点击蓝色“程序猿DD”关注我
回复“资源”获取独家整理的学习资料!
原文链接:https://prometheus.io/docs/concepts/metric_types/
Prometheus 的客户端库中提供了四种核心的指标类型。但这些类型只是在客户端库(客户端可以根据不同的数据类型调用不同的 API 接口)和在线协议中,实际在 Prometheus server 中并不对指标类型进行区分,而是简单地把这些指标统一视为无类型的时间序列。不过,将来我们会努力改变这一现状的。
Counter(计数器)
Counter 类型代表一种样本数据单调递增的指标,即只增不减,除非监控系统发生了重置。例如,你可以使用 counter 类型的指标来表示服务的请求数、已完成的任务数、错误发生的次数等。counter 主要有两个方法:
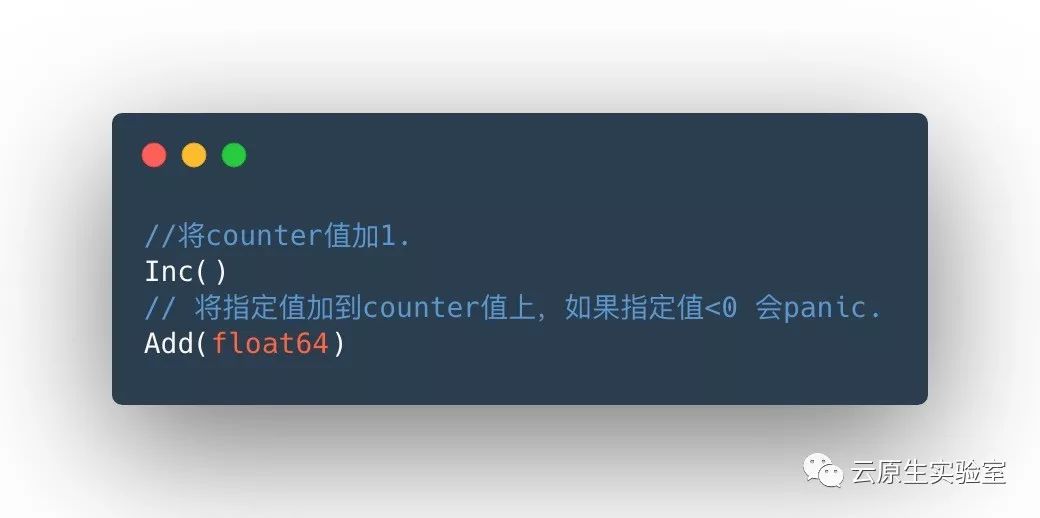
Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在 PromQL 内置的相关操作函数可以提供相应的分析,比如以 HTTP 应用请求量来进行说明:
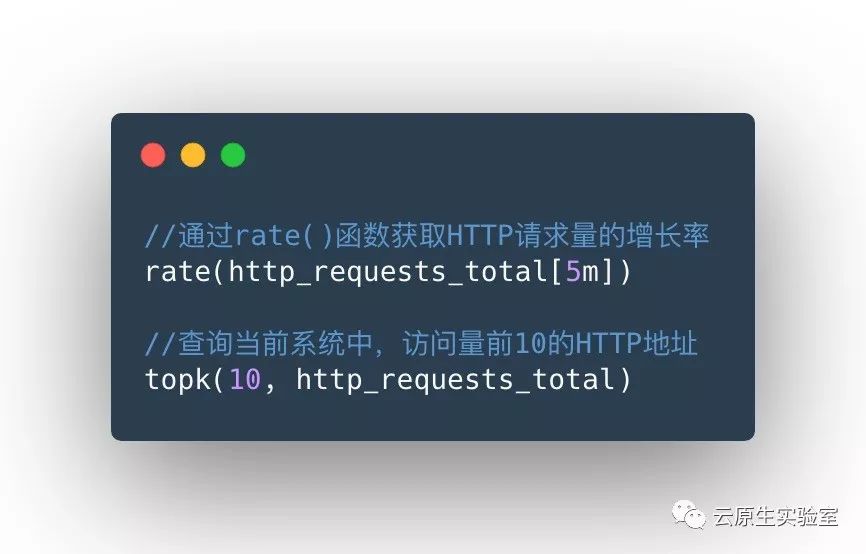
