阿里妹导读: Kubernetes 大幅降低了容器化应用部署的门槛,并以其超前的设计理念和优秀的技术架构,在容器编排领域拔得头筹。 越来越多的公司开始在生产环境部署实践。 本文将分享蚂蚁金服是如何有效可靠地管理大规模 Kubernetes 集群的,并会详细介绍集群管理系统核心组件的设计。
系统概览
Kubernetes 集群管理系统需要具备便捷的集群生命周期管理能力,完成集群的创建、升级和工作节点的管理。 在大规模场景下,集群变更的可控性直接关系到集群的稳定性,因此管理系统可监控、可灰度、可回滚的能力是系统设计的重点之一。 除此之外,超大规模集群中,节点数量已经达到 10K 量级,节点硬件故障、组件异常等问题会常态出现。 面向大规模集群的管理系统在设计之初就需要充分考虑这些异常场景,并能够从这些异常场景中自恢复。
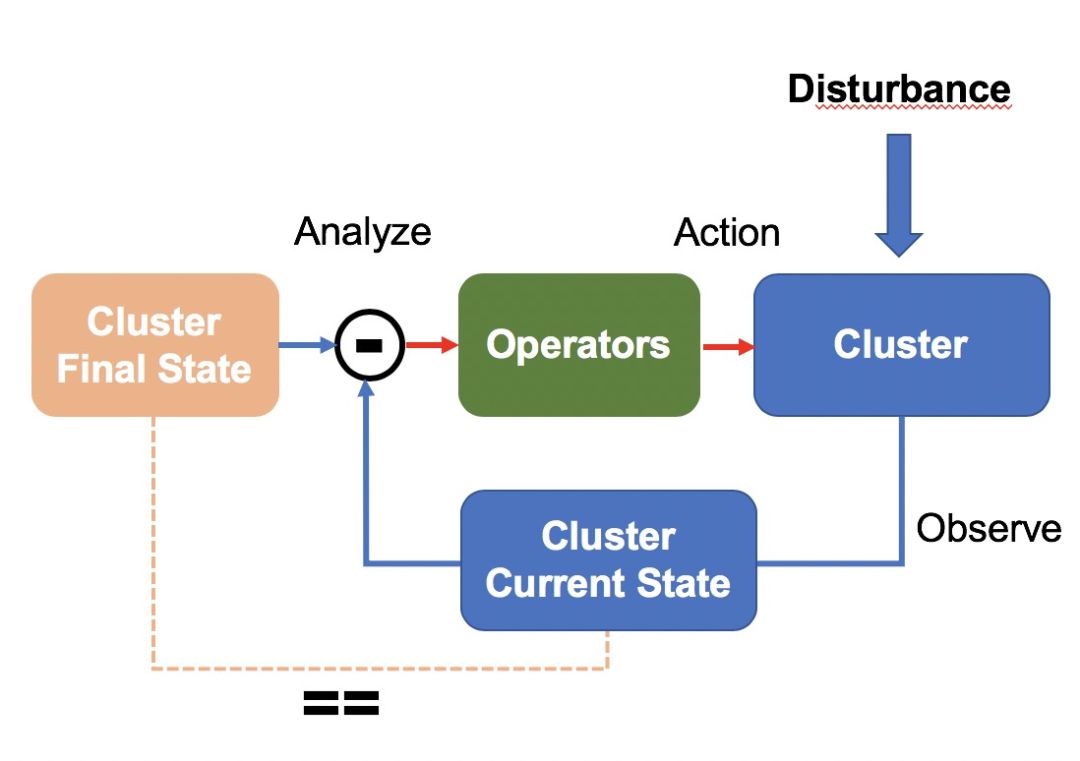
基于这些背景,我们设计了一个面向终态的集群管理系统。 系统定时检测集群当前状态,判断是否与目标状态一致,出现不一致时,Operators 会发起一系列操作,驱动集群达到目标状态。 这一设计参考控制理论中常见的负反馈闭环控制系统,系统实现闭环,可以有效抵御系统外部的干扰,在我们的场景下,干扰对应于节点软硬件故障。
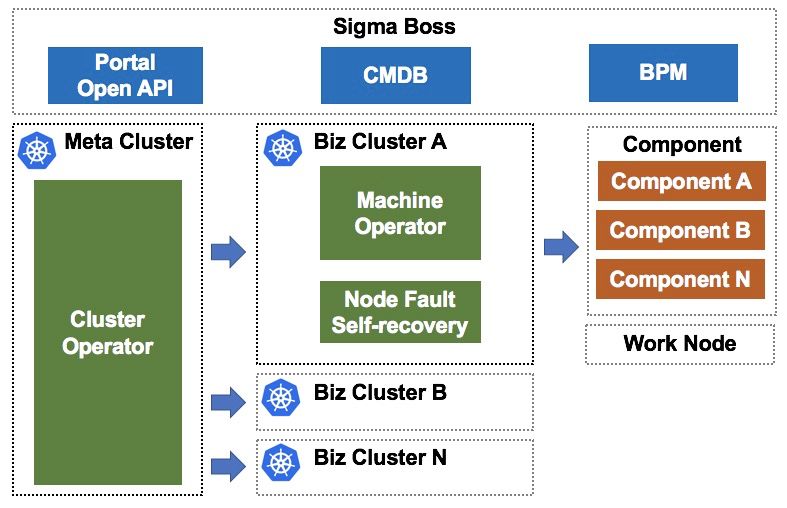
如上图,元集群是一个高可用的 Kubernetes 集群,用于管理 N 个业务集群的 Master 节点。 业务集群是一个服务生产业务的 Kubernetes 集群。 SigmaBoss 是集群管理入口,为用户提供便捷的交互界面和可控的变更流程。 元集群中部署的 Cluster-Operator 提供了业务集群集群创建、删除和升级能力,Cluster-Operator 面向终态设计,当业务集群 Master 节点或组件异常时,会自动隔离并进行修复,以保证业务集群 Master 节点达到稳定的终态。 这种采用 Kubernetes 管理 Kubernetes 的方案,我们称作 Kube on Kube 方案,简称 KOK 方案。 业务集群中部署有 Machine-Operator 和节点故障自愈组件用于管理业务集群的工作节点,提供节点新增、删除、升级和故障处理能力。 在 Machine-Operator 提供的单节点终态保持的能力上,SigmaBoss 上构建了集群维度灰度变更和回滚能力。
