和 deadline 检查代码更快了,这使得维护网络链接的操作更加高效,并且在多 CPU 的计算机上拥有更好的可扩展性。
至此,我们已经阐述了 Go 语言本身在 2019 年最主要的那些变化。希望这些内容能够对你使用新版本的 Go 语言有所帮助。对于这部分所展示的所有代码,我已经发布到了 GitHub 上,你可以前往 https://github.com/hyper0x/go2019 进行查看。
在我撰写这篇文章的时候,Go 1.14 的开发周期其实早已开始了,甚至其 beta 版本都已经发布了。从目前公开的资料来看,新版本的改进主要还是集中在工具链的易用性和功能性优化、Modules 机制(与早先的 vendor 等机制)的进一步融合、运行时系统的性能优化、测试包的易用性优化、网络安全协议实现的更替等方面。此外,还有很多的问题修复和小幅改进。
当前,除了主打的服务端之外,Go 语言还在向着大前端(主要是 WebAssembly)的方向发力。 而早先被纳入的移动端在 2019 年倒是没有什么大的动作,主要还是对最新版本的 iOS 和 Android 提供了支持。我们当然是希望 Go 语言能在全端都有良好的发展。但这终归是要分清主次的。Go 语言的着力点仍然以 Web 服务程序为中心。我想,在广义的 Go 语言技术社区仍需进一步开放、官方团队的时间和精力依然非常有限的情况下,这也算是一个很好的策略了。
按照原计划,Go 2 应该会以一种比较平滑的方式出现。 关于这一点,我们从官方团队对 errors 代码包的更新方式上就能够看得出来。Go 2 草案 中提到的一些特性在今后的一段时间里可能会陆续的以标准库更新或者新扩展库的形式融入到 Go 1 当中,就像 golang.org/x/xerrors 包那样。如此一来,使用 Go 1 的大部分开发者就都可以提前享受到一些新特性带来的好处了。不得不说,Go 语言在向后兼容方面做得是相当不错的。
大家肯定也能感觉得出来,Go 1 在语言特性和标准库方面已经相当稳定了。我认为,除了逐渐融入 Go 2 的新特性,Go 1 应该不会再有大的变化了, 进一步的优化、改进和完善应该是官方团队在短期内的主要工作。
就我个人而言,虽然 Go 程序在性能方面早已甩掉 Python 好几条街,也早就超过了 Java,但我依然希望它能够进一步地把性能优势发挥到极致,尤其是并发程序方面的性能。另外,我也希望 Go 语言的 Modules 机制、错误处理机制,以及各种监测和调试工具都能够更上一层楼、越来越好用。
由于 Go 语言属于强类型的编译型编程语言,所以它在语法的自由度和上手的便捷度方面还是稍显逊色的。当然了,这件事情有利有弊。每门编程语言都会有自己的权衡。对于团队级别的软件开发,尤其是中大规模团队级别的软件开发来说,严谨的语法是非常有益的。不论怎样,开发者们(包括我)都希望能用更少的代码完成更多的工作,同时程序还要更易于维护,并且保持优良的性能(要求实在是很多啊)。我希望也相信 Go 语言会继续以自己的方式朝着这方面努力和发展。
我断定,在今后的几年中,云计算和大数据仍然会是非常有潜力和有前途的领域。随着 5G 的到来,它们也会为人工智能和物联网提供强有力的支撑。Go 语言目前在云计算领域非常受欢迎。不过,它在大数据领域至今还没有崭露头角。 起码还没有一个杀手级别的应用程序出来。我倒是很盼望能有这样的程序问世,但是这显然不太容易。因为,大数据的生态系统在很早以前就被 Java 平台下的技术霸占了。
最后,虽然 Go 语言肯定是 Google 公司的 Go 语言,但是 Go 语言团队现在显然已经更加的开放了。他们在一步一步地拥抱技术社区,听取社区的意见和建议、参考和采纳社区的想法和技术实现。因此,以这样的态势,我坚信 Go 语言的发展会越来越好,同时对普通的开发者也会越来越友好。相对于 Go 1 的趋于稳定,我相信将在未来发布的 Go 2 绝对会不负众望,也会足够的惊艳。希望到时候会有更多的爱好者来使用这门优秀的编程语言。
Go 1.12 Release Notes: https://golang.org/doc/go1.12
Go 1.13 Release Notes: https://golang.org/doc/go1.13
Go 1.14 Release Notes(DRAFT): https://tip.golang.org/doc/go1.14
Go 1.14 Milestone: https://github.com/golang/go/milestone/95
作者介绍:
郝林,国内知名的 Go 语言技术布道者,GoHackers 技术社群的发起人和组织者。他发布过很多 Go 语言技术教程,包括开源的 《Go 命令教程》、极客时间的付费专栏 《Go 语言核心 36 讲》,以及图灵原创图书 《Go 并发编程实战》,等等。其中的专栏和图书都有数万的订阅者或购买者,而开源教程的 star 数也有数千。目前,他在继续研究和实践各种编程技术和程序设计方法,并在撰写新的、对初学者更加友好的开源教程 《Julia 编程基础》。
QCon 北京 2020 全新起航,来跟业界大牛关注人工智能领域中正在兴起的技术和关键进展,探讨应用于机器学习问题的工程挑战及解决方案。目前大会 7 折报名中,点击【阅读原文】或识别二维码了解更多。有任何问题欢迎联系票务小姐姐 Ring:17310043226(微信同号)

今日荐文
点击下方图片即可阅读

分布式深度学习重大突破!MACH算法仅需25%的内存,速度快10倍

你也「在看」吗??

文章评论