鲁迅先生说过,所有能用 JS 写的前端项目最终都会被用 JS 重写一遍,所有能用 Go 写的后端项目最终也都会被用 Go 重写一遍。
作为一名开发者,
周六的我们能做什么呢?
是因为产品经理的各种需求在加班吗?

给你说了实现不了实现不了!
你不是懂技术吗,要不然你来写!
(这位同学你怎么能发语音)
还是像某东一样日常 996,
苦逼的在公司厕所等待下班时间的到来。

听说这是京东厕所里的温馨小贴士...
但是在上海有这样一群程序员,他们不仅在周末“无所事事”,没有加班,没有 996,甚至周末还能参加各种的技术沙龙活动...
不管因为什么原因错过了周末那场精彩的沙龙,没有来到现场真的为你感到很遗憾,但是也没关系,现在可以和我们一起回顾下周六那场精彩纷呈的 Go 语言现场秀。

 羡慕这些周末能自由安排时间的同学 o(╥﹏╥)o
羡慕这些周末能自由安排时间的同学 o(╥﹏╥)o
就像开篇鲁迅提到的那样,所有能用 JS 写的前端项目都会被用 JS 重写一遍,所有能用 Go 写的后端项目都会被用 Go 重写一遍。这不,在上周六的趣头条技术沙龙上,这三位大神分别带来了不同的、完全基于 Go 语言实现的后端服务项目,将 Go 语言在后端的优势体现到了极致。
实践者--趣头条基础架构部架构师徐鹏
在趣头条的实践中,一开始只是想用 Go 语言来做网关,但做着做着就发现 Go 语言的性能超出了想象,Go 语言的一系列特性也完美符合自研微服务框架的需求,Negri 微服务框架也就应运而生。
Negri 微服务框架
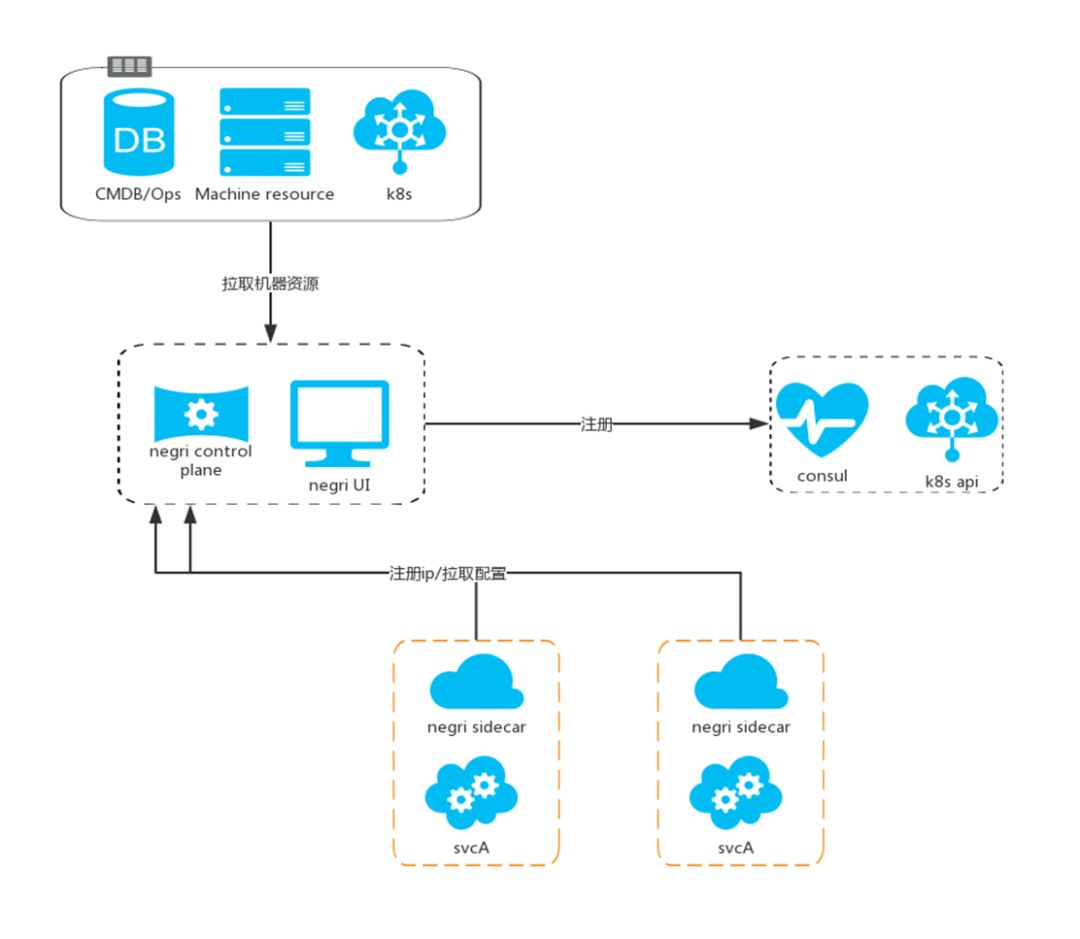
上图所示,这是 Negri 的整体框架图。Sidecar 被誉为构建下一代微服务的关键,对于构建高度高度可伸缩、有弹性、安全且可便于监控的微服务架构系统至关重要,因此 Negri 里对于如何部署配置 Sidecar 也十分的重视。
