我就不信有满分飘过的学霸!
请听题:

点击下方空白区域查看答案
▼
正确答案 B
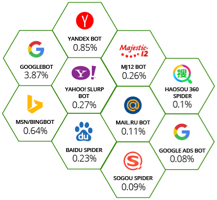
最大的爬虫就是搜索引擎。Google作为世界上最大的搜索引擎,其爬虫流量也遥遥领先于其他各类搜索引擎爬虫,占所有爬虫流量的3.87%

点击下方空白区域查看答案
▼
正确答案 C
企业工商注册信息不是个人数据,数据来源都是国家公示网站,所公示内容是依法公开的内容。
对于敏感的个人信息,比如爬取社保、身份证号、淘宝交易记录,是违法的。
点击下方空白区域查看答案
▼
正确答案 A
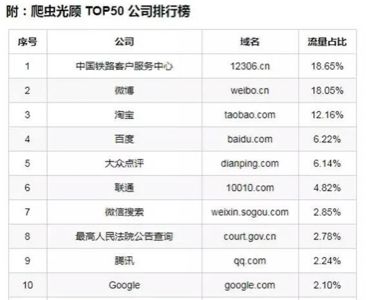
数据来自浅黑科技:关于爬虫,这里有一份《中国焦虑图鉴》
点击下方空白区域查看答案
▼
正确答案 B
经过分析,发现迷之字符规律的出现在 span 标签内,所以就把 span 标签的内容干掉好了。
点击下方空白区域查看答案
▼
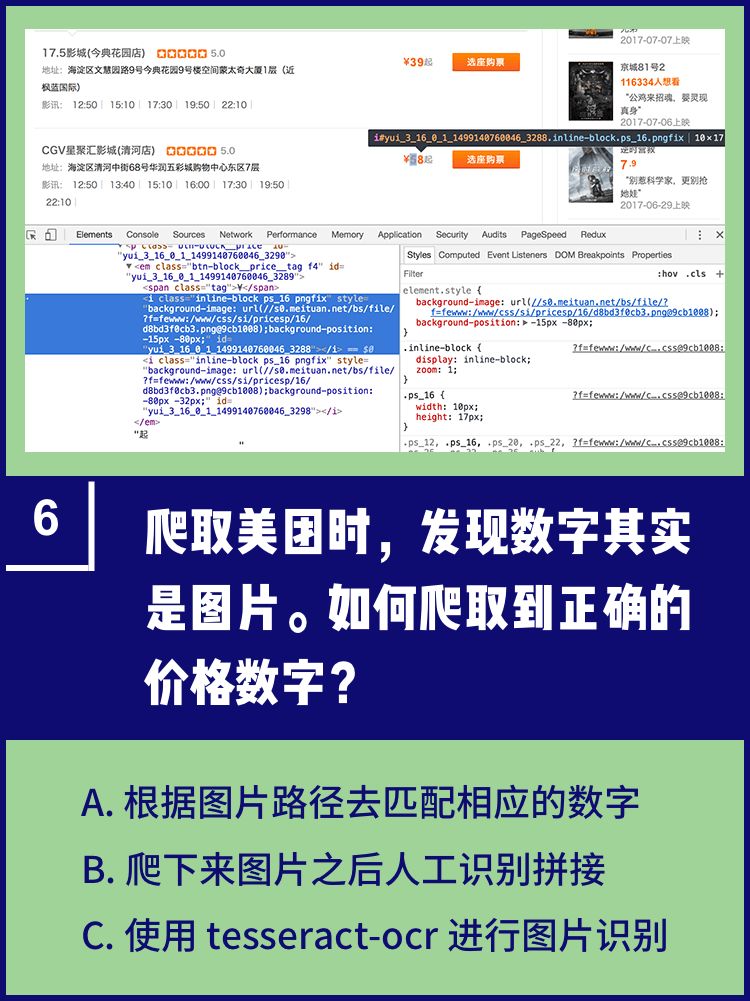
正确答案 C
美团这里用到的是 background 拼凑。数字其实是图片,根据不同的background偏移,显示出不同的字符。
既然人眼可以看出数字是多少,那么程序也可以识别。可以用 tesseract-ocr 进行图片识别。
点击下方空白区域查看答案
▼
正确答案 B
这里去哪儿的策略是先用四个i标签渲染,再用两个b标签去绝对定位偏移量,覆盖故意展示错误的i标签,最后在视觉上形成正确的价格。
找到规律,根据元素偏移量去计算正确的数字和位数,替换掉错误的价格即可。
点击下方空白区域查看答案
▼
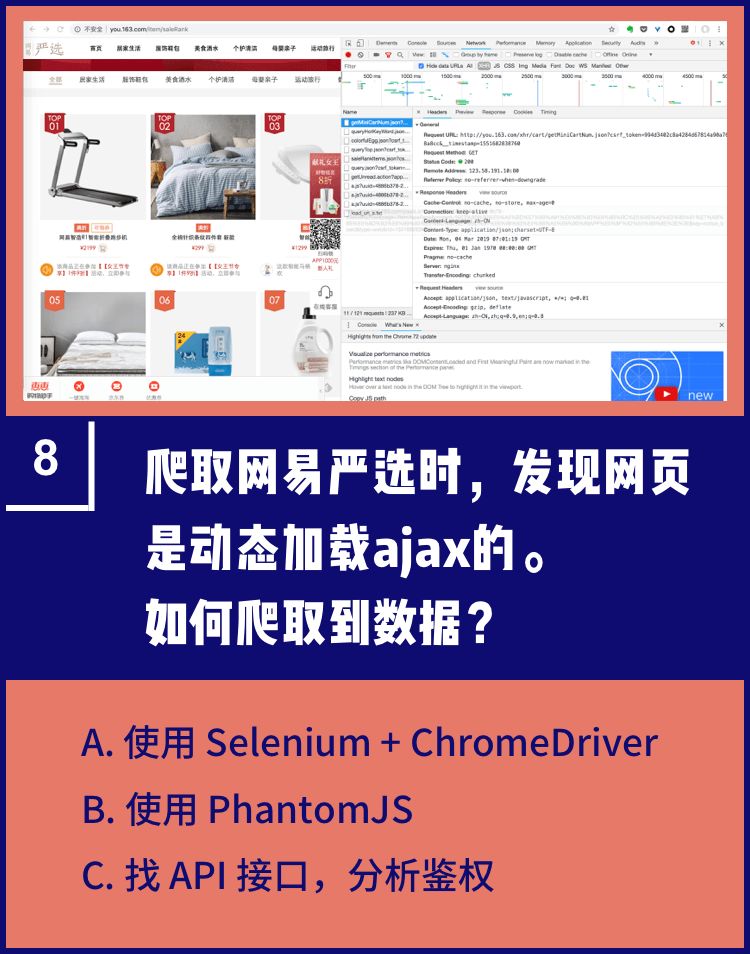
正确答案 AC