不要将 counter 类型应用于样本数据非单调递增的指标,例如:当前运行的进程数量(应该用 Guage 类型)。
不同语言关于 Counter 的客户端库使用文档:
Guage(仪表盘)
Guage 类型代表一种样本数据可以任意变化的指标,即可增可减。guage 通常用于像温度或者内存使用率这种指标数据,也可以表示能随时增加或减少的“总数”,例如:当前并发请求的数量。
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异:
dalta(cpu_temp_celsius{host="zeus"}[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
不同语言关于 Guage 的客户端库使用文档:
Histogram(直方图)
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
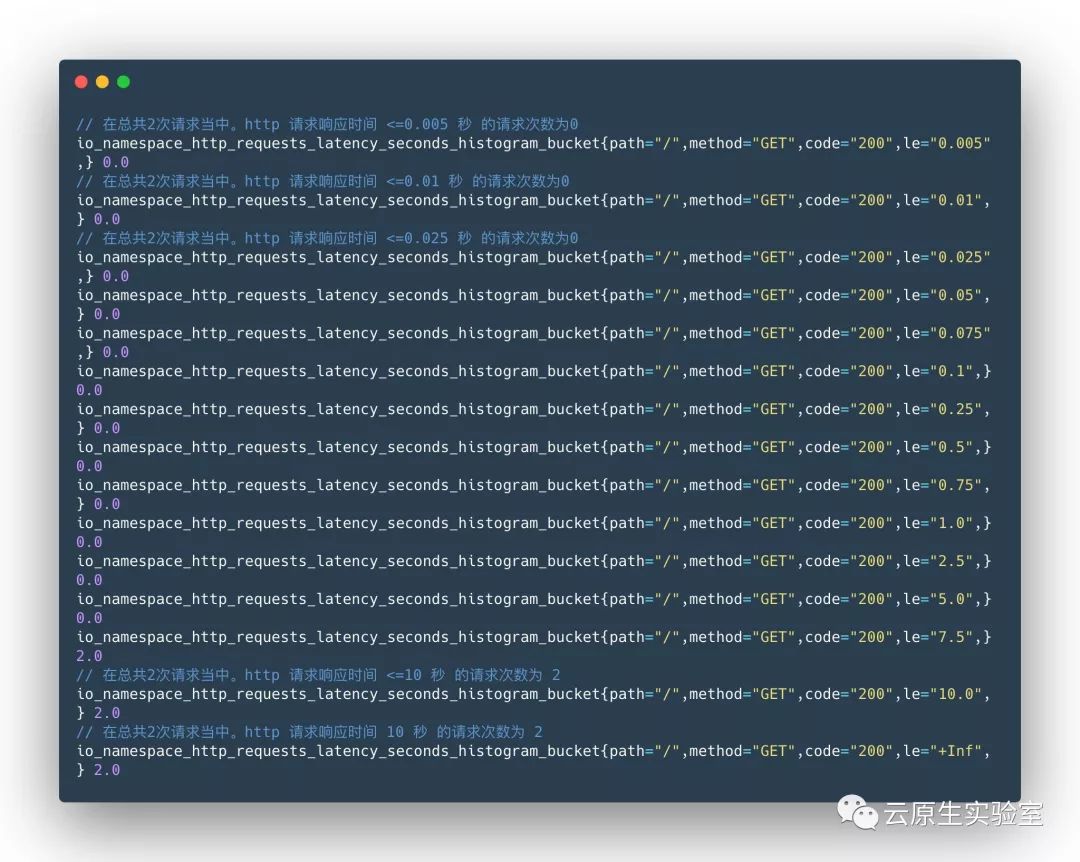
Histogram 在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
Histogram 类型的样本会提供三种指标(假设指标名称为 <basename>):