Negri 与其它框架的不同,在于通过控制平面来负责管理机器资源。因为 IP 是独一无二的,因此选择以 IP 的方式来获取配置,并且依此抽象出 Istio 平面。这会使运维部署流程变得相对友好起来,不需要在每台机器注入环境变量,只要通过寻找 IP 的方式来控制平面,就会得到关于 Sidecar 的配置文件。
同时 Negri 会与 Consul 保持兼容,Negri 会在注册的过程中对运维资源进行二次核对,换句话说,单纯只在 Sidecar 层面做注册,而没有将抽象系统抽离出来单独做交互与核对,此时的 Consul 注册就容易引起部署的风险。

自研 Service Mesh Negri 特性
发展到今天,Negri 也已经逐渐成长为一款相当成熟的微服务框架,与其它微服务框架相比,Negri 有着众多的特性,这里举出其中几个为例:
-
PHP,Golang,Java甚至Node.Js,Python等开发语言都可以直接接入
-
服务注册发现省去了SLB部署环节,可自动发现服务节点变化
-
Negri 维护成本偏低,省去大面积故障所导致的维护成本
-
支持限流、熔断、降级、Trace、Metrics等服务治理
-
提供统一的UI,可展示服务的 Metrics,Trace,日志,调用关系等
-
支持Abtest,Trace,Auth,加解密,Sign 验签等功能的支持
-
不侵入代码
-
通过 fork 进程,配合 Systemd 实现平滑重启
-
动态更新配置,实时控制限流熔断降级等中间件
-
通过单独部署低配置机器和动态修改服务流量,灰度发布服务
-
资源隔离,通过 Cgroup 限制资源(CPU,内存等)使用
-
拥有统一的插件编写体系,无需区分 Client 或 Server,统一抽象为 Server 端中间件,编写一次,多端运行
Negri 的性能优化 -- 榨干 CPU 性能
性能优化是所有后台基础业务框架最重要部分之一,在研发过程中应该经常会发现无论是 Kong 还是 Trans,或多或少都会遇到些性能瓶颈,在 Negri 框架下,解决方法主要有以下四点:
-
