
一年一度的双十一又要到了,相比往年而言,今年的商家似乎更加“别出心裁”,各种平台纷纷推出开团拉新、瓜分红包等预热项目,游戏规则也是超前复杂。那么商家们精心策划的活动最终起到了什么样的效果,各路买家究竟买不买账?今天这篇文章我们就来一起分析一下。
文章要点:
-
分析百度指数
-
获取微博观点
-
网民情感分析

1
百度指数分析
百度指数是个好东西,它以百度网民行为数据为基础,提供了关键词搜索趋势的基础性分析,使用简单方便,在对事物进行初步的宏观分析时很有帮助。
首先来看双十一关键字的百度搜索指数,这个数据会在每年的11月11日前后达到峰值。从下图中历年数值趋势来看,2015年以前年度峰值呈递增趋势,2015年至2017年趋势相对平稳,2018年该数值出现大幅下降。
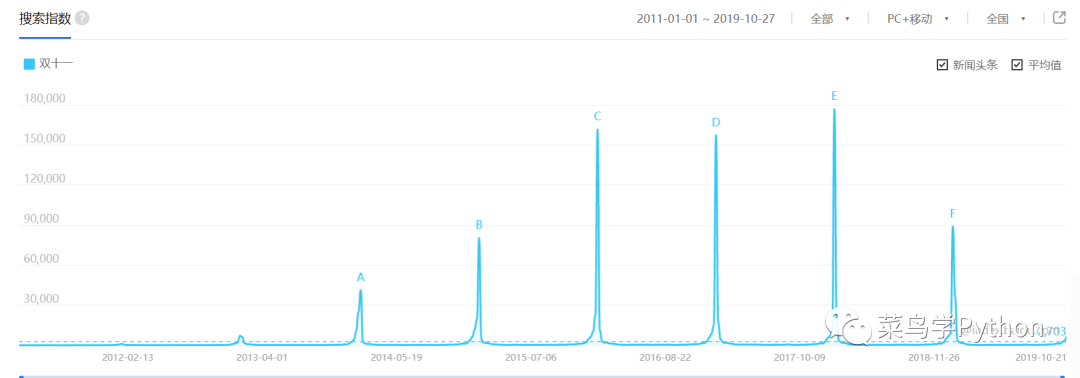
如果按照这个趋势发展,今年的双十一搜索指数峰值将低于2018年的水平,也就意味着大量网民对双十一已经不再那么热情。
当然,这样下结论未免过于武断,我们再来对比下今年和去年的同期数值,从下图中可以看到,在过去的一个周内双十一的搜索指数是6369,而去年的同期数值是6805。从这个角度来说,近期网民对双十一的关注程度要略低于去年
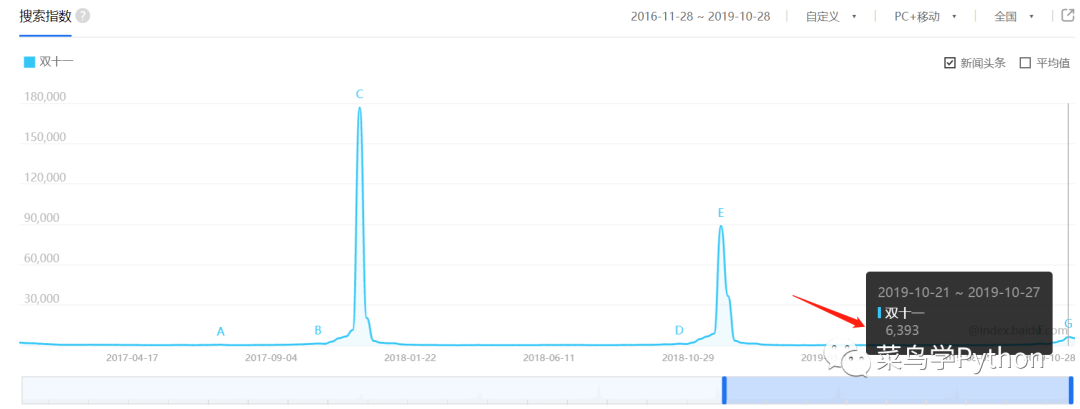
