(点击上方公众号,可快速关注一起学Python)
来源:挖数 链接:
https://www.zhihu.com/question/28975391





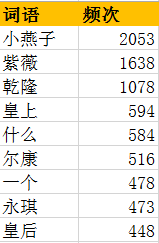
对《还珠格格》进行词频统计

对《还珠格格》的词频统计生成词云标签

将《2016年中国政府工作报告》变成词云是这样的

然后是《小时代》



以小燕子照片为词云背景

对《射雕英雄传》进行词频统计并以郭靖剧照作为词云背景

有没有满满的即视感?




一个Web端的电影数据库交互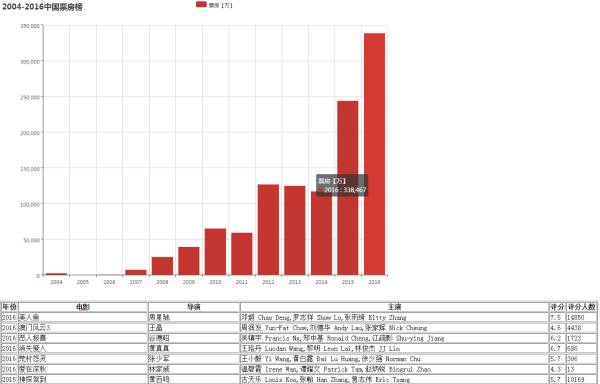


可以了解整个香港电影史,从早期合拍上海片,到胡金栓的武侠片,到李小龙时代,然后是成龙,接着周星驰


对职责要求的词频分析,提炼出必需技能

用爬虫爬下上万知乎女神照片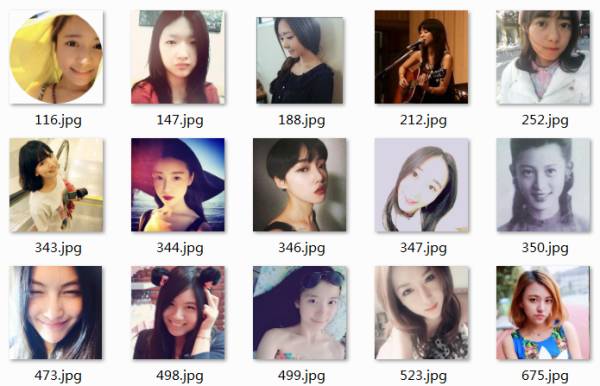

最后,展示一下Python代码:
词频统计和词云的代码
from wordcloud import WordCloud
import jieba
import PIL
import matplotlib.pyplot as plt
import numpy as np
def wordcloudplot(txt):
path = 'd:/jieba/msyh.ttf'
path = unicode(path, 'utf8').encode('gb18030')
alice_mask = np.array(PIL.Image.open('d:/jieba/she.jpg'))
wordcloud = WordCloud(font_path=path, background_color="white", margin=5, width=1800, height=800, mask=alice_mask, max_words=2000, max_font_size=60, random_state=42)
wordcloud = wordcloud.generate(txt)
wordcloud.to_file('d:/jieba/she2.jpg')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
def main():
a = []
f = open(r'd:\jieba\book\she.txt', 'r').read()
words = list(jieba.cut(f))
for word in words:
if len(word) > 1:
a.append(word)
txt = r' '.join(a)
wordcloudplot(txt)
if __name__ == '__main__':
main()爬知乎女神的代码
import requests
import urllib
import re
import random
from time import sleep
def main():
url = 'xxx'
headers = {xxx}
i = 925
for x in xrange(1020, 2000, 20):
data = {'start': '1000',
'offset': str(x),
'_xsrf': 'a128464ef225a69348cef94c38f4e428'}
content = requests.post(url, headers=headers, data=data, timeout=10).text
imgs = re.findall('<img src=\\\\\"(.*?)_m.jpg', content)
for img in imgs:
try:
img = img.replace('\\', '')
pic = img + '.jpg'
path = 'd:\\bs4\\zhihu\\jpg4\\' + str(i) + '.jpg'
urllib.urlretrieve(pic, path)
print ('下载了第' + str(i) + u'张图片')
i += 1
sleep(random.uniform(0.5, 1))
except:
print ('抓漏1张')
pass
sleep(random.uniform(0.5, 1))
if __name__ == '__main__':
main()
(完)
看完本文有收获?请转发分享给更多人
关注「Python那些事」,做全栈开发工程师


文章评论