基于 K8s CRD,在元集群中定义了 Cluster CRD 来描述业务集群终态,每个业务集群对应一个 Cluster 资源,创建、删除、更新 Cluster 资源对应于实现业务集群创建、删除和升级。 Cluster-Operator watch Cluster 资源,驱动业务集群 Master 组件达到 Cluster 资源描述的终态。 业务集群 Master 组件版本集中维护在 ClusterPackageVersion CRD 中,ClusterPackageVersion 资源记录了 Master 组件(如: api-server、controller-manager、scheduler、operators 等)的镜像、默认启动参数等信息。 Cluster 资源唯一关联一个 ClusterPackageVersion,修改 Cluster CRD 中记录的 ClusterPackageVersion 版本即可完成业务集群 Master 组件发布和回滚。
Kubernetes 集群工作节点的管理任务主要有:
docker / kubelet 等组件安装、升级、卸载;
节点终态和可调度状态管理(如关键 DaemonSet 部署完成后才允许开启调度);
为实现上述管理任务,在业务集群中定义了 Machine CRD 来描述工作节点终态,每一个工作节点对应一个 Machine 资源,通过修改 Machine 资源来管理工作节点。
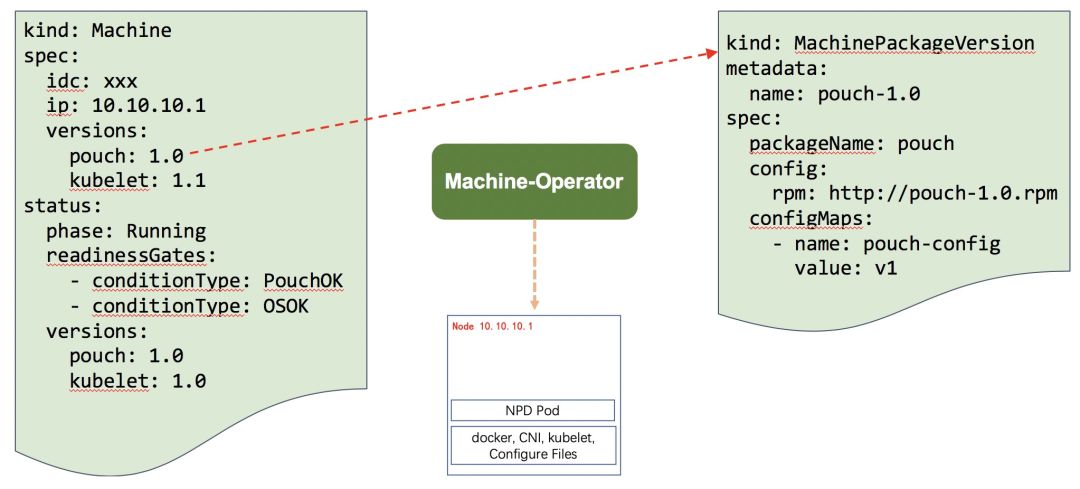
Machine CRD 定义如下图所示,spec 中描述了节点需要安装的组件名和版本,status 中记录有当前这个工作节点各组件安装运行状态。 除此之外,Machine CRD 还提供了插件式终态管理能力,用于与其它节点管理 Operators 协作,这部分会在后文详细介绍。
工作节点上的组件版本管理由 MachinePackageVersion CRD 完成。 MachinePackageVersion 维护了每个组件的 rpm 版本、配置和安装方法等信息。 一个 Machine 资源会关联 N 个不同的 MachinePackageVersion,用来实现安装多个组件。
