选自medium
作者:Dimitris Apostolopoulos
机器之心编译
参与:shooting
哈喽各位久等啦!上一篇文章中,我们介绍了「推荐系统之路」,有些小可爱在留言里表示期待下一篇。最近,这位作者大大更新了。虽然还是关于推荐系统,但这次讲的是产品聚类以及相关方法,具体见下文↓↓
在上一篇文章中,我大致介绍了推荐系统,但卡在了矩阵系统的性能这一块。所以本文将继续上一篇,一个个找出每个没有执行的变量,并尝试修复它们。
现在,我们继续从上次中断的地方开始吧!
「疼痛识别」:发现问题
正如上一篇文章中所提到的,我们要面对的问题之一是:交互矩阵太大,很难衡量或计算。这是因为不同商店中会有相同或者相似的产品,所以我们收集的大量数据中包含重复的信息。

也就是说,如果你卖耳机,而你的三个竞争对手也卖相同品牌的耳机,那你的矩阵中会有很多重复的信息,而这无疑会拖慢你的工作速度。
所以本文的目的是:实现相同或相似产品的跨商店识别。
「走个过场」:融合信息
我们将会使用数据集提供的产品信息(即产品编码、产品名称、产品 URL 和产品价格)来确定产品的相似度。然而,现在每个商店都会用内部系统来追踪产品。因此,对每个商店来说,产品编码都是独一无二的。
更郁闷的是,产品价格我们也用不上,因为每个商店的产品价格也不同。产品 URL 倒是个不错的信息来源,如果我们可以构建 Web Scraper 来从网页上获取数据的话。但是,由于网页的「非结构化」,我们没办法构建适用于每个网页的 Web Scraper。
因此,我们能用的选项只剩一个了:产品名。
「做好准备」:文本预处理
文本预处理是指文本在馈送至算法前必须经历的所有调整。因为文本本身会有很多不需要的符号,或者一些特殊的结构,所以预处理需要做的就是整理文本,并用数值编码文本内容。
文本聚类预处理步骤
我们要对数据进行以下预处理过程:
-
首先,我们确认产品的品牌并将其从产品名中剔除,这样我们得到的就是单纯的产品名了。
-
然后,我们分离产品名中描述颜色的单词,以便减少数据噪声。此时,我们就可以根据颜色给产品分类。例如,我们想创建这两个类别:「黑色匡威全明星鞋 10」和「白色匡威全明星鞋 10.5」。
-
接下来,我们分离产品名中的数字和度量单位(如果有的话),因为我们想把非常相似的产品归到一类中去,比如「Cola 330ml」和「Cola 500ml」。
-
最后,我们对单词进行词干处理。也就是说,分离单词的后缀,以找出共同的词根,并完全去停用词。
-
为了将产品名输入至算法中,我们要把数据转换为向量。为此,我们使用 2 个不同的向量器:CountVectorizer 和* *tf-idf Vectorizer。前者用 {0,1} 创建二元向量,后者根据单词在所有向量中的频率为每个单词分配一个权重。在这里,我们用这两个向量器来找出对我们更有效的向量。
下一步:文本聚类
什么是文本聚类?
文本聚类是在无标签数据中生成分组的过程,很多网站的「同类」新闻就是通过文本聚类完成的。在大多数聚类技术中,分组(或集群)数量是由用户预定义的。但在本文中,分组数量必须动态变化。
我们的聚类可以包含单个产品,也可以包含 10 个或更多产品;这个数量要取决于我们找到的相似产品的数量。
前面所述的需求令我们锁定了 DBSCAN 聚类。DBSCAN 是一种基于密度的算法,它依赖于向量相互之间的距离,以创建分组。
DBSCAN 生成的分组:

