一、Kubernetes容器监控的标配—Prometheus
1、简介
Prometheus是由SoundCloud开发的开源监控告警系统并且带时序数据库,基于Go语言,是Google BorgMon监控系统的开源版本。2016年,由Google发起的Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation,CNCF)将Prometheus纳入其第二大开源项目。Prometheus在开源社区也十分活跃,在GitHub上拥有两万多Star,并且系统每隔一两周就会有一个小版本的更新。
随着Kubernetes在容器调度和管理上确定领头羊的地位,Prometheus 也成为Kubernetes容器监控的标配。
2、优点
Prometheus的优点有很多,如下所述。
(1)提供多维度数据模型和灵活的查询方式,通过将监控指标关联多个tag,来将监控数据进行任意维度的组合,并且提供简单的PromQL查询方式,还提供HTTP查询接口,可以很方便地结合Grafana等GUI组件展示数据。
(2)在不依赖外部存储的情况下,支持服务器节点的本地存储,通过Prometheus自带的时序数据库,可以完成每秒千万级的数据存储;不仅如此,在保存大量历史数据的场景中,Prometheus可以对接第三方时序数据库如OpenTSDB等。
(3)定义了开放指标数据标准,以基于HTTP的Pull方式采集时序数据,只有实现了Prometheus监控数据格式的监控数据才可以被Prometheus采集、汇总,并支持以Push方式向中间网关推送时序列数据,能更加灵活地应对多种监控场景。
(4)支持通过静态文件配置和动态发现机制发现监控对象,自动完成数据采集。Prometheus目前已经支持Kubernetes、etcd、Consul等多种服务发现机制,可以减少运维人员的手动配置环节,在容器运行环境中尤为重要。
(5)易于维护,可以通过二进制文件直接启动,并且提供了容器化部署镜像。
(6)支持数据的分区采样和联邦部署,支持大规模集群监控。
3、架构
下面简单介绍Prometheus的架构。
Prometheus的基本原理是通过HTTP周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口并且符合Prometheus定义的数据格式,就可以接入Prometheus监控。
如图1-9所示为Prometheus的整体架构图(来自Prometheus官网),展现了Prometheus内部模块及相关的外围组件之间的关系。
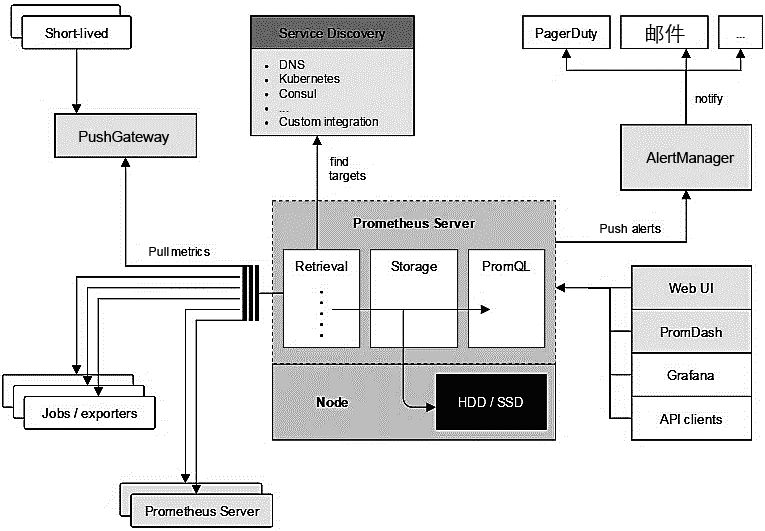
图1-9
PrometheusServer负责定时在目标上抓取metrics(指标)数据,每个抓取目标都需要暴露一个HTTP服务接口用于Prometheus定时抓取。这种调用被监控对象获取监控数据的方式被称为Pull(拉)。Pull方式体现了Prometheus独特的设计哲学与大多数采用了Push(推)方式的监控系统不同。
Pull方式的优势是能够自动进行上游监控和水平监控,配置更少,更容易扩展,更灵活,更容易实现高可用。展开来说就是Pull方式可以降低耦合。由于在推送系统中很容易出现因为向监控系统推送数据失败而导致被监控系统瘫痪的问题,所以通过Pull方式,被采集端无须感知监控系统的存在,完全独立于监控系统之外,这样数据的采集完全由监控系统控制,增强了整个系统的可控性。
Prometheus通过Pull方式采集数据,那么它如何获取监控对象呢?Prometheus支持两种方式:第1种是通过配置文件、文本文件等进行静态配置;第2种是支持ZooKeeper、Consul、Kubernetes等方式进行动态发现,例如对于Kubernetes的动态发现,Prometheus使用Kubernetes的API查询和监控容器信息的变化,动态更新监控对象,这样容器的创建和删除就都可以被Prometheus感知。