首先就是锁瓶颈,通过拆分多个 Transport,设置与核心数相关的连接池数量,最终 CPU 会达到 10 万的 KPS;
-
其次是对象池,这种优化非常常见,通过释放比较频繁的对象与场景,比如说这个模块默认提供一个 buffer,此时就可以作为一个接口传递下来,性能也因此会提升非常多;
-
第三是路由缓存,在网关下接口最多也就是两三百个,不会造成路由性能的下降,但是如果在内网的话就不一样了,PATH 和服务会非常多,可能要解析上千个路由才能匹配到相关请求的服务,所以就需要路由缓存来解决问题;
-
最后是日志 Reopen,业务是不能影响的,往往第三方的日志切分工具会阻断进程,导致业务中断,Reopen 很好解决了这个问题。
Sidecar 模式的转变
单端口还是多端口?这是一个问题,因为 Sidecar 最早是作为网关被开发的,已经有了自己的运行模式。如果是单端口的话,需要重复编写客户端和服务端中间件,多端口的话只需要一次。
另外如何差异化下发配置,要抽象出服务私有化配置的概念,通过 Viper、Merge 的方式来加载,每一个服务都要有一个私有化的配置,另外整个的服务和项目也要有单独的功能化配置。
实践者--七牛大数据团队架构师刘凯
全链路与 Go 语言之间是相得益彰的关系,Go 语言提高了全链路的开发效率,而全链路反过来也提升了 Go 语言项目的运维效率。七牛作为国内应用 Go 语言程度最深的企业之一,基于 Go 语言搭建了一套全链路架构。
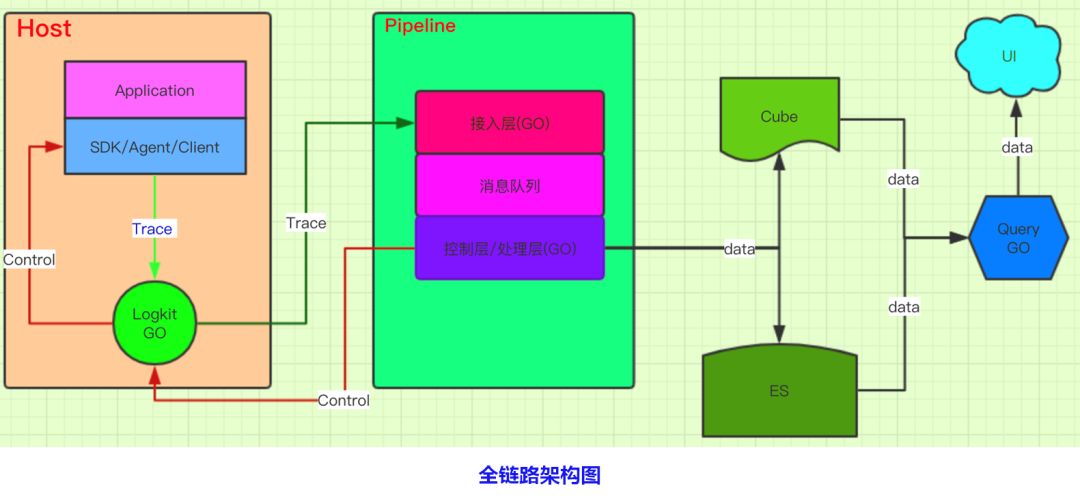
七牛全链路架构共分为三部分,从左至右依次为 HOST、服务端 Pipeline 以及数据可视化逻辑。先看下 HOST 部分,其中的 SDK 是指全链路中能够帮助用户接入的工具以及插件,下方的 Logkit 是通过链路实现的;
按流程走,之后会把采集的全链路数据传送至服务端,以 Pipeline 进行数据写入,最下方的控制层主要用来统计动态修改采集频率。数据抵达右侧后,分为了 ES 和 Cube 两条线,其中每引入一个产品都要将其原始信息存到 ES 中,每当用户发送请求可视化查询信息时都要到 ES 内部拿数据。