使用 Selenium + chromedriver 或者抓 API 接口都可以,这里不推荐 PhantomJS 是因为框架不再维护了。但可能一些老的教程还在用。
点击下方空白区域查看答案
▼
正确答案 AB
抓包 mitmproxy 或者 APK 反编译都可以。Requests 肯定是请求不到的了。
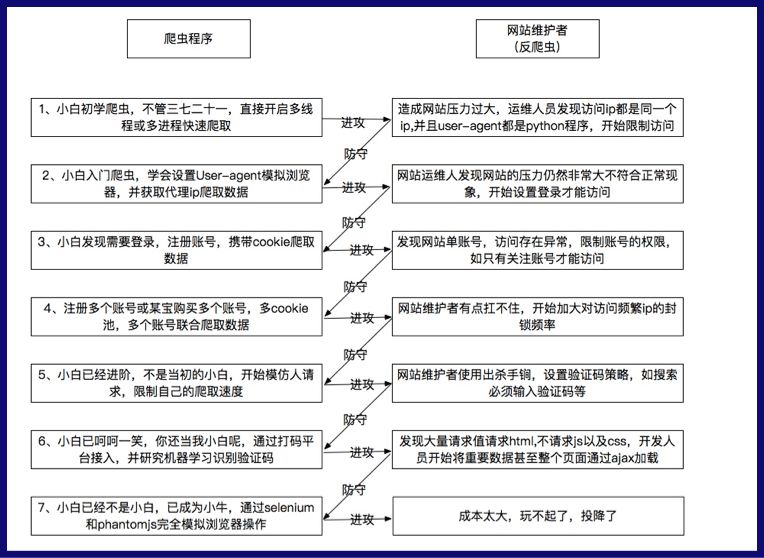
10. 简答题:这张图还可以再往下补充的进攻和防守轮回是什么?
点击下方空白区域查看答案
▼
参考答案
其实可以补充的有很多了,真实世界比这张图复杂很多,在这里提供两个思路:
一轮:
反爬的防守:识别出来selenium爬虫,进行数据投毒,给假数据。
爬取的进攻:Android模拟器,模拟正常用户,或者再换一个http client
又一轮:
爬取的进攻:模拟正常用户行为,点击其他功能或者页面
反爬的防守:爬取的限速限流
本文授权转自公众号:
麻瓜编程(easypython)
https://mp.weixin.qq.com/s/hYDF_rnVwadw0aZuEVXcqg
其他内容回复左侧关键词获取:
python :零基础入门课程目录
新手 :初学者指南及常见问题
资源 :超过500M学习资料网盘地址
项目 :十多个进阶项目代码实例
如需了解视频课程及答疑群等更多服务,
请号内回复 码上行动
代码相关问题可以在论坛上发帖提问
bbs.crossincode.com
推荐阅读
经验:Python转行 | 我用Python | 如何提问 | 新手建议
干货:如何debug | 一图学Python | 知乎资源 | 单词表
案例:漫威API | 流浪地球 | 爬抖音 | 查天气 | 智能防挡弹幕 | 红包提醒
欢迎加入
Crossin的编程教室
crossincode.com
请把我们分享给身边爱学习的小伙伴 :)
☟点击文末“阅读原文”,查看更多学习资源









文章评论