Storage通过一定的规则清理和整理数据,并把得到的结果存储到新的时间序列中,这里有两种存储方式。
一种是本地存储。通过Prometheus自带的时序数据库将数据保存到本地磁盘,为了性能考虑,建议使用SSD。但本地存储的容量毕竟有限,建议不要保存超过一个月的数据。
另一种是远端存储,适用于存储大量监控数据。通过中间层的适配器的转化,目前Prometheus支持OpenTSDB、InfluxDB、Elasticsearch等后端存储,通过适配器实现Prometheus存储的remote write和remote read接口,便可以接入Prometheus作为远端存储使用。如图1-10所示展现了Prometheus当前支持的远端数据库。

图1-10
Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持多种方式的图表可视化,例如Grafana、自带的PromDash及自身提供的模版引擎等。Prometheus还提供HTTP API查询方式,自定义所需要的输出。
Prometheus通过Pull方式拉取数据,但某些现有系统是通过Push方式实现的,为了接入这些系统,Prometheus提供了对PushGateway的支持,这些系统主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
AlertManager 是独立于 Prometheus 的一个组件,在触发了预先设置在Prometheus 中的高级规则后,Prometheus 便会推送告警信息到 AlertManager。AlertManager提供了十分灵活的告警方式,可以通过邮件、slack或者钉钉等途径推送。并且AlertManager支持高可用部署,为了解决多个AlertManager重复告警的问题,引入了Gossip,在多个AlertManager之间通过Gossip同步告警信息。
AlertManager的整体工作流程如图1-11所示。
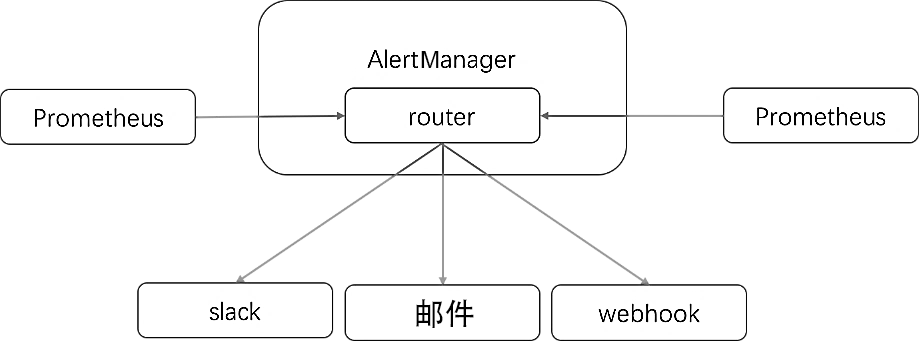
图1-11
二、其他开源监控工具
除了市场上提供的很多SaaS商业工具如监控宝、监控易、听云等,还有一些开源监控工具如Zabbix、Open-Falcon等。
1、Zabbix
Zabbix是由AlexeiVladishev开源的分布式监控系统,支持多种采集方式和采集客户端,同时支持SNMP、IPMI、JMX、Telnet、SSH等多种协议,它将采集到的数据存放到数据库中,然后对其进行分析整理,如果符合告警规则,则触发相应的告警。
Zabbix主要有以下几个核心概念。
主机(Host):是Zabbix监控的对象抽象,每个监控对象都有一个IP地址,这里的主机不仅限于物理服务器,可能是虚拟机容器或者某个网络设备。
主机组(Host Group):是一组主机的集合,主要用于多用户之间的资源隔离,将主机组和用户关联,这样Zabbix的不同用户便只对自己管理的资源可见。
条目(Item):是一个指标的相关监控数据,每个条目都有一个key去标识,以区分不同的指标。
应用(Application):是一组条目的集合,一个条目可以属于一个或多个应用。
模板(Template):是Zabbix里快速配置的利器,用于快速定义被监控主机的预设条目集合,通常包含条目、触发器、视图、应用及服务发现规则,通过将主机关联模板来避免重复配置主机。
触发器(Trigger):是Zabbix的告警规则,用于评估某监控对象在某特定条目内接收到的数据是否匹配阈值,如果匹配,则触发器状态将从OK转变为Problem,当数据量再次回到合理范围时,触发器状态又将从Problem转变为OK。
