
一、题外话
已经有好一阵子没有更新爬虫专栏了,并不是猪哥懒,确实是没有灵感。
因为猪哥写文章并不是将所有的功能和方法列一遍而已,我觉得这些大家完全可以在网站找到,所以真的没必要。
我更喜欢的是用一个个鲜活有趣的例子先让大家尝鲜,即使你不懂代码的含义,但是你用着用着就会了,会了之后自己就会想去了解更多,所以猪哥提倡的更是一种引导的方式,而不是教导。
其实刚开始工作也是如此,到新公司一般会让你先装环境,然后就是了解项目,是项目引导你去学习技术。
引导学习是需要我们自己主动学习的,所以我更希望的是我们大家一起参与进来完成这一章的内容,一起来看看这张内容讲什么吧!
二、第三章讲什么
上一章节我们用十来个具体的实战案例讲解了如何使用requests库的爬取,猪哥再强调一遍:requests库 实战非常非常重要,是学习爬虫的实际起步或者说入门的一个库,希望大家已经掌握了requests库的基本用法。
稍微了解一点爬虫的同学应该都知道,爬虫的一个基本流程也逐渐明了:爬取->解析->存储,基本三步走。
所以这一章我们当然是讲如何解析爬取到的数据了(没错,猪哥又要po出那张爬虫图了,哈哈!)。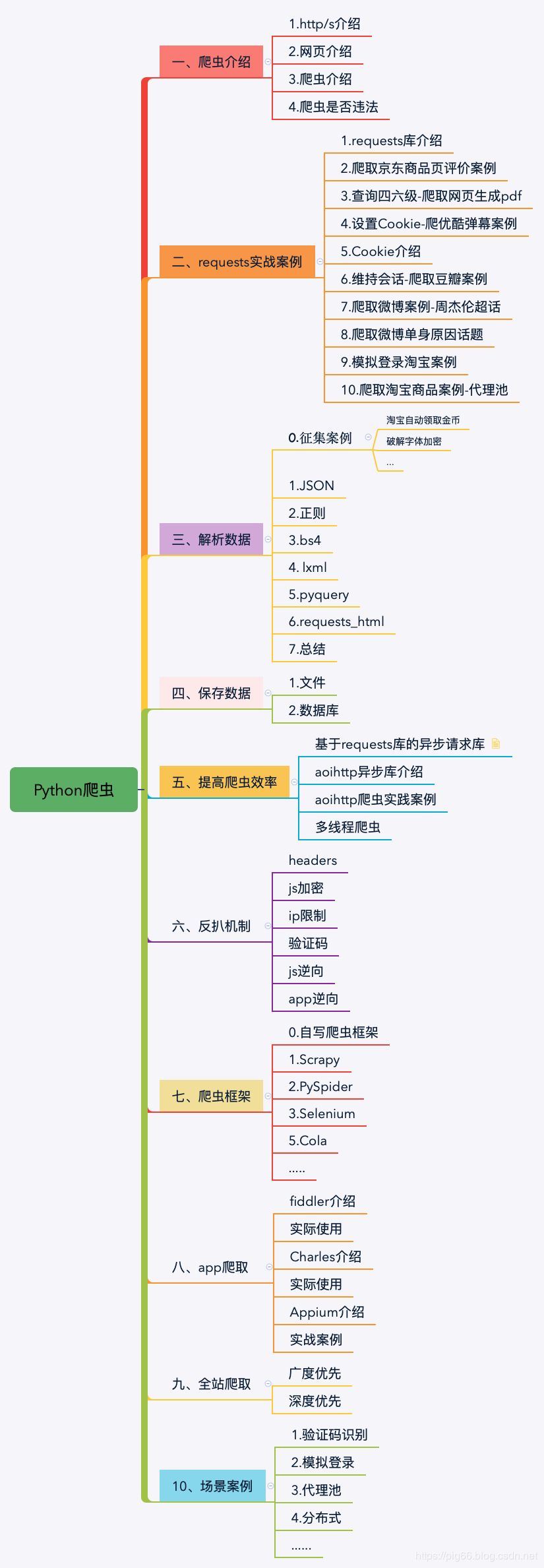
解析库的内容:
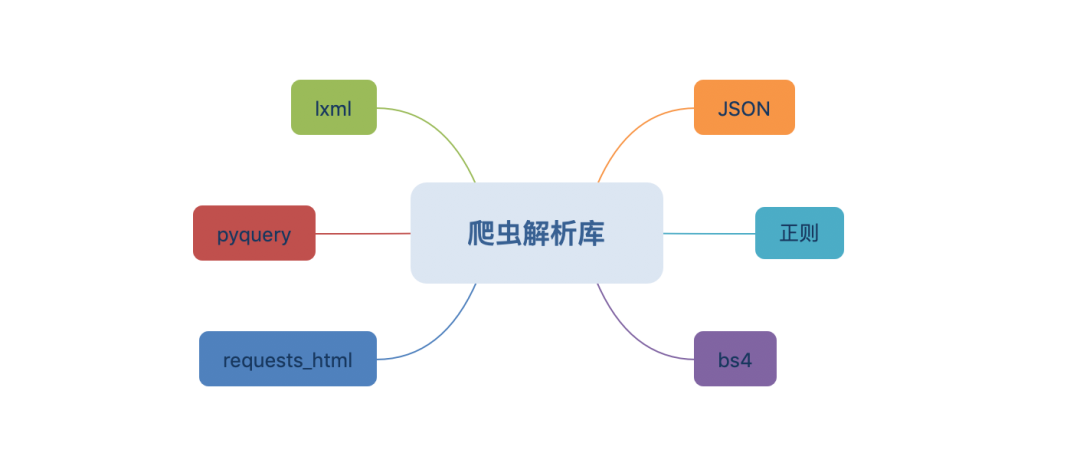
三、解析库
1.征集案例
老粉们看我的文章应该也有一段时间,猪哥的写作风格基本就是:严谨、有趣还有风骚,其实写文章和敲代码并不需要太多的时间,最费时和精力的是去思考实战案例。
前面猪哥说了希望大家一起参与进来完成这章,所以向大家征集有趣的案例或者投稿,投稿方式给大家讲下,在公众号回复:投稿 即可!