-
样本的值分布在 bucket 中的数量,命名为
_bucket{le="<上边界>"}
-
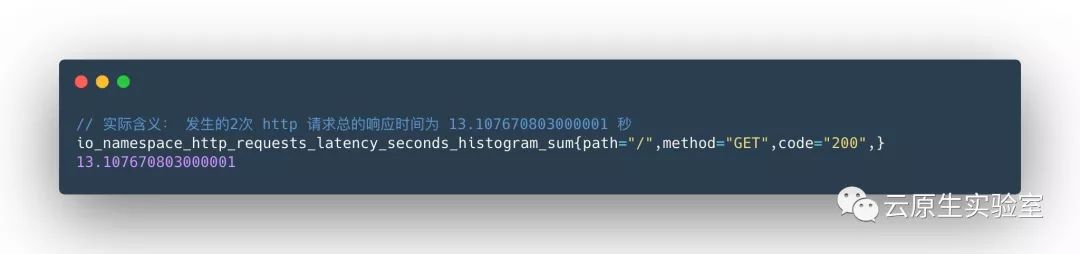
所有样本值的大小总和,命名为
_sum
-
样本总数,命名为
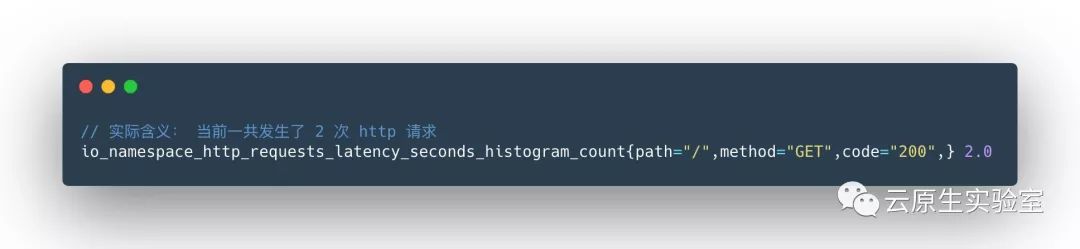
_count _bucket{le="+Inf"}
可以通过 histogram_quantile() 函数来计算 Histogram 类型样本的分位数。分位数可能不太好理解,我举个例子,假设你要计算样本的 9 分位数(quantile=0.9),即表示 90% 的样本的值。Histogram 还可以用来计算应用性能指标值(Apdex score)。
不同语言关于 Histogram 的客户端库使用文档:
Summary(摘要)
与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
Summary 类型的样本也会提供三种指标(假设指标名称为
-
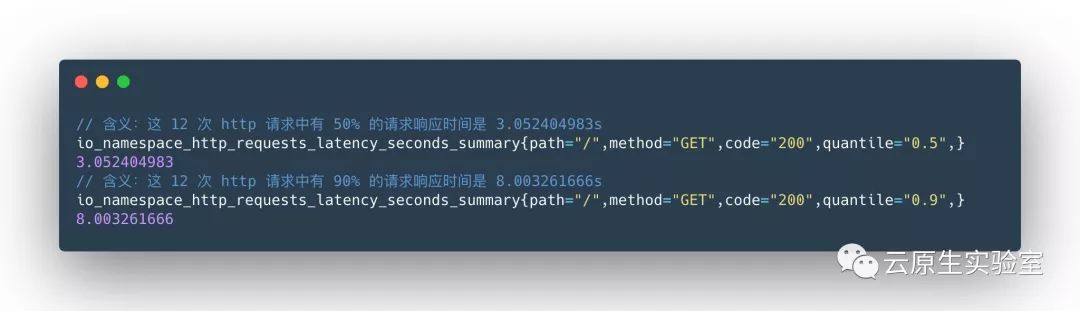
样本值的分位数分布情况,命名为
{quantile="<φ>"}
-