但是从资讯指数来看,今年过去一周的数值(3727558)又要远高于去年的同期水平(下图)。
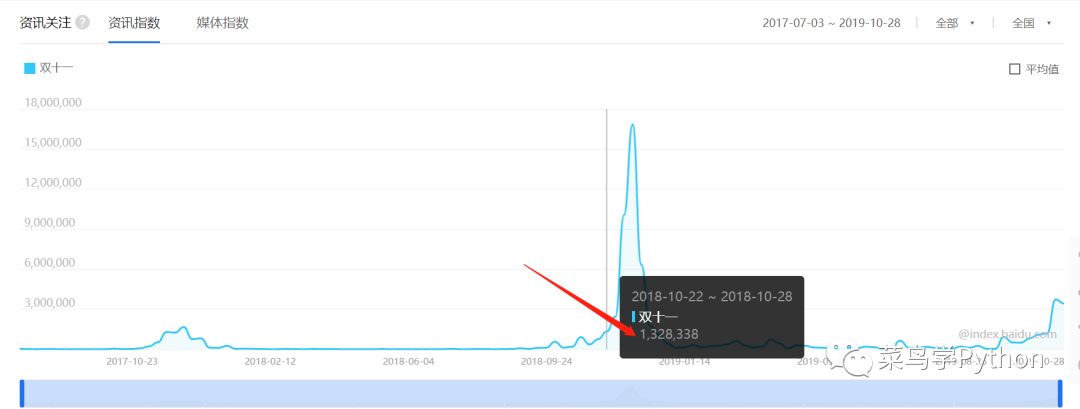
但是,资讯指数包含了网民转发、点赞、不喜欢等所有的相关信息,指数数值高不代表认可度就高,要得到更加精确的结论还需要做进一步的分析。
2
获取微博观点
要看网民对某件事物的看法就要去找各类观点汇集的地方,说起观点的集散地,个人感觉非微博莫属,于是就去微博搜索了下双十一(下图),看看大家都发表了哪些观点。
但是,资讯指数包含了网民转发、点赞、不喜欢等所有的相关信息,指数数值高不代表认可度就高,要得到更加精确的结论还需要做进一步的分析。
随便一搜就找出一大堆评论,其中有表示期待的、有吐槽的、当然也少不了大量的推销和广告,为了进行定量分析,还得把这些评论都爬下来。因为只需要对评论内容进行分析,因此涉及用户ID、发布时间等其他信息我们就不去费力爬取了。
至于如何分析微博页面、如何寻找cookie方面的内容,之前很多大神都写过教程,本文不再详述,下图是经过分析后得到的数据url页面内容,可以看到呈现的是一组json格式的数据,其中的“text”对应的就是评论内容(网页中看到的是编码后的数据,解析后可以得到真实评论内容)。

