大数据文摘出品
来源:medium
编译:周家乐、狗小白、蒋宝尚
统计学和机器学习之间的界定一直很模糊。
无论是业界还是学界一直认为机器学习只是统计学批了一层光鲜的外衣。
而机器学习支撑的人工智能也被称为“统计学的外延”
例如,诺奖得主托马斯·萨金特曾经说过人工智能其实就是统计学,只不过用了一个很华丽的辞藻。

萨金特在世界科技创新论坛上表示,人工智能其实就是统计学
当然也有一些不同的声音。但是这一观点的正反双方在争吵中充斥着一堆看似高深实则含糊的论述,着实让人摸不着头脑。
一位名叫Matthew Stewart的哈佛大学博士生从统计与机器学习的不同;统计模型与机器学习的不同,这两个角度论证了机器学习和统计学并不是互为代名词。
机器学习和统计的主要区别在于它们的目的
与大部分人所想的正相反,机器学习其实已经存在几十年了。当初只是因为那时的计算能力无法满足它对大量计算的需求,而渐渐被人遗弃。然而,近年来,由于信息爆炸所带来的数据和算力优势,机器学习正快速复苏。
言归正传,如果说机器学习和统计学是互为代名词,那为什么我们没有看到每所大学的统计学系都关门大吉而转投'机器学习'系呢?因为它们是不一样的!
我经常听到一些关于这个话题的含糊论述,最常见的是这样的说法:
"机器学习和统计的主要区别在于它们的目的。机器学习模型旨在使最准确的预测成为可能。统计模型是为推断变量之间的关系而设计的。
虽然技术上来说这是正确的,但这样的论述并没有给出特别清晰和令人满意的答案。机器学习和统计之间的一个主要区别确实是它们的目的。
然而,说机器学习是关于准确的预测,而统计模型是为推理而设计,几乎是毫无意义的说法,除非你真的精通这些概念。

首先,我们必须明白,统计和统计建模是不一样的。统计是对数据的数学研究。除非有数据,否则无法进行统计。统计模型是数据的模型,主要用于推断数据中不同内容的关系,或创建能够预测未来值的模型。通常情况下,这两者是相辅相成的。
因此,实际上我们需要从两方面来论述:第一,统计与机器学习有何不同;第二,统计模型与机器学习有何不同?
说的更直白些就是,有很多统计模型可以做出预测,但预测效果比较差强人意。
而机器学习通常会牺牲可解释性以获得强大的预测能力。例如,从线性回归到神经网络,尽管解释性变差,但是预测能力却大幅提高。
从宏观角度来看,这是一个很好的答案。至少对大多数人来说已经足够好。然而,在有些情况下,这种说法容易让我们对机器学习和统计建模之间的差异产生误解。让我们看一下线性回归的例子。
统计模型与机器学习在线性回归上的差异
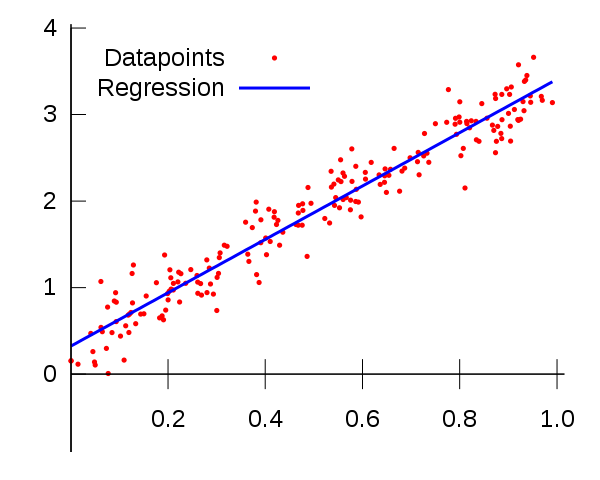
或许是因为统计建模和机器学习中使用方法的相似性,使人们认为它们是同一个东西。对这我可以理解,但事实上不是这样。
最明显的例子是线性回归,这可能是造成这种误解的主要原因。线性回归是一种统计方法,通过这种方法我们既可以训练一个线性回归器,又可以通过最小二乘法拟合一个统计回归模型。
可以看到,在这个案例中,前者做的事儿叫"训练"模型,它只用到了数据的一个子集,而训练得到的模型究竟表现如何需要通过数据的另一个子集测试集测试之后才能知道。在这个例子中,机器学习的最终目的是在测试集上获得最佳性能。
对于后者,我们则事先假设数据是一个具有高斯噪声的线性回归量,然后试图找到一条线,最大限度地减少了所有数据的均方误差。不需要训练或测试集,在许多情况下,特别是在研究中(如下面的传感器示例),建模的目的是描述数据与输出变量之间的关系, 而不是对未来数据进行预测。我们称此过程为统计推断,而不是预测。尽管我们可以使用此模型进行预测,这也可能是你所想的,但评估模型的方法不再是测试集,而是评估模型参数的显著性和健壮性。