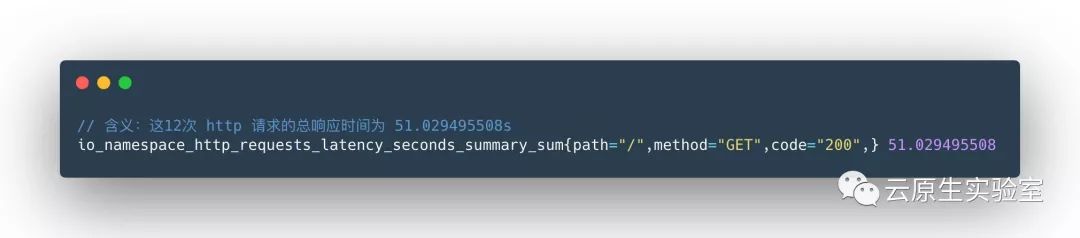
所有样本值的大小总和,命名为
_sum
-
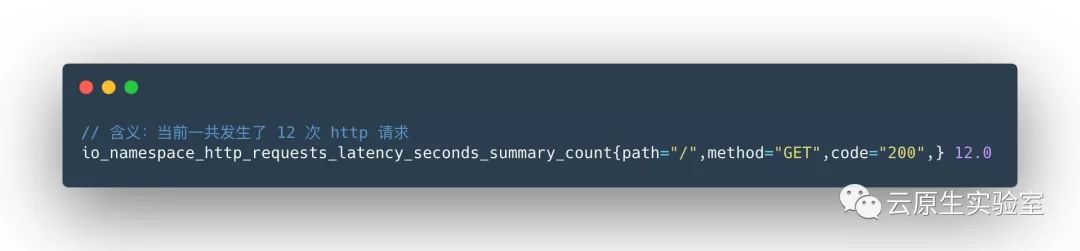
样本总数,命名为
_count
现在可以总结一下 Histogram 与 Summary 的异同:
-
它们都包含了
_sum _count -
Histogram 需要通过
_bucket
关于 Summary 与 Histogram 的详细用法,请参考 histograms and summaries。
不同语言关于 Summary 的客户端库使用文档:
留言交流不过瘾?添加微信:zyc_enjoy
根据指引加入各种主题讨论群
每日一问
今日问题:
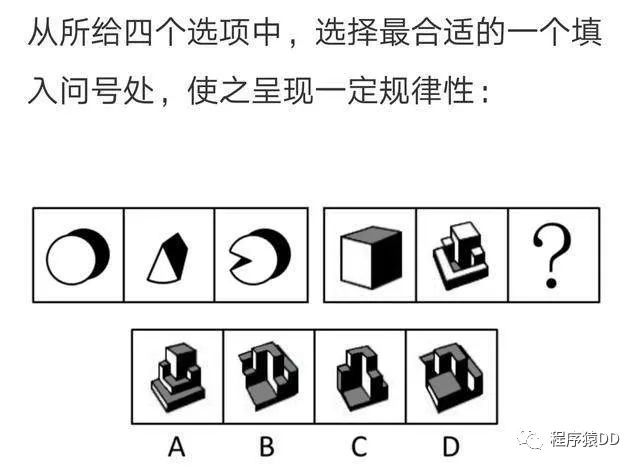
(留言说说你的答案吧,明日推文公布答案)
昨日答案:C
解释:图形中元素组成不同,先数数,每行图形中的黑点依次是7、8、9,?处的图形黑点也应该是9,排队B;然后看黑点位置,第一行的黑点都没有挨着,第二行有两个挨着,第三行前两个图形都有3个挨着,那么?处的也应该有3个黑点挨着,故选C。
(昨日问题可在昨日推文的文末查看)
推荐阅读
推荐活动


点一点“阅读原文”小惊喜在等你

文章评论