
HACKING.md觉得颇有意思,读完之后觉得对于 runtime 的理解更上一层,于是想着翻译一下。调度器结构
G、M 和 P。哪怕你不写 scheduler 相关代码,你也应当要了解这些概念。G、M 和 P
G 就是一个 goroutine,在 runtime 中通过类型 g 来表示。当一个 goroutine 退出时,g 对象会被放到一个空闲的 g 对象池中以用于后续的 goroutine 的使用(译者注:减少内存分配开销)。M 就是一个系统的线程,系统线程可以执行用户的 go 代码、runtime 代码、系统调用或者空闲等待。在 runtime 中通过类型 m 来表示。在同一时间,可能有任意数量的 M,因为任意数量的 M 可能会阻塞在系统调用中。(译者注:当一个 M 执行阻塞的系统调用时,会将 M 和 P 解绑,并创建出一个新的 M 来执行 P 上的其它 G。)P 代表了执行用户 go 代码所需要的资源,比如调度器状态、内存分配器状态等。在 runtime 中通过类型 p 来表示。P 的数量精确地(exactly)等于 GOMAXPROCS。一个 P 可以被理解为是操作系统调度器中的 CPU,p 类型可以被理解为是每个 CPU 的状态。在这里可以放一些需要高效共享但并不是针对每个 P(Per P)或者每个 M(Per M)的状态(译者注:意思是,可以放一些以 P 级别共享的数据)。G(需要执行的代码)、一个 M(代码执行的地方)和一个 P(代码执行所需要的权限和资源)结合起来。当一个 M 停止执行用户代码的时候(比如进入阻塞的系统调用的时候),就需要把它的 P 归还到空闲的 P 池中;为了继续执行用户的 go 代码(比如从阻塞的系统调用退出的时候),就需要从空闲的 P 池中获取一个 P。g、m 和 p 对象都是分配在堆上且永不释放的,所以它们的内存使用时很稳定的。得益于此,runtime 可以在调度器实现中避免写屏障(译者注:垃圾回收时需要的一种屏障,会带来一些性能开销)。用户栈和系统栈
G 都会有一个相关联的用户栈,用户的代码就是在这个用户栈上执行的。用户栈一开始很小(比如 2K),并且动态地生长或者收缩。M 都有一个相关联的系统栈(也被称为 g0 栈,因为这个栈也是通过 g 实现的);如果是在 Unix 平台上,还会有一个 signal 栈(也被称为 gsignal 栈)。系统栈和 signal 栈不能生长,但是足够大到运行任何 runtime 和 cgo 的代码(在纯 go 二进制中为 8K,在 cgo 情况下由系统分配)。systemstack、mcall 或者 asmcgocall 临时性的切换到系统栈去执行一些特殊的任务,比如:不能被抢占的、不应该扩张用户栈的和会切换用户 goroutine 的。在系统栈上运行的代码隐含了不可抢占的含义,同时垃圾回收器不会扫描系统栈。当一个 M 在系统栈上运行时,当前的用户栈是没有被运行的。getg() 和 getg().m.curg
g,需要使用 getg().m.curg。getg() 虽然会返回当前的 g,但是当正在系统栈或者 signal 栈上执行的时候,会返回的是当前 M 的 g0 或者 gsignal,而这很可能不是你想要的。getg() == getg().m.curg。错误处理和上报
panic,但是有一些情况下,panic 可能导致立即的致命的错误,比如在系统栈中调用或者当执行 mallocgc 时。throw,throw 会打印出 traceback 并立即终止进程。throw 应当被传入一个字符串常量以避免在该情况下还需要为 string 分配内存。根据约定,更多的信息应当在 throw 之前使用 print 或者 println 打印出来,并且应当以 runtime. 开头。GOTRACEBACK=system 或 GOTRACEBACK=crash。同步