如何在低损耗下高效传输数据
全链路追踪讲究的就是高效,七牛在全链路追踪中,对数据额传入以及输出分别做了不同的优化:首先要优化传入效应,即用 TCP 和 UDP 两种协议,TCP是用于服务本身,在一些重要的数据传输上并且不会出现频繁更新服务的情况下,才会使用TCP协议,因为没有必要频繁采集;大部分数据传输是用 UDP 协议获取的,两者结合极大提高了整个效率。
其次是优化 Thrift 以及 Protobuf。经过测试,发现 Thrift 虽然对于语言的兼容性较高,但是单纯从性能的角度看不如 Protobuf。
此外还有压缩、采样率、动态配置等措施可以提升传输效率,归根结底,还是依托于Go语言便利的网络开发以及多平台的支持。
如何产生服务拓扑
全链路很重要的功能就是要划定各个服务间的调用关系与次数,如何快速形成一个更为直观的服务拓扑就显得极为重要。但是不同的产品所依托的技术手段不同,形成拓扑的延迟时间也不尽相同。
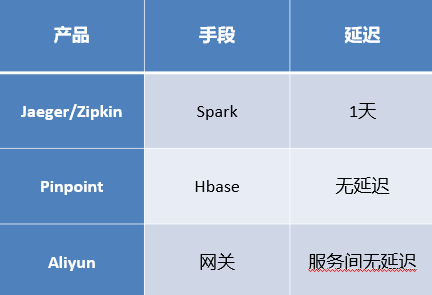
通过上图可以看出,Jaeger 和 Zipkin 是通过 Spark 做的,但是有一天的延迟;Pinpoint 本身是有自己的一套存储格式的,数据存在于Hbase,由于本身已经统计过了,所以完全没有可比性;阿里云主要是通过网关来实现,这个系统是针对网关统计的,因为请求和服务在部署时都会经过网关,通过服务与服务间的调用关系,因此服务间是无延迟的。
服务内部的调用关系也一样,如果像阿里云一样只统计网关的数据,是无法展示更多细节的,所以最终还是选择了与Jaeger相同的调用方式,缺点也很明显就是会产生一天左右的延迟。所以在此基础上,又引入了实时计算框架--Druid。
Druid 通过数据预聚合的方式,为整个链路提供海量数据的快速查询,很契合服务拓扑的实现路径。当数据进入到链内,单独将数据读取出来并做聚合,聚合之后记得保存,后续就可以继续查询,这样将延迟极大的缩短至两到三分钟左右。