机器学习(这里特指有监督学习)的目的是获得一个可反复预测的模型。我们通常不关心模型是否可以解释。机器学习只在乎结果。就好比对公司而言,你的价值只用你的表现来衡量。而统计建模更多的是为了寻找变量之间的关系和确定关系的显著性,恰巧迎合了预测。
下面我举一个自己的例子,来说明两者的区别。我是一名环境科学家。工作的主要内容是和传感器数据打交道。如果我试图证明传感器能够对某种刺激(如气体浓度)做出反应, 那么我将使用统计模型来确定信号响应是否具有统计显著性。我会尝试理解这种关系,并测试其可重复性,以便能够准确地描述传感器的响应,并根据这些数据做出推断。我还可能测试,响应是否是线性的?响应是否归因于气体浓度而不是传感器中的随机噪声?等等。
而同时,我也可以拿着从20个不同传感器得到的数据, 去尝试预测一个可由他们表征的传感器的响应。如果你对传感器了解不多,这可能会显得有些奇怪,但目前这确实是环境科学的一个重要研究领域。
用一个包含20个不同变量的模型来表征传感器的输出显然是一种预测,而且我也没期待模型是可解释的。要知道,由于化学动力学产生的非线性以及物理变量与气体浓度之间的关系等等因素,可能会使这个模型非常深奥,就像神经网络那样难以解释。尽管我希望这个模型能让人看懂, 但其实只要它能做出准确的预测,我就相当高兴了。
如果我试图证明数据变量之间的关系在某种程度上具有统计显著性,以便我可以在科学论文中发表,我将使用统计模型而不是机器学习。这是因为我更关心变量之间的关系,而不是做出预测。做出预测可能仍然很重要,但是大多数机器学习算法缺乏可解释性,这使得很难证明数据中存在的关系。
很明显,这两种方法在目标上是不同的,尽管使用了相似的方法来达到目标。机器学习算法的评估使用测试集来验证其准确性。然而,对于统计模型,通过置信区间、显著性检验和其他检验对回归参数进行分析,可以用来评估模型的合法性。因为这些方法产生相同的结果,所以很容易理解为什么人们会假设它们是相同的。
统计与机器学习在线性回归上的差异
有一个误解存在了10年:仅基于它们都利用相同的基本概率概念这一事实,来混淆这两个术语是不合理的。
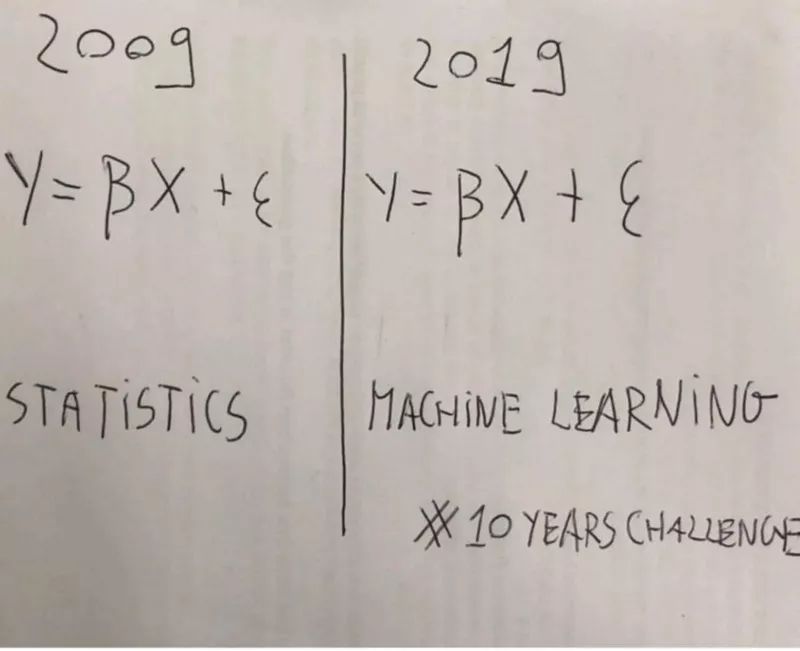
然而,仅仅基于这两个术语都利用了概率里相同的基本概念这一事实而将他们混为一谈是不合理的。就好比,如果我们仅仅把机器学习当作皮了一层光鲜外衣的统计,我们也可以这样说:
-
物理只是数学的一种更好听的说法。
-
动物学只是邮票收藏的一种更好听的说法。
-
建筑学只是沙堡建筑的一种更好听的说法。
这些说法(尤其是最后一个)非常荒谬,完全混淆了两个类似想法的术语。
实际上,物理是建立在数学基础上的,理解现实中的物理现象是数学的应用。物理学还包括统计学的各个方面,而现代统计学通常是建立在Zermelo-Frankel集合论与测量理论相结合的框架中,以产生概率空间。它们有很多共同点,因为它们来自相似的起源,并运用相似的思想得出一个逻辑结论。同样,建筑学和沙堡建筑可能有很多共同点,但即使我不是一个建筑师,也不能给出一个清晰的解释,但也看得出它们显然不一样。
在我们进一步讨论之前,需要简要澄清另外两个与机器学习和统计有关的常见误解。这就是人工智能不同于机器学习,数据科学不同于统计学。这些都是没有争议的问题,所以很快就能说清楚。
数据科学本质上是应用于数据的计算和统计方法,包括小数据集或大数据集。它也包括诸如探索性数据分析之类的东西,例如对数据进行检查和可视化,以帮助科学家更好地理解数据,并从中做出推论。数据科学还包括诸如数据包装和预处理之类的东西,因此涉及到一定程度的计算机科学,因为它涉及编码和建立数据库、Web服务器之间的连接和流水线等等。