mutex,可以使用 lock 和 unlock 来操作。这种方法主要用来短期(长期的话性能差)地保护一些共享的数据。在 mutex 上阻塞会直接阻塞整个 M,而不会和 go 的调度器进行交互。因此,在 runtime 中的最底层使用 mutex 是安全的,因为它还会阻止相关联的 G 和 P 被重新调度(M 都阻塞了,无法执行调度了)。rwmutex 也是类似的。note。note 提供了 notesleep 和 notewakeup。不像传统的 UNIX 的 sleep/wakeup,note 是无竞争的(race-free),所以如果 notewakeup 已经发生了,那么 notesleep 将会立即返回。note 可以在使用后通过 noteclear 来重置,但是要注意 noteclear 和 notesleep、notewakeup 不能发生竞争。类似 mutex,阻塞在 note 上会阻塞整个 M。然而,note 提供了不同的方式来调用 sleep:notesleep 会阻止相关联的 G 和 P 被重新调度;notetsleepg 的表现却像一个阻塞的系统调用一样,允许 P 被重用去运行另一个 G。尽管如此,这仍然比直接阻塞一个 G 要低效,因为这需要消耗一个 M。gopark 和 goready。gopark 挂起当前的 goroutine—— 把它变成 waiting 状态,并从调度器的运行队列中移除 —— 然后调度另一个 goroutine 到当前的 M 或者 P。goready 将一个被挂起的 goroutine 恢复到 runnable 状态并将它放到运行队列中。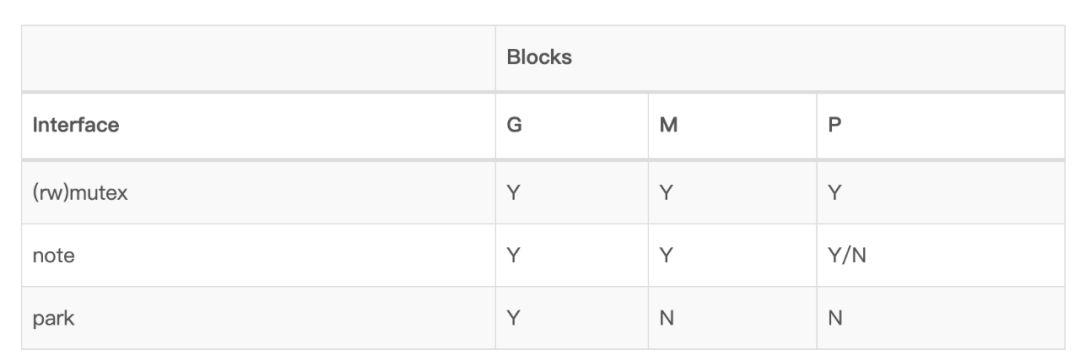
runtime/internal/atomic 中自有的一些原子操作。这个和 sync/atomic 是对应的,除了方法名由于历史原因有一些区别,并且有一些额外的 runtime 需要的方法。-
合理地使用非原子和原子操作使得代码更加清晰可读,对于一个变量的原子操作意味着在另一处可能会有并发的对于这个变量的操作。 -
非原子的操作允许自动的竞争检测。runtime 本身目前并没有一个竞争检测器,但是未来可能会有。原子操作会使得竞争检测器忽视掉这个检测,但是非原子的操作可以通过竞争检测器来验证你的假设(是否会发生竞争)。 -
非原子的操作可以提高性能。
-
大部分操作都是读,且写操作被锁保护的变量。在锁保护的范围内,读操作没必要是原子的,但是写操作必须是原子的。在锁保护的范围外,读操作必须是原子的。 -
仅仅在 STW 期间发生的读操作,且 STW 期间不会有写操作。那么这个时候,读操作不需要是原子的。
Go Memory Model 给出的建议仍然成立 Don't be [too] clever。runtime 的性能固然重要,但是鲁棒性(robustness)却更加重要。堆外内存(Unmanaged memory)
P(译者注:比如在调度器初始化之前,是不存在 P 的)。-
sysAlloc直接从操作系统获取内存,申请的内存必须是系统页表长度的整数倍。可以通过sysFree来释放。 -
persistentalloc将多个小的内存申请合并在一起为一个大的sysAlloc以避免内存碎片(fragmentation)。然而,顾名思义,通过persistentalloc申请的内存是无法被释放的。 -
fixalloc是一个SLAB风格的内存分配器,分配固定大小的内存。通过fixalloc分配的对象可以被释放,但是内存仅可以被相同的fixalloc池所重用。所以fixalloc适合用于相同类型的对象。
//go:notinheap(见后文)。-
所有在堆外内存指向堆上的指针都必须是垃圾回收的根(garbage collection roots)。也就是说,所有指针必须可以通过一个全局变量所访问到,或者显式地使用 runtime.markroot来标记。 -
如果内存被重用了,堆上的指针在被标记为 GC 根并且对 GC 可见前必须 以 0 初始化(zero-initialized,见后文)。不然的话,GC 可能会观察到过期的(stale)堆指针。可以参见下文 Zero-initialization versus zeroing.