实践者--B站主站技术中心高级研发工程师曹国梁
在微服务化以后,大多会遇到服务拆分较多、调用链较长的局面,一旦调用链受到某个坏节点的影响,这样在服务端和用户端很容易造成超时的现象,进而影响到用户体验。

初期的CP服务发现系统
bilibili 在2017年使用的都是基于 Zookeeper 的CP系统,其优点是可以保证数据一致性以及可用性。但是CP系统的缺点也很大,即无法支持跨机房。在实际生产过程中,由于一些不稳定的原因可能会导致网络断开,会影响到服务的注册,同时服务内的请求具有强一致性,所以会重复同步在 Zookeeper 上,从而导致业务中断。
此外还有一个性能瓶颈,因为CP系统是强一致的系统,强一致性会缓存日志这一点大家都很清楚,所有日志缓存都会集中在 Zookeeper 上,基于此的 TCP 检查效率也会随之降低。
AP服务发现系统Discovery
基于上述CP系统的一系列不足,bilibili开始了自研AP服务发现系统的道路。
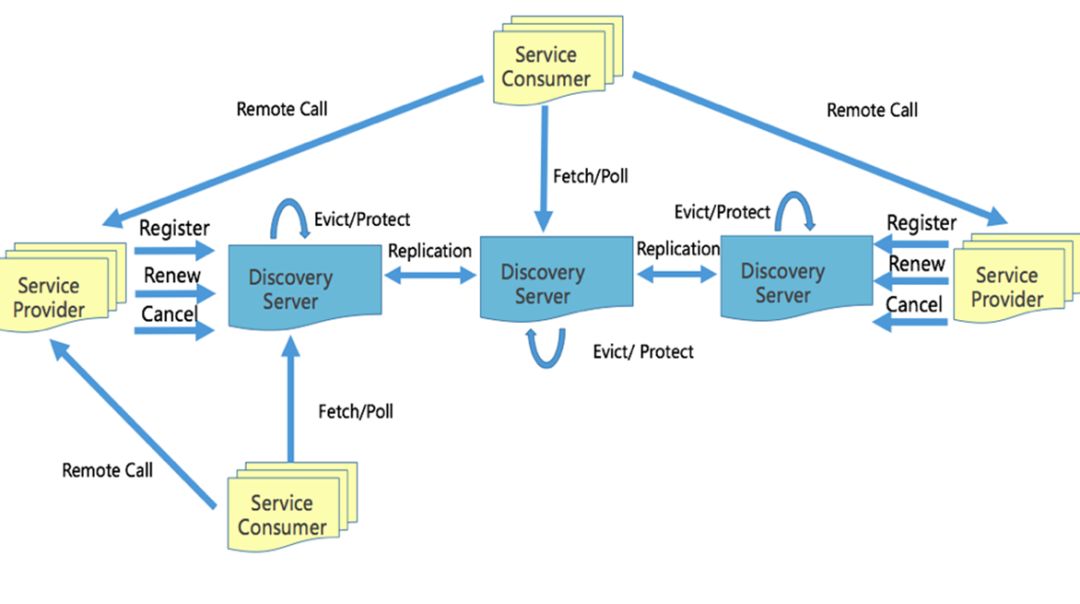
bilibili 在2018年开始自研基于Go语言实现的 Discovery 服务发现框架,现在已经在内部得到大规模的应用,主要有以下三点特性:
-
注册后,通过注册时的 DirtyTime 复制节点信息,所有的健康检测都会通过服务发现系统去确保节点信息最终一致。
-
AP系统在网络分区时会进行自我保护,保证健康的服务节点可用。
-
AP系统客户端通过 HTTP Long Polling 来与服务端进行连接,可以直接调用,并实时关注推送客户端的实例变化。
如何最终保持一致
AP与CP不同的地方一方面是上述额一些特性,另一方面,AP可以确保不同机房之间的流量调度以及节点数据一致性。
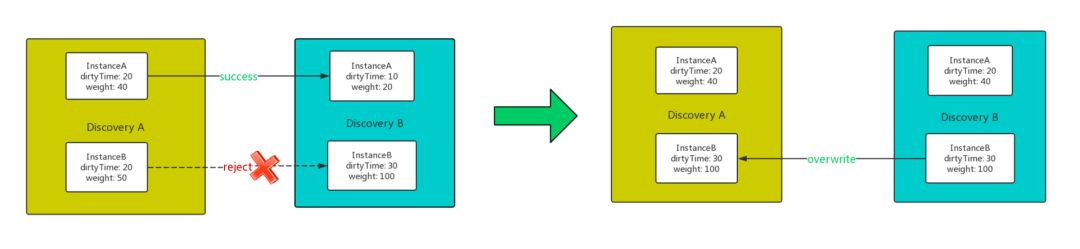