动作(Action):是Zabbix在某个事件发生后执行的动作。事件主要指告警事件、网络发现新主机加入事件、自动注册(代理)事件和内部事件(监控项不支持);行为主要包括发送邮件通知、执行远程命令或者执行Zabbix的附加动作。
Zabbix的组件图如图1-12所示。
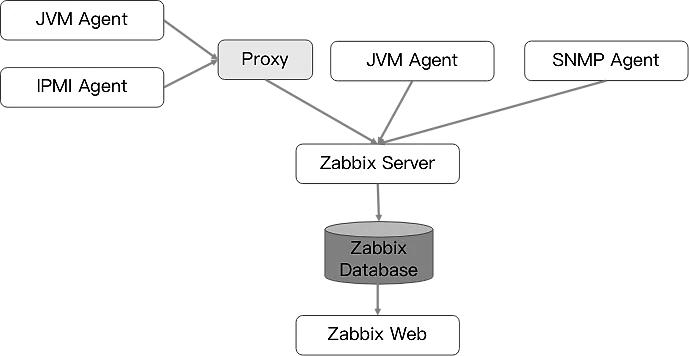
图1-12
如图1-12所示,Zabbix由以下几个组件构成。
1)ZabbixServer
Zabbix的核心组件,由C语言编写而成,主要负责接收Agent发送的监控信息,并进行汇总存储。Zabbix Server需要完成以下三个主要工作。
设备注册。有两种方式可以将监控对象注册到设备中:一种是手动配置Agent地址,但如果需要将机房中的几百台机器一次性加入,则将是很大的工作量;另一种是采用自动发现机制,可以配置整个网段,Server会检测整个网段的主机,并且可以自动配置模板、触发器等一系列相关配置。
数据收集。这里既包括主动采集,也包括被动接收,采集到的数据首先会被放置在内存中,然后被批量保存在数据库中。
定期的数据清理及告警触发。通过配置的触发器匹配采集数据,如果满足条件,则发出告警。
2)Zabbix Database
用于存储所有配置信息,以及由Zabbix收集的监控数据。后端数据库支持MySQL、PostgreSQL、Oracle等,通常用到的是MySQL,并提供ZabbixWeb页面的数据查询方式。由于采用了关系型数据库存储时序数据,所以Zabbix在监控大规模集群时常常在数据存储方面捉襟见肘。
3)Zabbix Web
Zabbix的GUI组件,由PHP编写而成,通常与Server运行在同一台主机上,提供监控数据的展现和系统配置,主要配置包括监控模板、告警等。
4)Proxy
可选组件,常用于分布式监控环境中,代理Server收集部分被监控端的监控数据并按照一定的频率统一发往Server端。
Proxy有自己的数据库,引入Proxy主要是为了解决以下两个问题。
Server和Agent之间网络不连通,这种情况在跨网络、跨机房的场景中经常出现。
在大规模部署时减轻Server的压力,毕竟在同时连接这么多Agent时,Server需要维护更多的连接。以Proxy模式进行部署时,Agent配置的上游地址是Proxy,而Proxy配置的是Server。
5)Agent
部署在被监控主机上,负责收集本地数据并发往Server端或Proxy端,Agent会启动一个名为Agentd的守护进程。
Agent分为两种模式:主动和被动。主动是指Agent主动采集数据并将数据发送到Server/Proxy;被动是指Server每次都主动调用Agent获取数据。Agent还能执行用户的自定义脚本,从而完成一些原生Agent不具备的功能。
这里补充讲解Zabbix的一个工具,即Zabbix_sender。Zabbix_sender是一个命令行工具,可用于主动向Zabbix服务端发送监控数据,这样可避免Agent一直等待监控任务完成。有意思的是,Zabbix 本身由一个商业团队维护,该团队免费提供Zabbix软件,但收取支持和维护费用。这和Red Hat的思路如出一辙,在系统软件日趋成熟的未来,软件的商业模式将逐步从出售许可证转变为收取服务费用,这也是大势所趋。
2、Nagios
Nagios原名为NetSaint,由Ethan Galstad开发并维护。Nagios是一个老牌监控工具,由C语言编写而成,主要针对主机监控(CPU、内存、磁盘等)和网络监控(SMTP、POP3、HTTP和NNTP等),当然也支持用户自定义的监控脚本,如图1-13所示。
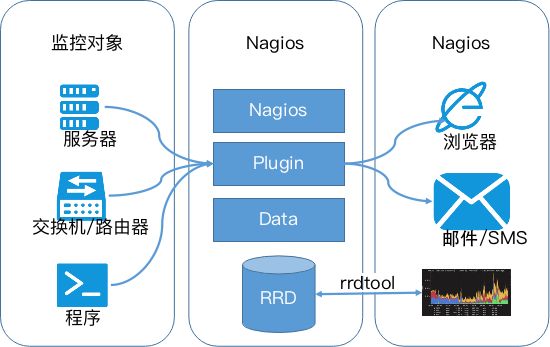