要进行统计,你并不一定得依靠电脑,但如果是数据科学缺了电脑就没法操作了。这就再次说明了虽然数据科学借助统计学,这两者不是一个概念。
同理,机器学习也并非人工智能;事实上,机器学习是人工智能的一个分支。这一点挺明显的,因为我们基于以往的数据“教”(训练)机器对特定类型的数据进行概括性的预测。
机器学习是基于统计学
在我们讨论统计学和机器学习之间的区别前,我们先来说说其相似性,其实文章的前半段已经对此有过一些探讨了。
机器学习基于统计的框架,因为机器学习涉及数据,而数据必须基于统计学框架来进行描述,所以这点十分明显。然而,扩展至针对大量粒子的热力学的统计机制,同样也建立在统计学框架之下。
压力的概念其实是数据,温度也是一种数据。你可能觉得这听起来不合理,但这是真的。这就是为什么你不能描述一个分子的温度或压力,这不合理。温度是分子相撞产生的平均能量的显示。而例如房屋或室外这种拥有大量分子的,我们能用温度来描述也就合理了。
你会认为热力学和统计学是一个东西吗?当然不会,热力学借助统计学来帮助我们理解运动的相互作用以及转移现象中产生的热。
事实上,热力学基于多种学科而非仅仅统计学。类似地,机器学习基于许多其他领域的内容,比如数学和计算机科学。举例来说:
机器学习的理论来源于数学和统计学
机器学习算法基于优化理论、矩阵代数和微积分
机器学习的实现来源于计算机科学和工程学概念,比如核映射、特征散列等。
当一个人开始用Python开始编程,突然从Sklearn程序库里找出并使用这些算法,许多上述的概念都比较抽象,因此很难看出其中的区别。这样的情况下,这种抽象定义也就致使了对机器学习真正包含的内容一定程度上的无知。
统计学习理论——机器学习的统计学基础
统计学和机器学习之间最主要的区别在于统计学完全基于概率空间。你可以从集合论中推导出全部的统计学内容,集合论讨论了我们如何将数据归类(这些类被称为“集”),然后对这个集进行某种测量保证其总和为1.我们将这种方法成为概率空间。
统计学除了对这些集合和测量有所定义之外没有其他假设。这就是为什么我们对概率空间的定义非常严谨的原因。一个概率空间,其数学符号写作(Ω,F,P),包含三部分:
-
一个样本空间,Ω,也就是所有可能结果的集合。
-
一个事件集合,F,每个事件都包含0或者其它值。
-
对每个事件发生的可能性赋予概率,P,这是一个从事件到概率的函数。
机器学习基于统计学习理论,统计学习理论也依旧基于对概率空间的公理化语言。这个理论基于传统的统计学理论,并发展于19世纪60年代。
机器学习分为多个类别,这篇文章我仅着眼于监督学习理论,因为它最容易解释(虽然因其充斥数学概念依然显得晦涩难懂)。
统计学习理论中的监督学习,给了我们一个数据集,我们将其标为S= {(xᵢ,yᵢ)},也就是说我们有一个包含N个数据点的数据集,每个数据点由被称为“特征”的其它值描述,这些特征用x描述,这些特征通过特定函数来描绘以返回我们想要的y值。
已知这个数据集,问如何找到将x值映射到y值的函数。我们将所有可能的描述映射过程的函数集合称为假设空间。
为了找到这个函数,我们需要给算法一些方法来“学习”如何最好地着手处理这个问题,而这由一个被称为“损失函数”的概念来提供。因此,对我们所有的每个假设(也即提议的函数),我们要通过比较所有数据下其预期风险的值来衡量这个函数的表现。
预期风险本质上就是损失函数之和乘以数据的概率分布。如果我们知道这个映射的联合概率分布,找到最优函数就很简单了。但是这个联合概率分布通常是未知的,因此我们最好的方式就是猜测一个最优函数,再实证验证损失函数是否得到优化。我们将这种称为实证风险。
之后,我们就可以比较不同函数,找出最小预期风险的那个假设,也就是所有函数中得出最小下确界值的那个假设。