因为每一个服务实例都是全局唯一,因此可以通过服务的 ID 来全局定位这个实例,只需要保持一直递增的 Dirtytime,Discovery 每收到请求后都会在服务内广播一遍,广播时也可以检查数据的一致性,那这个服务方向就一定会保持一致。比如像上图所示,A向B传播的时候,表示B中的实例有部分存在或者是实例较小,此时A的信息同步过去然后把B给覆盖调。
Discovery 如何进行容灾
任何系统和框架都会有遇到故障的时候,那么对待容灾的态度就决定了这个框架以及系统的上限究竟如何。因此发生网络分区或者是网络抖动不稳定的时候,Discovery 服务发现系统是如何进行容灾的?
1、发生严重的网络分区时:
-
当网络分区发生时,每个 Discovery 节点,会持续的对外提供服务,接收该分区下新实例的服务注册和发现。
-
短时间丢失大量心跳,进入自我保护,保证健康的实例不被剔除,同时保留“好数据”与“坏数据”
-
自我保护:每分钟的心跳数小于阈值(实例数量*2*85%),每15分钟重置心跳计算周期
-
非自我保护下,随机分批逐次剔除,尽量避免单个应用被全部过期。
2、部分 Discovery 节点不可用:由于每个节点都有全量的数据,此时客户端SDK会自动选择连接其他正常的 Discovery 节点获取数据;不可用的 Discovery 节点重启后会自动从其他健康的 Discovery 节点拉取全量的数据保持同步
3、全部 Discovery 节点不可用:客户端SDK会缓存数据并拒绝任何实例数过低的异常变更推送;在宕机期间,服务提供者会一直向 Discovery 节点发送心跳请求,直到 Disocvery 节点重启恢复正常之后返回404,此时服务提供者通过调用 Register 接口可以重新注册。
RPC负载均衡算法
如果系统拉取到了错误的节点信息,这时就需要快速剔除错误节点并均衡后端负载。但是当前市面上常见的负载均衡算法都是写死的,并且延迟率较高,会导致负载均衡监控几乎起不到效果。