图1-13
Nagios的整体架构非常清晰,它通过Plugin采集各种监控数据,例如针对SNMP监控时,通过SNMP plugin和在监控对象上运行的snmpd通信获取网络信息;它还支持一种更加通用和安全的采集方式NRPE(Nagios RemotePluginExecutor),它首先在远端启动一个NRPE守护进程,用于在远端主机上面运行检测命令,在Nagios服务端用check nrep的plugin插件通过SSL对接到NRPE守护进程,执行相应的监控行为。相比SSH远程执行命令的方式,这种方式更加安全。当然,Nagios也支持SSH的Plugin。
Nagios数据被保存在RDD(Round Robin Database,环形数据库)中,RDD适用于存储时序数据,支持以下4种监控数据。
gauge:仪表盘数据。
counter:计数器。
absolute:不同时间段的变化率,为正数。
driver:变化率,指当前值和前一个监控数值的比值,有正有负。
RDD的存储原理比较简单,它把整个数据存储空间构建成圆环,指针指向最新的数据位置并且会随着数据读写移动,如果此时没有获取监控数据,RDD就会使用默认的unknown填充,保证数据对齐。每个数据库文件都以.rdd结尾,大小是固定的,如图1-14所示。
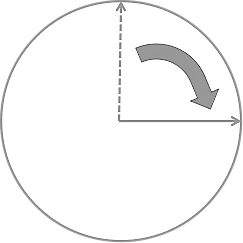
图1-14
3、Open-Falcon
Open-Falcon是小米开源的企业级监控工具,由Go语言开发而成,包括小米、滴滴、美团等在内的互联网公司都在使用它,是一款灵活、可扩展并且高性能的监控方案,整体架构如图1-15所示。
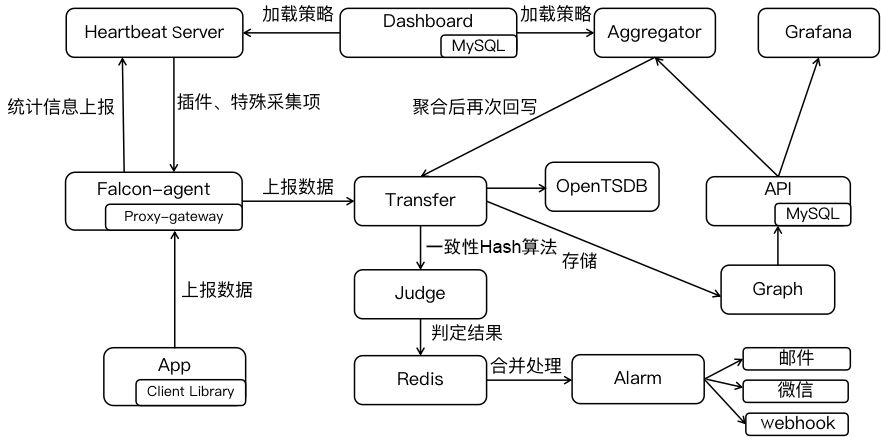
图1-15
下面对如图1-15所示的组件进行简单介绍。
Falcon-agent:用Go语言开发的Daemon程序,运行在每台Linux服务器上,用于采集主机上的各种指标数据,主要包括CPU、内存、磁盘、文件系统、内核参数、Socket连接等,目前已经支持200多项监控指标。并且,Agent支持用户自定义的监控脚本,脚本必须返回Agent指定的数组格式。Agent采集的数据会通过RPC方式上报到Transfer。为了避免单个Transfer发生故障,Agent支持配置多个Transfer地址,还可以忽略多余的监控指标。Agent本身也可以成为一个Proxy-gateway代理网关,接收第三方HTTP请求并将其转发到Transfer中。
Hearthbeat server:简称HBS(心跳服务),每个Agent都会周期性地通过RPC方式将自己的状态上报给HBS,主要包括主机名、主机IP、Agent版本和插件版本,Agent还会从HBS获取自己需要执行的采集任务和自定义插件。
Transfer:负责接收Agent发送的监控数据,并对数据进行整理,在过滤后通过一致性Hash算法将数据发送到Judge或者 Graph。为了支持存储大量的历史数据,Transfer还支持OpenTSDB。Transfer本身没有状态,可以随意扩展。
Judge:告警模块,Transfer转发到Judge的数据会触发用户设定的告警规则,如果满足,则会触发邮件、微信或者回调接口。这里为了避免重复告警,引入了Redis暂存告警,从而完成告警合并和抑制。
Graph:RRD数据上报、归档、存储的组件。Graph在收到数据以后,会以RRDtool的数据归档方式存储数据,同时提供RPC方式的监控查询接口。
API:主要提供查询接口,不但可以从Graph里读取监控数据,还可以对接MySQL,用于保存告警、用户等信息。
Dashboard:由Python开发而成,提供Open-Falcon的数据和告警展现,监控数据来自Graph,Dashboard允许用户自定义监控面板。