然而,为了最小化损失函数,算法有通过过度拟合来作弊的倾向。这也是为什么要通过训练集“学习”函数,之后在训练集之外的数据集,测试集里对函数进行验证。
我们如何定义机器学习的本质引出了过度拟合的问题,也对需要区分训练集和测试集作出了解释。而我们在统计学中无需试图最小化实证风险,过度拟合不是统计学的固有特征。最小化统计学中无需视图程向于一个从函数中选取最小化实证风险的学习算法被称为实证风险最小化
例证
以线性回归做一个简单例子。在传统概念中,我们试图最小化数据中的误差找到能够描述数据的函数,这种情况下,我们通常使用均值方差。使用平方数是为了不让正值和负值互相抵消。然后我们可以使用闭合表达式来求出回归系数。
如果我们将损失函数计为均值方差,并基于统计学习理论进行最小化实证风险,碰巧就能得到传统线性回归分析同样的结果。
这个巧合是因为两个情况是相同的,对同样的数据以相同的方式求解最大概率自然会得出相同的结果。最大化概率有不同的方法来实现同样的目标,但没人会去争论说最大化概率与线性回归是一个东西。这个最简单的例子显然没能区分开这些方法。
这里要指出的第二点在于,传统的统计方法中没有训练集和测试集的概念,但我们会使用不同的指标来帮助验证模型。验证过程虽然不同,但两种方法都能够给我们统计稳健的结果。
另外要指出的一点在于,传统统计方法给了我们一个闭合形式下的最优解,它没有对其它可能的函数进行测试来收敛出一个结果。相对的,机器学习方法尝试了一批不同的模型,最后结合回归算法的结果,收敛出一个最终的假设。
如果我们用一个不同的损失函数,结果可能并不收敛。例如,如果我们用了铰链损失(使用标准梯度下降时不太好区分,因此需要使用类似近梯度下降等其它方法),那么结果就不会相同了。
最后可以对模型偏差进行区分。你可以用机器学习算法来测试线性模型以及多项式模型,指数模型等,来检验这些假设是否相对我们的先验损失函数对数据集给出更好的拟合度。在传统统计学概念中,我们选择一个模型,评估其准确性,但无法自动从100个不同的模型中摘出最优的那个。显然,由于最开始选择的算法不同,找出的模型总会存在一些偏误。选择算法是非常必要的,因为为数据集找出最优的方程是一个NP-hard问题。
那么哪个方法更优呢?
这个问题其实很蠢。没有统计学,机器学习根本没法存在,但由于当代信息爆炸人类能接触到的大量数据,机器学习是非常有用的。
对比机器学习和统计模型还要更难一些,你需要视乎你的目标而定究竟选择哪种。如果你只是想要创建一个高度准确的预测房价的算法,或者从数据中找出哪类人更容易得某种疾病,机器学习可能是更好的选择。如果你希望找出变量之间的关系或从数据中得出推论,选择统计模型会更好。

图中文字:
这是你的机器学习系统?
对的,你从这头把数据都倒进这一大堆或者线性代数里,然后从那头里拿答案就好了。
答案错了咋整?
那就搅搅,搅到看起来对了为止。
如果你统计学基础不够扎实,你依然可以学习机器学习并使用它——机器学习程序库里的抽象概念能够让你以业余者的身份来轻松使用它们,但你还是得对统计概念有所了解,从而避免模型过度拟合或得出些貌似合理的推论。
相关报道:
https://towardsdatascience.com/the-actual-difference-between-statistics-and-machine-learning-64b49f07ea3?gi=412e8f93e22e
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至[email protected]
志愿者介绍
后台回复“志愿者”加入我们




文章评论