在 Machine、MachinePackageVersion CRD 基础上,设计实现了节点终态控制器 Machine-Operator。 Machine-Operator watch Machine 资源,解析 MachinePackageVersion,在节点上执行运维操作来驱动节点达到终态,并持续守护终态。
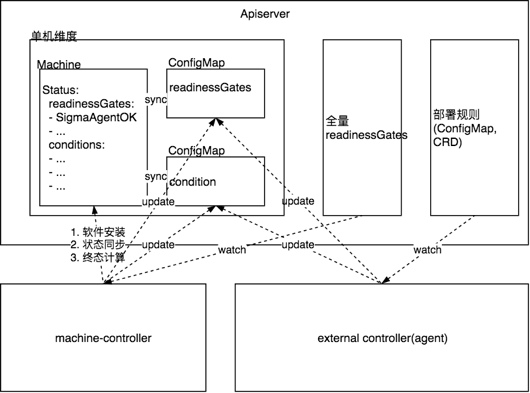
随着业务诉求的变化,节点管理已不再局限于安装 docker / kubelet 等组件,我们需要实现如等待日志采集 DaemonSet 部署完成才可以开启调度的需求,而且这类需求变得越来越多。 如果将终态统一交由 Machine-Operator 管理,势必会增加 Machine-Operator 与其它组件的耦合性,而且系统的扩展性会受到影响。 因此,我们设计了一套节点终态管理的机制,来协调 Machine-Operator 和其它节点运维 Operators。
全量 ReadinessGates: 记录节点可调度需要检查的 Condition 列表;
Condition ConfigMap: 各节点运维 Operators 终态状态上报 ConfigMap;
外部节点运维 Operators 检测并上报与自己相关的子终态数据至对应的 Condition ConfigMap;
Machine-Operator 根据标签获取节点相关的所有子终态 Condition ConfigMap,并同步至 Machine status 的 conditions 中;
Machine-Operator 根据全量 ReadinessGates 中记录的 Condition 列表,检查节点是否达到终态,未达到终态的节点不开启调度。
我们都知道物理机硬件存在一定的故障概率,随着集群节点规模的增加,集群中会常态出现故障节点,如果不及时修复上线,这部分物理机的资源将会被闲置。
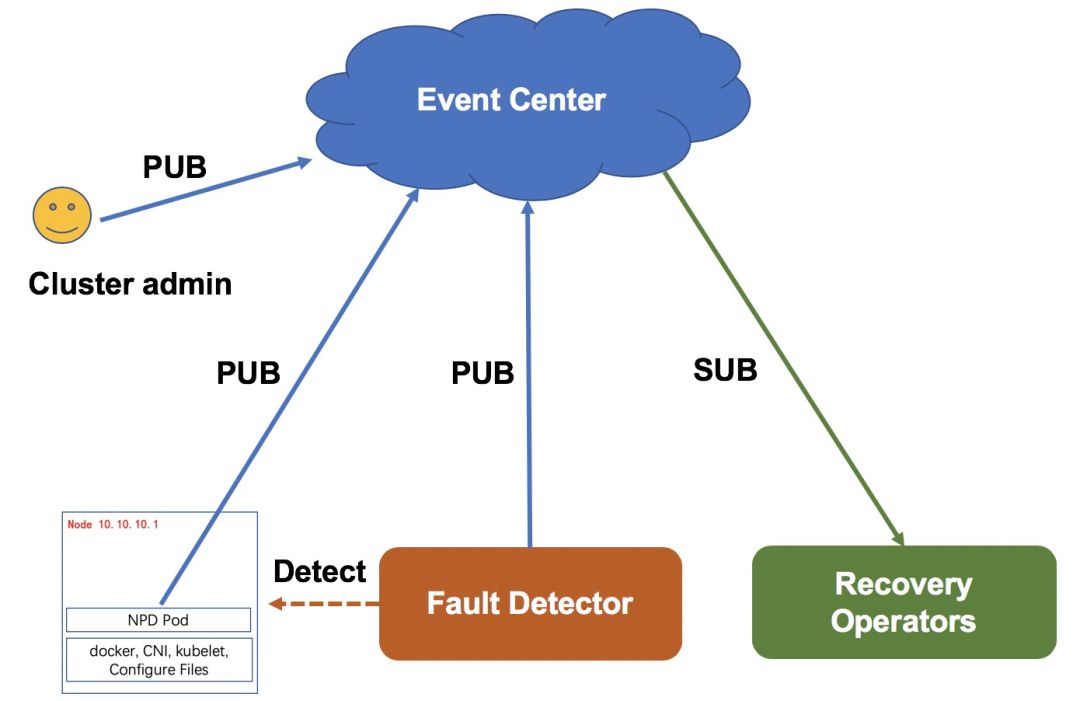
为解决这一问题,我们设计了一套故障发现、隔离、修复的闭环自愈系统。