Aggregator:聚合组件,聚合某集群下所有机器的某个指标的值,提供一种集群视角的监控体验。通过定时从Graph获取数据,按照集群聚合产生新的监控数据并将监控数据发送到Transfer。
监控系统的对比
下面针对Prometheus、Zabbix、Nagios和Open-Falcon这几种监控系统进行横向对比,如表1-1所示。
表1-1
|
监控系统 |
开发语言 |
成熟度 |
扩展性1 |
高性能 |
社区活跃度 |
对容器的支持 |
企业使用情况 |
|
Zabbix |
C +PHP |
高 |
高 |
低 |
中 |
低 |
高 |
|
Nagios |
C |
高 |
中 |
中 |
低 |
低 |
低 |
|
Open-Falcon |
Go |
中 |
高 |
高 |
中 |
中 |
中 |
|
Prometheus |
Go |
中 |
高 |
高 |
高 |
高 |
高 |
从开发语言上看,为了应对高并发和快速迭代的需求,监控系统的开发语言已经慢慢从C转移到Go。
不得不说,Go凭借简洁的语法和优雅的并发,在Java占据业务开发领域、C占领底层开发领域的情况下,准确定位中间件开发需求,在当前的开源中间件产品中被广泛应用。
从系统成熟度方面来看,Zabbix和Nagios都是老牌的监控系统:Zabbix是在1998年出现的,Nagios是在1999年出现的,系统功能比较稳定,成熟度较高。而Prometheus和Open-Falcon都是最近几年才诞生的,虽然功能还在不断迭代、更新,但它们站在巨人的肩膀之上,在架构设计上借鉴了很多老牌监控系统的经验。
从系统扩展性方面来看,Zabbix和Open-Falcon都可以自定义各种监控脚本。Zabbix不仅可以做到主动推送,还可以做到被动拉取;Prometheus则定义了一套监控数据规范,并通过各种exporter扩展系统采集能力。
从数据存储方面来看,Zabbix采用关系数据库存储数据,这极大限制了Zabbix的数据采集性能。Nagios和Open-Falcon都采用了RDD数据存储方式。Open-Falcon还加入了一致性 Hash 算法进行数据分片,并且可以对接到OpenTSDB,而且Prometheus自研的一套高性能时序数据库,在V3版本时可以达到每秒千万级别的数据存储,可通过对接第三方时序数据库扩展对历史数据的存储性能。
从社区活跃度方面来看,目前Zabbix和Nagios的社区活跃度比较低,尤其是Nagios,Open-Falcon的社区虽然也比较活跃,但基本都是国内的公司在参与。Prometheus的社区活跃度很高,并且得到CNCF的支持,后期的发展值得期待。
从容器支持方面来看,由于Zabbix和Nagios出现得比较早,当时容器还没有诞生,所以它们对容器的支持自然也比较差。Open-Falcon虽然提供了容器监控功能,但支持力度有限。Prometheus的动态发现机制,不仅支持Swarm原生集群,还支持Kubernetes容器集群监控,是目前容器监控的最佳解决方案。Zabbix在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势。Nagios则在网络监控方面有广泛应用。伴随着容器的发展,Prometheus开始成为容器监控方面的标配,并将被广泛应用。总体来说,Prometheus可以说是目前监控领域最锋利的“瑞士军刀”了。
本文节选自《深入浅出Prometheus:原理、应用、源码与拓展详解》一书。陈晓宇,杨川胡,陈啸编著,由电子工业出版社博文视点出版,已获得授权。

↓↓ 点击"阅读原文" 【加入云技术社区】
相关阅读:
想要DevOps自动化吗?它是pipeline前的profile
更多文章请关注

文章好看点这里更[好看]?

文章评论