基于此背景,bilibili 对负载均衡算法进行了优化及改进,形成了负载均衡3.0版本。通过改为实时追踪,使用带时间衰减的滑动平均值,每次请求都可以实时算一次平均值,来实时更新延迟和成功率等信息。
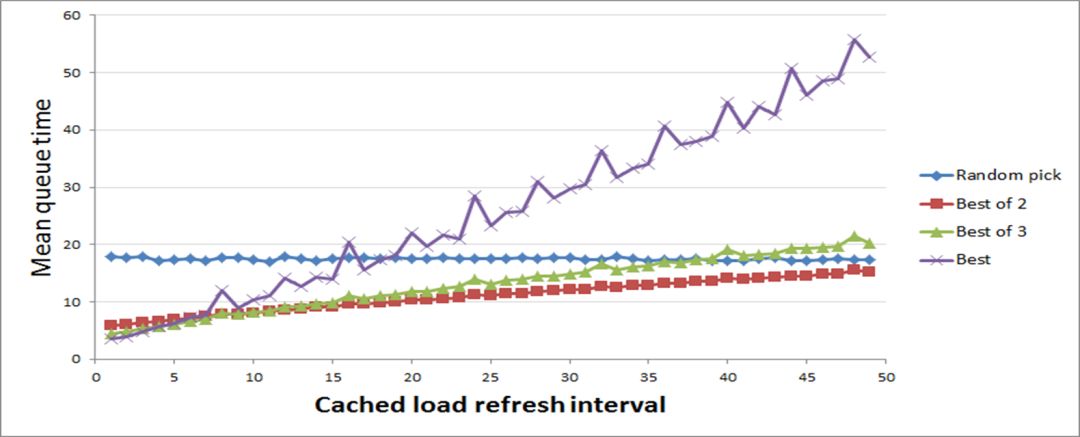
此外也可以引入一些随机量进来,依上图所示,横坐标为信息延迟时间,纵坐标为请求的平均响应时间。毫无疑问肯定是请求响应时间越小越好,横坐标的信息延迟也是越低越好。可以看到图中横坐标在接近0的时候,紫色线条的算法是永远在选节点里最快相应的请求,所以毫无疑问这时候是效果最好的,但是当横坐标在40-50区间的时候效果变得很差。
此外也可以引入 inflight 来平衡负载均衡算法之间的调度。比如A当时正在发送的请求是5,B发给A的请求是10,我们会将 inflight 调入到算法中来进行两者之间的合理调度。归纳一下,即 infight 越高,被调度的机会就越少。
自适应限流
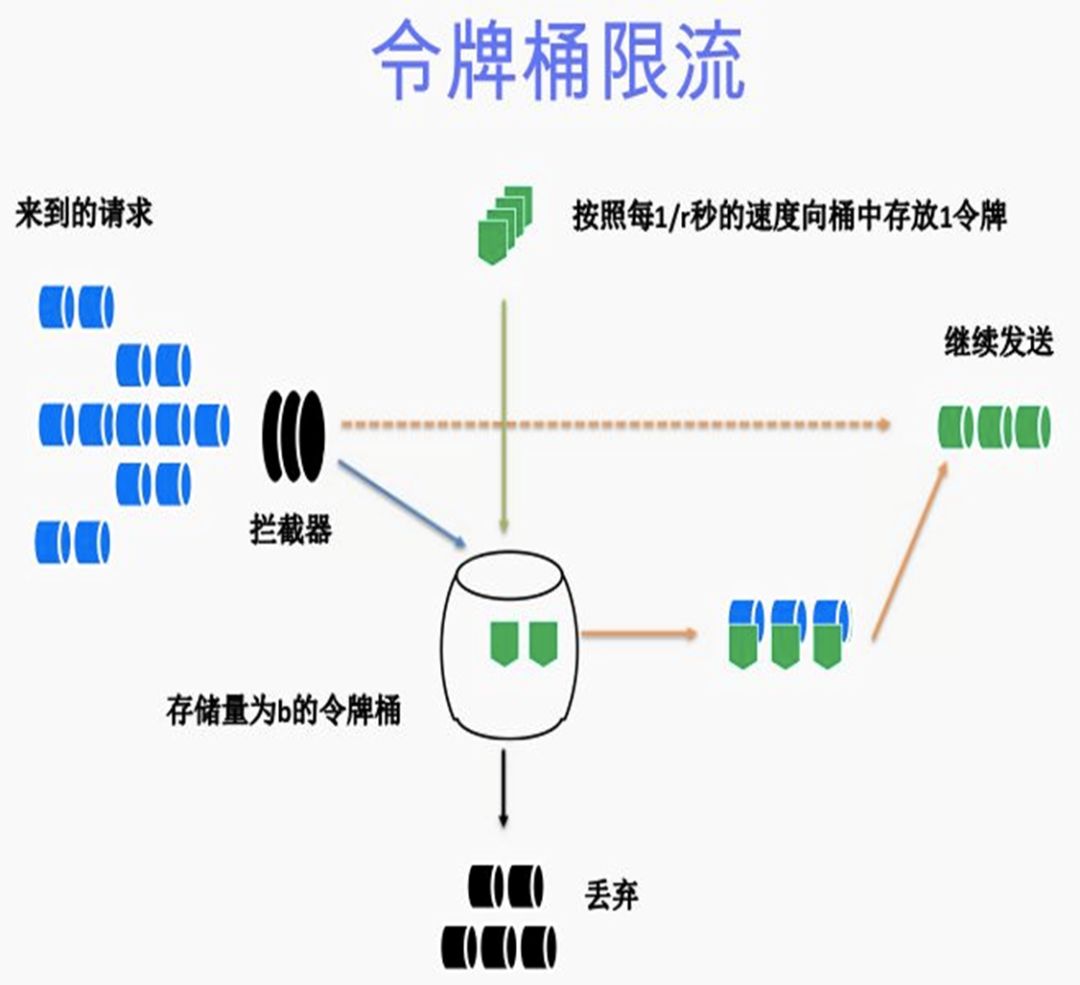
现在很多算法上仍然在使用令牌桶限流的技术,这只是针对局部的服务端限流,无法呈现出全局视角。此外由于业务原因,系统负载肯定是在不断变化中的,如何分辨出请求的重要性,如何让重要请求先通过,这也是单机令牌桶限流的局限性。
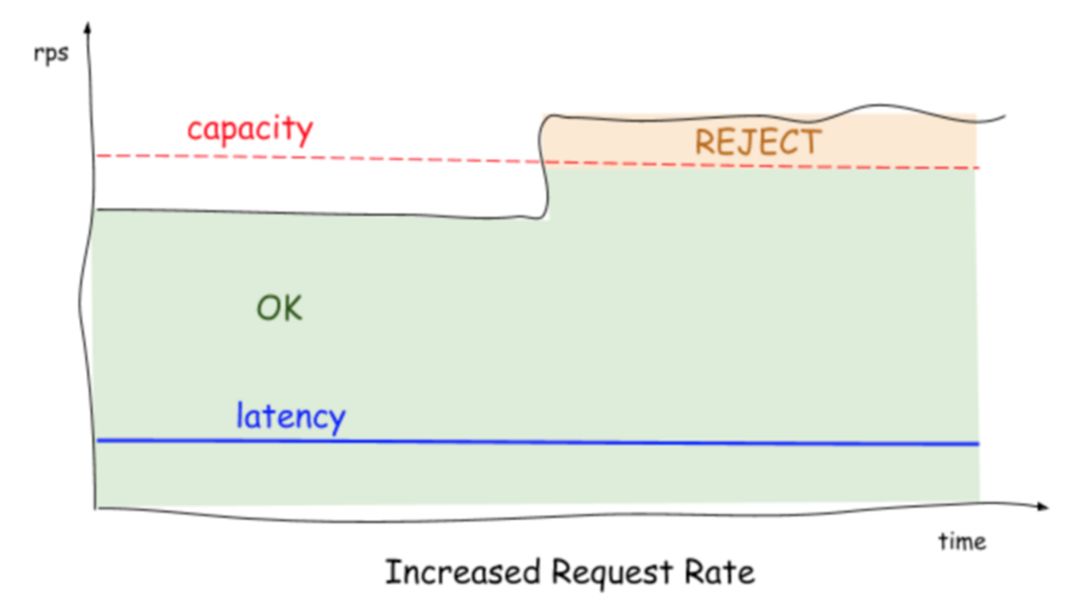
上图是基于 BBR 算法开发的自适应限流,本质是拥塞控制,与限流有一定的相似之处,是基于 CPU\IOPS 作为启发值,通过 BBR 算法来决定系统的最大承载量,算法公式为:
cpu > 800 AND InFlight > (maxPass * minRtt * windows / 1000)
maxPass:最近 5s 内,单个采样窗口中最大的请求数。
minRtt:最近 5s 内,单个采样窗口中最小的响应时间。
windows:一秒内采样窗口的数量,默认配置中是5s/50个采样,那么 windows 的值为 10。