如下图所示,故障发现方面,采取 Agent 上报和监控系统主动探测相结合的方式,保证了故障发现的实时性和可靠性(Agent 上报实时性比较好,监控系统主动探测可以覆盖 Agent 异常未上报场景)。 故障信息统一存储于事件中心,关注集群故障的组件或系统都可以订阅事件中心事件拿到这些故障信息。
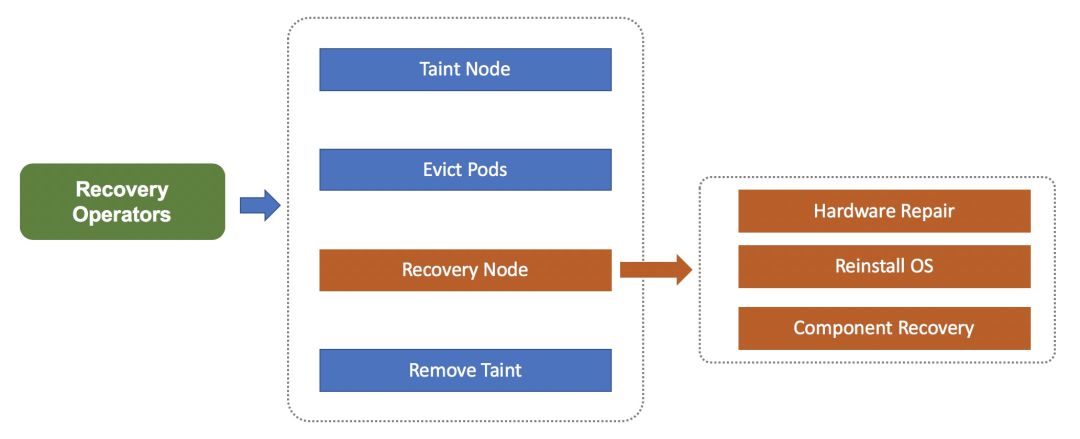
节点故障自愈系统会根据故障类型创建不同的维修流程,例如: 硬件维系流程、系统重装流程等。 维修流程中优先会隔离故障节点(暂停节点调度),然后将节点上 Pod 打上待迁移标签来通知 PaaS 或 MigrateController 进行 Pod 迁移,完成这些前置操作后,会尝试恢复节点(硬件维修、重装操作系统等),修复成功的节点会重新开启调度,长期未自动修复的节点由人工介入排查处理。
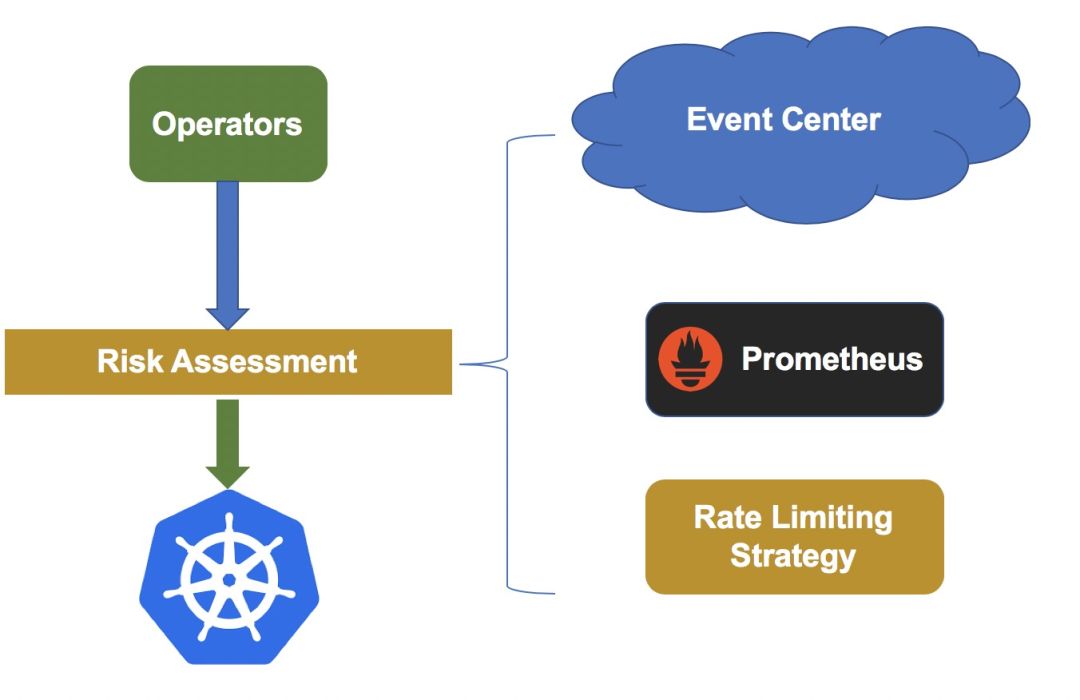
在 Machine-Operator 提供的原子能力基础上,系统中设计实现了集群维度的灰度变更和回滚能力。 此外,为了进一步降低变更风险,Operators 在发起真实变更时都会进行风险评估,架构示意图如下。
高风险变更操作(如: 删除节点、重装系统)接入统一限流中心,限流中心维护了不同类型操作的限流策略,若触发限流,则熔断变更。
为了评估变更过程是否正常,我们会在变更前后,对各组件进行健康检查,组件的健康检查虽然能够发现大部分异常,但不能覆盖所有异常场景。 所以,风险评估过程中,系统会从事件中心、监控系统中获取集群业务指标(如: Pod 创建成功率),如果出现异常指标,则自动熔断变更。
本文主要和大家分享了现阶段蚂蚁金服 Kubernetes 集群管理系统的核心设计,核心组件大量使用 Operator 面向终态设计模式。 这套面向终态的集群管理系统在今年备战双 11 过程中,经受了性能和稳定性考验。
一个完备的集群管理系统除了保证集群稳定性和运维效率外,还应该提升集群整体资源利用率。 接下来,我们会从提升节点在线率、降低节点闲置率等方面出发,来提升蚂蚁金服生产集群的资源利用率。
