
文/Kingshine 图片来源于网络
作者简介:KingShine,现居北京,程序猿一枚。主要方向为数据分析、自然语言处理,大数据。希望结交到志同道合的朋友,共同进步。
如今大火的电视剧《都挺好》源于阿耐的同名小说,今天我们来对这部小说使用python分析一下人物关系。本文主要使用google推出的word2vec进行分析。使用的库主要有jieba、gensim。
一、文本准备
从网上下载《都挺好》小说txt。打开查看如下所示:

可以看出,文本中有分段以及大量的换行符,所以在读取文本时需要先去除这些符号。读取文本函数如下:

二、文本分词
在使用word2vec进行模型训练之前,首先需要将文本处理成word2vec可以操作的格式,即分词后使用空格分隔的文本。本文使用jieba进行分词,为了提高分词效果,加入了用户字典和停用词设置。
用户字典格式为:

停用词格式为:

以下是添加用户字典的代码:
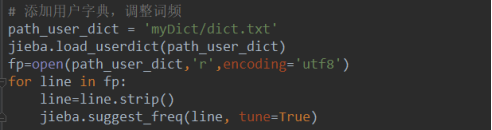
以下是添加停用词设置:

下面开始分词,一开始直接使用jieba分词,但是后面做相似度分析的时候效果不好,因为好多无关词性的词也跑出来,如下图:

所以为了提高效果,在分词的时候加入了词性,分词的代码如下:
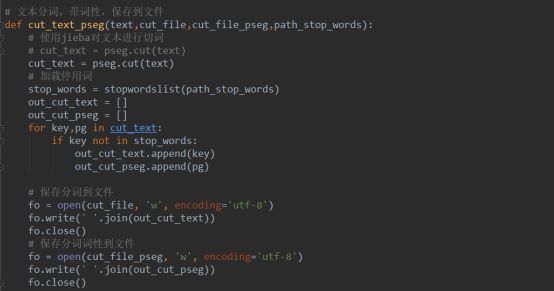
调用函数之后会产生两个文件,一个文件是分词的文件,用来进行word2vec训练,另一个文件存储分词相应的词性。此时,我们还需要一个能根据词来查询其词性的方法,代码如下:

三、模型训练
经过第二步的分词之后,就可以进行训练了。训练主要是调用word2vec相关的函数将词向量化,主要代码如下:
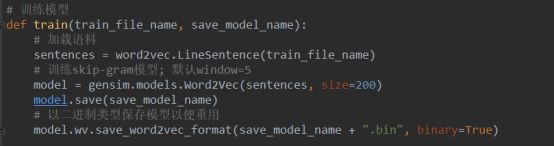
模型已经生成,我们可以调用模型来看一下具体某个词的词向量
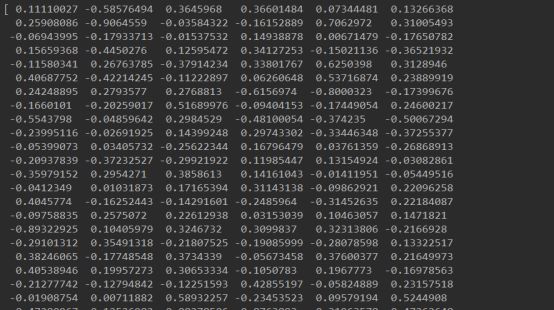
是一个200维的向量。维度可以由我们定义。至此,模型已经训练好。下面进行测试。
四、模型测试
如果此时直接使用模型,效果和之前一样,我们可以利用已生成好的词性文件来进行优化。主要思路是当查找到与目标相似度较高的词时,查询其词性,如果是想要的词性,就输出,不是就抛弃。具体代码如下:
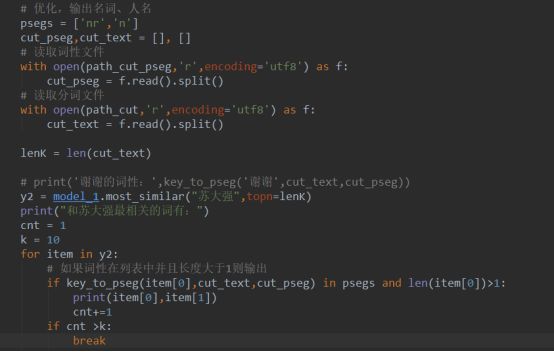
本次求与“苏大强”相似度最高的10个词,运行结果如下
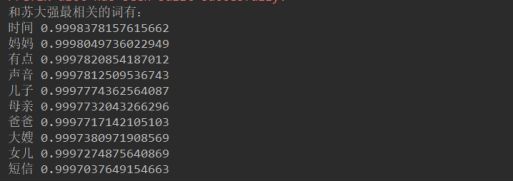
效果确实好多了。但是发现这些词没有文章中的主人公。查看苏大强与蔡根花的相似度:

运行结果如下:

苏大强与蔡根花的相似度明明很高,为什么求相似度top10时没有她。

还有其他主人公的相似度比上面的词相似度低一些,但是要更加的有用。如何能显示出更多有效的词呢。
后来经过排查,发现是因为“蔡根花”词性为空,所以在进行优化时,就把本文的人名优化去了,原因是jieba没有把这些词当做人名(nr)。
五、模型优化
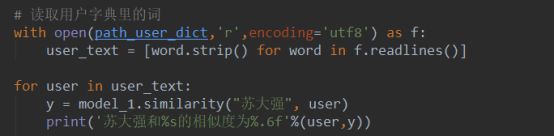
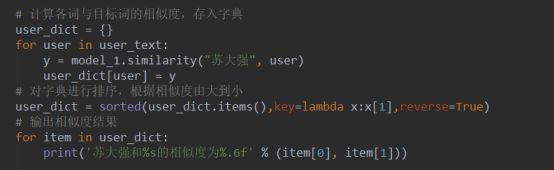
针对这种情况,我们有两种解决方式,第一种是将这些人名的词性加入到词性文件,这样在查找时,就可以找到。第二种方式是直接寻找指定词与目标词的相似度。第二种目标性更强,下面我们直接用用户字典里的词作为与目标“苏大强”的相似度比较。
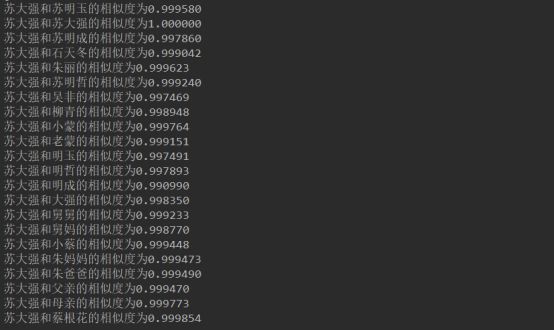
还是不太好看,排序输出后为:
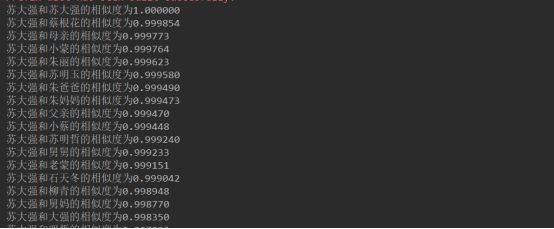
从结果中可以看出,苏大成与蔡根花的相似度最高,蔡根花是苏大成的保姆,也是他的 “宝贝”,也挺符合故事情节的。
zhi
支
chi
持
zuo
作
zhe
者

长按扫码鼓励作者


▼ 长按扫码上方二维码或点击下方阅读原文
免费成为社区注册会员,会员可以享受更多权益

文章评论