点击上方“AI有道”,选择“星标”公众号
重磅干货,第一时间送达
本文转载自量子位
“土地,快告诉俺老孙,俺的金箍棒在哪?”
“大圣,您的金箍,棒就棒在特别适合您的发型。”
中文分词,是一门高深莫测的技术。不论对于人类,还是对于AI。
北大开源了一个中文分词工具包,名为PKUSeg,基于Python。
工具包的分词准确率,远远超过THULAC和结巴分词这两位重要选手。

△ 我们 [中出] 了个叛徒
除此之外,PKUSeg支持多领域分词,也支持用全新的标注数据来训练模型。
准确度对比
这次比赛,PKUSeg的对手有两位:
一位是来自清华的THULAC,一位是要“做最好的中文分词组件”的结巴分词。它们都是目前主流的分词工具。
测试环境是Linux,测试数据集是MSRA (新闻数据) 和CTB8 (混合型文本) 。
结果如下:
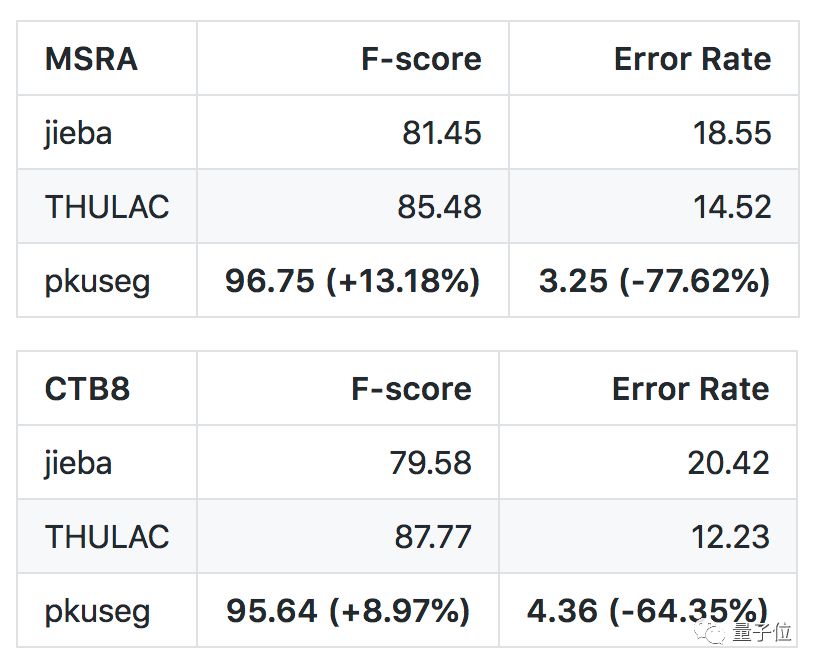
比赛用的评判标准,是第二届国际汉语分词评测比赛提供的分词评价脚本。
在F分数和错误率两项指标上,PKUSeg都明显优于另外两位对手。
食用方法
预训练模型
PKUSeg提供了三个预训练模型,分别是在不同类型的数据集上训练的。
一是用MSRA (新闻语料) 训练出的模型:
https://pan.baidu.com/s/1twci0QVBeWXUg06dK47tiA二是用CTB8 (新闻文本及网络文本的混合型语料) 训练出的模型:
https://pan.baidu.com/s/1DCjDOxB0HD2NmP9w1jm8MA三是在微博 (网络文本语料) 上训练的模型:
https://pan.baidu.com/s/1QHoK2ahpZnNmX6X7Y9iCgQ

△ 微博语料举栗
大家可以按照自己的需要,选择加载不同的模型。
除此之外,也可以用全新的标注数据,来训练新的模型。
代码示例
1代码示例1 使用默认模型及默认词典分词
2import pkuseg
3seg = pkuseg.pkuseg() #以默认配置加载模型
4text = seg.cut('我爱北京天安门') #进行分词
5print(text)
1代码示例2 设置用户自定义词典
2import pkuseg
3lexicon = ['北京大学', '北京天安门'] #希望分词时用户词典中的词固定不分开
4seg = pkuseg.pkuseg(user_dict=lexicon) #加载模型,给定用户词典
5text = seg.cut('我爱北京天安门') #进行分词
6print(text)
1代码示例3
2import pkuseg
3seg = pkuseg.pkuseg(model_name='./ctb8') #假设用户已经下载好了ctb8的模型并放在了'./ctb8'目录下,通过设置model_name加载该模型
4text = seg.cut('我爱北京天安门') #进行分词
5print(text)如果想自己训练一个新模型的话:
1代码示例5
2import pkuseg
3pkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20) #训练文件为'msr_training.utf8',测试文件为'msr_test_gold.utf8',模型存到'./models'目录下,开20个进程训练模型欲知更详细的用法,可前往文底传送门。
快去试一下
PKUSeg的作者有三位,Ruixuan Luo (罗睿轩),Jingjing Xu (许晶晶) ,以及Xu Sun (孙栩) 。
工具包的诞生,也是基于其中两位参与的ACL论文。
准确率又那么高,还不去试试?
GitHub传送门:
https://github.com/lancopku/PKUSeg-python
论文传送门:

http://www.aclweb.org/anthology/P12-1027

http://aclweb.org/anthology/P16-2092
推荐阅读
(点击标题可跳转阅读)
重磅!AI 有道学术交流群成立啦
扫描下方二维码,添加 AI有道小助手微信,可申请入林轩田机器学习群(数字 1)、吴恩达 deeplearning.ai 学习群(数字 2)。一定要备注:入哪个群(1 或 2 或 1+2)+ 地点 + 学校/公司 + 昵称。例如:1+上海+复旦+小牛。

长按扫码,申请入群
(添加人数较多,请耐心等待)
最新 AI 干货,我在看 

文章评论