为什么 DBSCAN 无法正确地聚类数据?
产品名一般都很短(1~5 个单词)。但是,我们创建的向量很庞大,因为数据中每个单独的词最终组成了整个词汇表。词汇表的大小即向量的长度,所以我们相当于丢失了所有信息。
像 PCA 和 SVD 这样的降维技术也没办法解决这个问题,因为转换矩阵的每一列都代表一个单词。因此,当你删除一些列时,也删除了很多产品。
由于我们现有的解决方案无法正常工作,所以,我们决定构建自定义的聚类过程,以找到解决问题的办法。
打破舒适圈:训练向量器
当你训练向量器(vectorizer)时,它会学习给定句子中包含的单词。
例如,给定「Nike Capri Shoes」,向量器只学习这三个单词。这意味着当你转换其它产品时,除了那些包含一个单词或所有单词的产品外,其它产品的向量都会为 0。
为了找出 2 个向量之间的相似性,我们用欧几里得距离来进行衡量。如果 2 个产品被归为 1 类,且距离要高于我们的阈值,我们就称生成的组为 category。
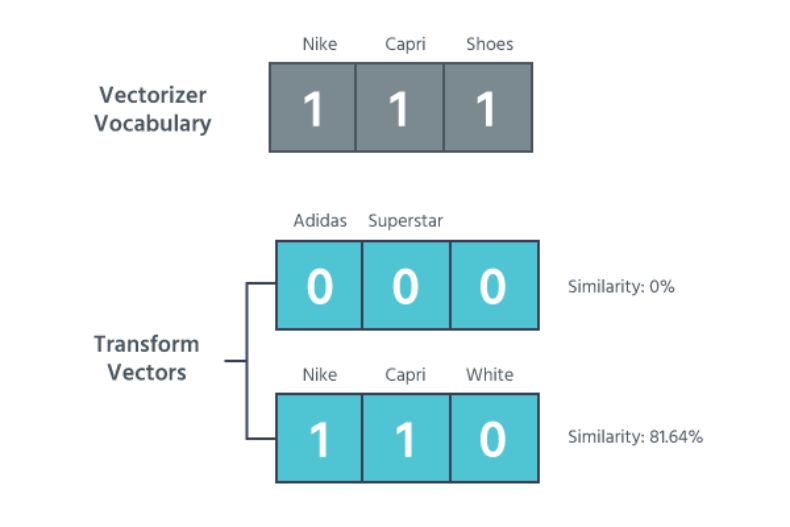
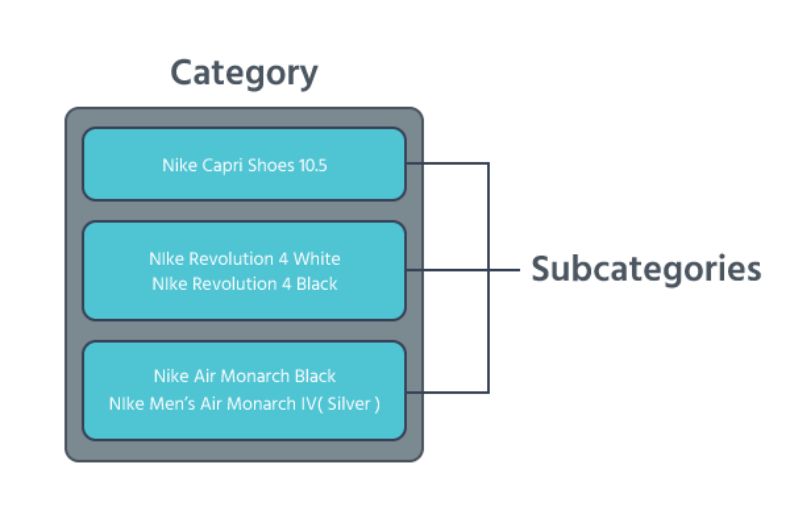
想象一下,我们的数据就像一大桶产品。category 很有用,因为它们创建了更小的桶来包含相关数据,而我们可以处理这种规模的数据。
现在,我们用更高的阈值再次运行同样的过程,然后为每个「小桶」创建 Subcategory。Subcategory 是我们将使用的最小组别。
换挡:提高处理速度的技巧
整个聚类过程有些费时。为了节约时间,我们将仔细检查所有的文本预处理步骤,向量化除外。
之后,我们根据产品名包含的单词数量对数据进行分类,所以只含有 1 个单词的产品名将排在列表最上面,而包含最多单词的则在排在最后。
我们的分组中大部分都是包含 1 个单词的产品名,这减少了我们需要处理的数据量。
OK,功成身退!
下一篇文章中,我们将继续利用从产品中提取的任何信息。尽请期待…… 
原文链接:https://medium.com/moosend-engineering-data-science/product-clustering-a-text-clustering-approach-c392c2ef4310
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]

文章评论