Zero-initialization versus zeroing
memclrNoHeapPointers 进行 zero-initialized 或者无指针的写。这不会触发写屏障(译者注:写屏障是 GC 中的一个概念)。typedmemclr 或者 memclrHasPointers 来写入零值,设置为类型安全的状态。这会触发写屏障。Runtime-only 编译指令(compiler directives)
go doc compile 中注明的 //go: 编译指令外,编译器在 runtime 包中支持了额外的一些指令。go:systemstack
go:systemstack 表明一个函数必须在系统栈上运行,这个会通过一个特殊的函数前引(prologue)动态地验证。go:nowritebarrier
go:nowritebarrier 告知编译器如果以下函数包含了写屏障,触发一个错误(这不会阻止写屏障的生成,只是单纯一个假设)。go:nowritebarrierrec。go:nowritebarrier 当且仅当 “最好不要” 写屏障,但是非正确性必须的情况下使用。go:nowritebarrierrec 与 go:yeswritebarrierrec
go:nowritebarrierrec 告知编译器如果以下函数以及它调用的函数(递归下去),直到一个 go:yeswritebarrierrec 为止,包含了一个写屏障的话,触发一个错误。go:nowritebarrierrec 函数出发,直到遇到了 go:yeswritebarrierrec 的函数(或者结束)为止。如果其中遇到一个函数包含写屏障,那么就会产生一个错误。go:nowritebarrierrec 主要用来实现写屏障自身,用来避免死循环。P(getg().m.p != nil),然而调度器相关代码有可能在没有一个活跃的 P 的情况下运行。在这种情况下,go:nowritebarrierrec 会用在一些释放 P 或者没有 P 的函数上运行,go:yeswritebarrierrec 会用在重新获取到了 P 的代码上。因为这些都是函数级别的注释,所以释放 P 和获取 P 的代码必须被拆分成两个函数。go:notinheap
go:notinheap 适用于类型声明,表明了一个类型必须不被分配在 GC 堆上。特别的,指向该类型的指针总是应当在 runtime.inheap 判断中失败。这个类型可能被用于全局变量、栈上变量,或者堆外内存上的对象(比如通过 sysAlloc、persistentalloc、fixalloc 或者其它手动管理的 span 进行分配)。特别的:-
new(T)、make([]T)、append([]T, ...)和隐式的对于T的堆上分配是不允许的(尽管隐式的分配在 runtime 中是从来不被允许的)。 -
一个指向普通类型的指针(除了 unsafe.Pointer)不能被转换成一个指向go:notinheap类型的指针,就算它们有相同的底层类型(underlying type)。 -
任何一个包含了 go:notinheap类型的类型自身也是go:notinheap的。如果结构体和数组包含go:notinheap的元素,那么它们自身也是go:notinheap类型。map 和 channel 不允许有go:notinheap类型。为了使得事情更加清晰,任何隐式的go:notinheap类型都应该显式地标明go:notinheap。 -
指向 go:notinheap类型的指针的写屏障可以被忽略。
go:notinheap 类型真正的好处。runtime 在底层结构中使用这个来避免调度器和内存分配器的内存屏障以避免非法检查或者单纯提高性能。这种方法是适度的安全(reasonably safe)的并且不会使得 runtime 的可读性降低。作者:吴迪
原文:
https://purewhite.io/2019/11/28/runtime-hacking-translate/




文章评论