之前有很多同学给猪投过搞(再次感谢大家的积极投稿),但绝大部分文章没有被采纳,主要原因还是因为写的不够仔细,很多文章都是简单介绍要做的项目,然后贴代码,写结果,中间的分析过程基本没有。猪哥认为这种文章对新手不够友好,所以没有采纳,还望大家见谅,希望大家能继续支持。
写作对大家技术的成长绝对有帮助,希望有更多的同学投入到写作当中!
所以如果你有好的想法好的案例请在文末留言哦~
2.JSON解析
一般情况下,网站会有纯数据的接口和返回网页的接口之分。因为前后端分离的流行,所以越来越多的纯数据接口了。纯数据接口解析起来也会比网页要简单很多,所以猪哥建议我们在爬取数据的时候优先考虑是否有纯数据接口。
前些年Web数据传输格式更多的可能是XML (eXtensible Markup Language),但是现在JSON(Javascript Object Notation) 已成为Web数据传输的首选,因为JSON相比XML容易阅读、解析更快、占用空间更少、对前端友好。

而且纯JSON数据相对于网页来说解析更加简单,所以猪哥打算先从json开始讲起。
3.网页解析
除了纯JSON数据之外,更多的是返回网页,所以网页解析是一个重要的知识点。
网页解析的库非常多,但是常用的也就那几个,所以猪哥就重点讲几个吧:
-
正则:正则匹配网页内容,但是效率低,局限性大。
-
beautifulsoup4:美味汤,简单易于上手,很多人学的第一个解析库。
-
lxml:XPath标准的实现库,据说解析速度很快。
-
pyquery:听名字就知道语法和jquery相似,对熟悉jquery的同学会是个不错的选择。
-
requests_html:有些同学可能还没听过,这是2018年新出的一个解析库,是requests库作者开发的,很多人相信它会成为主流解析库。
常用解析库大概就这几个,如果你觉得还有其他的好用解析库也欢迎在留言区给出。
四、总结
介绍完解析库之后,我们来一次实际的解析速度实测,这样也不至于人云亦云。还有就是给出每种解析库的实际使用场景。
一起学习吧,向着优秀进击!

文章评论