Q1: 目前公司绝大多数应用已部署在 Docker 中 ,如何向 K8s 转型? 是否有案例可以借鉴? A1: 我在蚂蚁工作了将近 5 年,蚂蚁的业务由最早跑在 xen 虚拟机中,到现在跑在 Docker 里由 K8s 调度,基本上每年都在迭代。 K8s 是一个非常开放的 “PaaS” 框架,如果已经部署在 Docker 中,符合“云原生”应用特性,迁移 K8s 理论上会比较平滑。 蚂蚁由于历史包袱比较重,在实践过程中,为了兼容业务需求,对 K8s 做了一些增强,保证业务能平滑迁移过来。
Q2: 应用部署在 K8s 及 Docker 中会影响性能吗? 例如大数据处理相关的任务是否建议部署到 K8s 中? A2: 我理解 Docker 是容器,不是虚拟机,对性能的影响是有限的。 蚂蚁大数据、AI 等业务都已经在迁移 K8s 与在线应用混部。 大数据类对时间不敏感业务,可以很好地利用集群空闲资源,混部后可大幅降低数据中心成本。 Q3: K8s 集群和传统的运维环境怎么更好的结合? 现在公司肯定不会全部上 K8s。 A3: 基础设施不统一会导致资源没有办法统一进行调度,另外维护两套相对独立的运维系统,代价是非常大的。 蚂蚁在迁移过程中实现了一个“Adapter”,将传统创建容器或发布的指令转换成 K8s 资源修改来做“桥接”。
Q4: Node 监控是怎么做的,Node 挂掉会迁移 Pod 吗? 业务不允许自动迁移呢? A4: Node 监控分为硬件、系统级、组件级,硬件监控数据来自 IDC,系统级监控使用内部自研监控平台,组件(kubelet/pouch 等)监控我们扩展 NPD,提供 exporter 暴露接口给监控系统采集。 Node 出现异常,会自动迁移 Pod。 有些带状态的业务,业务方自己定制 operator 来实现 Pod 自动迁移。 不具备自动迁移能力的 Pod, 超期后会自动销毁。
Q5: 整个 K8s 集群未来是否会对开发透明,使用代码面向集群编程或编写部署文件,不再需要按容器去写应用及部署,是否有这种规划? A5: K8s 提供了非常多构建 PaaS 平台的扩展能力,但现在直接面向 K8s 去部署应用的确非常困难。 我觉得采用某种 DSL 去部署应用是未来的趋势,K8s 会成为这些基础设施的核心。