以CPU使用率为启发值,高于80%,表明处理的请求量是大于系统的承载力的,就会自动进行限流,就实现了完全自动化的运维。
微服务中的CoDel队列
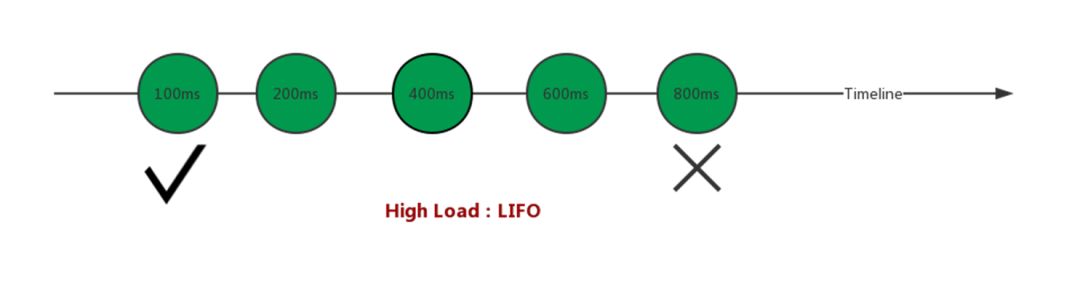
在过去,传统的CoDel队列都是先进先出,请求来的越早在里面排队的时间就越久,也就是系统闲下来时是被优先处理的对象,但是这样的队列在微服务中却十分不友好,因为微服务有超时机制,不可能无限等下去。如果放行一个比较老的请求,这个请求成功率还是会变得很低,因为这个请求由于排队时间过长,导致最终超时,所以也会影响到最终的请求成功率。
因此在微服务下,当系统处于高负载时,就要实行后进先出的策略,即需要主动丢弃排队很久的请求,让那些后进来的请求优先通过,以吸收突增流量作为缓冲,从而弥补CoDel队列之前算法里的缓冲问题。

作为一名开发者,大家的印象中肯定是闷头敲键盘、不善言辞的那种。这里我只想说,不是他们不善言辞,也不是他们冷漠没有情趣,而是你没有get到他们的点。在上周六的上海,一群开发者现场面基,足足互撩了1个多小时的时间。

在【Go的工程化实践】、【大并发和大流量下的Go实践】、【Go在行业中落地与应用】以及【Go的未来前景探讨】这四个话题下,大家展开了激烈的讨论。我们前来参会的开发者真是卧虎藏龙,其中更是有钻研Go语言达8年之久的大神隐藏在我们的人群中,最后产出的内容质量也非常高,足以证明,我们到场的开发者,真正参与到了我们沙龙活动中,并充分展示了自己的技术实力与前瞻性。

开发语言并没有好坏之分,只有适和与不适合的区别。无论哪一种开发语言,只要我们开发者自己能够沉下心来去研究,去认真观察他人的最佳实践,自己能够得心应手的应用这个语言,那么这款开发语言,对于我们开发者自己来说,就是世界上最好的语言。
这里没有加班没有996,甚至周末可以参加各种技术沙龙活动...对Go语言感兴趣的你,想把爱好与工作融合在一起吗,想加入一家专注应用Go语言的公司吗?可以点击阅读原文查看更加详细的信息,填写调查问卷,感受趣头条速度。

文章评论