在爬微博之前提醒大家两点:
-
听说PC端很难搞定,所以我直接尝试了移动端;
-
在爬取的时候务必降低频率,以免给服务器造成太大压力(更重要的是防止被封)。
下面这段代码实现了爬取所有评论内容并存储到txt文本的功能。
headers = {'Cookies':'your cookie',
'User-Agent': 'your user-agent'}
result = ''
try:
for i in range(1, 120):
url = 'https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E5%8F%8C%E5%8D%81%E4%B8%80&page_type=searchall&page={}'.format(i)
j = requests.get(url, headers=headers).json()
for item in j['data']['cards']:
try:
txt = item['mblog']['text']
txt = re.sub('[^\u4e00-\u9fa5]', '-', txt)
result += txt
except:
print('no mblog')
time.sleep(3)
finally:
result = list(filter(None, result.split('-')))
with open('content.txt', 'w') as f:
f.write('|'.join(result))其中,headers中的Cookies和UA需要替换为你自己的信息;爬取评论信息后我们会发现存在大量的特殊符号,为了避免对分析结果产生干扰,直接使用正则表达式筛选出所有中文字符并做规范化处理,一起来看下获取到的评论信息:

以上信息都是以句为单位的评论内容,下面我们用jieba进行分词并制作词云图,看看其中都包含了哪些关键字。

从词云图的分析结果来看,出现频率较高的词语无非是双十一、盖楼、挑战、助力这类词语,仔细查找还会发现一些品牌名称和代言明星,这些词语的出现,要么是商家的广告推送,要么是网友在参加购物活动。
今年双十一的氛围还是很浓厚的,说明仍有很多人对这个网购节抱有期待。
3
评论情感分析
仅仅通过双十一的受关注程度还不足以判断网民的期待值,于是想到利用情感分析来进行更深一步的探索。
随着机器学习和深度学习的迅速发展,自然语言情感分析再也不是少数人的专利,以前我们常说调包侠、调参侠,现在连调参都可以省去,直接调用API就能实现语言的情感分类分析,这次我选用的是一款叫做jiagu的工具。

jiagu的安装只需要一条命令:pip install -U jiagu,通过它可以很方便地开展关键词提取、文本摘要、情感分析等工作,今天只使用其中的情感分析功能。
举个例子,对于很讨厌还是个懒鬼这句话,调用jiagu的sentiment函数进行识别,代码和结果如下:
import jiagu
text = '很讨厌还是个懒鬼'
sentiment = jiagu.sentiment(text)
print(sentiment)
# 输出结果:
# ('negative', 0.9957030885091285)可以看到,输出结果分为两部分,第一个值表示情感倾向,negative表示负面情感、positive代表正面情感;第二个值表示情感强烈程度,取值范围是0~1,数值越接近1说明情感越强烈。
好了,情感分析工具搞定了,现在就来使用它对上文中获取到的评论文字进行观点分析。经过试验发现,jiagu对经由jieba切分后的词语进行情感分类效果并不理想,因此我们采用分词之前的内容作为情感分析的文本。构建核心代码如下:
txt_list = txt.split('|')
posi = 0
nega = 0
for txt in txt_list:
result = jiagu.sentiment(txt)
print(result)
if result[0] == 'negative':
nega += result[1]
elif result[0] == 'positive':
posi += result[1]上面这段代码的基本思想是:对每一句评论内容逐一进行情感分类分析,并将其情感强烈数值累加到对
应的类别标签中(negative或者positive),从而得到微博评论观点的情感分布图:
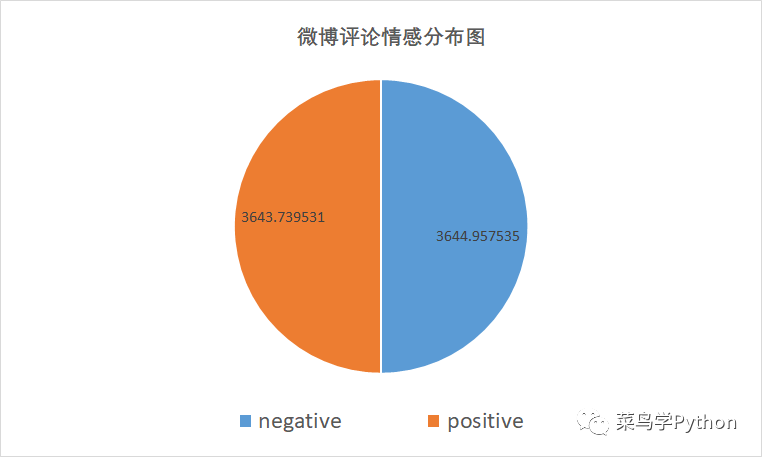
从分析结果来看,正面情绪和负面情绪的比例基本为1:1,负面情绪值甚至要更高一些,看来今年大家对双十一的吐槽力度着实不小啊。
小结:感觉近几年越来越多的人已经认识到了双十一的各种“坑”,但是不得不说有一些商品确实很划算,如何甄别真假优惠对买家来说真心不容易,个人认为有效避坑的最好方法就是不要去买那些当下用不到的东西。
至于今年双十一折扣力度到底如何,我们后面会有一篇文章详细分析,敬请期待哈!
往期热门,好玩有趣:

文章评论