Q6: 我们目前采用 kube-to-kube 的方式管理集群,kube-on-kube 相比 kube-to-kube 的优势在哪? 在大规模场景下,K8s 集群的节点伸缩过程中,性能瓶颈在哪? 是如何解决的? A6: 目前已经有非常多的 CI/CD 流程跑在 K8s 之上。 采用 kube-on-kube 方案,我们可以像管理普通业务 App 那样管理业务集群的管控。 节点上除运行 kubelet pouch 外,还会额外运行很多 daemonset pod,大规模新增节点时,节点组件会对 apiserver 发起大量 list/watch 操作,我们的优化主要集中在 apiserver 性能提升,和配合 apiserver 降低节点全量 list/watch。
Q7: 因为我们公司还没有上 K8s,所有我想请教以下几个问题: K8s 对我们有什么好处? 能够解决当前的什么问题? 优先在哪些业务场景、流程环节使用? 现有基础设施能否平滑切换到 Kubernetes? A7: 我觉得 K8s 最大的不同在于面向终态的设计理念,不再是一个一个运维动作。 这对于复杂的运维场景来说,非常有益。 从蚂蚁的升级实践看,平滑是可以做到的。
Q8: cluster operator 是 Pod 运行,用 Pod 启动业务集群 master,然后 machine operator 是物理机运行? A8: operator 都运行在 Pod 里面的,cluster operator 将业务集群的 machine operator 拉起来。
Q9: 为应对像双十一这样的高并发场景,多少量级的元集群的规模对应管理多少量级的业务集群合适? 就我的理解,cluster operator 应该是对资源的 list watch,面对大规模的并发场景,你们做了哪些方面的优化? A9: 一个集群可以管理万级节点,所以元集群理论上可以管理 3K+ 业务集群。
Q10: 节点如果遇到系统内核、Docker、K8s 异常,如何从软件层面最大化保证系统正常? A10: 具备健康检查能力,主动退出,由 K8s 发现,并重新在其它节点拉起。
2019天猫双11,成交额2684亿!每秒订单峰值54.4万笔! 识别下方二维码或点击 “阅读原文” 揭秘 双11核心技术 。
1936 0 0 万级规模 K8s 如何管理?蚂蚁双11核心技术公开










文章评论