最近正在热播的《新倚天屠龙记》作为一部翻拍了N遍的电视剧,不免会被拿来与之前的作品相比较,其中的一大噱头就是当年马景涛版中饰演周芷若的周海媚此次摇身一变成为了灭绝师太。其实我个人感觉周海媚版的周芷若还是相当棒的!

不过今天的重点不在这里,而是想聊一聊剧中的另一位角色——青翼蝠王韦一笑,这名字一听就很霸气,金庸也曾明言韦蝠王是其笔下轻功第一高手。但是当我看到B站中这段视频的时候却忍不住笑了,这哪里是韦一笑,分明是哮天犬么!
不得不说陈创的代入感实在太强了,我想肯定不止我一个人有这种想法,就去看了下其他观众的观点。
01
首先爬取并查看弹幕信息
考虑到实时弹幕数量更多、观点更犀利,就打算用它来取代评论数据作为此次分析依据。
现在网上有很多爬取B站弹幕的教程,最主流的就是使用API+CID的方法,我试了一下发现不用那么复杂,只要在XHR中找到“list.so?cid=80235675”这个文件就可以了。
文件中的数据是这样的:
这个页面就很好爬取了,写一个简单的小爬虫,把弹幕评论全部取下来并存到TXT文件中以备后用,爬虫代码如下,十行代码搞定。
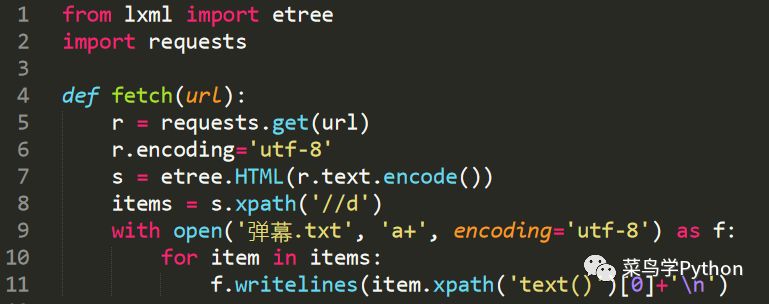
拿到数据后我们先来简单地看下都有哪些观点:

果然不出所料,看来很多观众跟我一样,第一印象不是韦一笑而是哮天犬,大家一眼就认出了这位青翼“犬”王,不得不说陈老师在宝莲灯里刻画的哮天犬真是深入人心啊。
02
弹幕信息进行数据分析
弹幕数据拿到后就可以进行更深层次的分析了,对于大量的中文词句,最常用的方法就是进行中文分词然后绘制词语图。相对于单纯的数字统计,词云图更加直观;相对于绘制统计图表,它又更加全面。
废话不多说,我们先来进行中文分词,以前做这个工作都会使用jieba,不过前些时间看到有人使用pkuseg,正好拿来试验一下。
通过翻看pkuseg的文档,发现其中有一个参数model_name可以用来选择分词模式,简单来说就是针对不同语境选择不同的模式可以提高分词成功率。比如在这里我们的分词对象是网络评论,所以就可以加载对应的网络用于模型。
在下面这段代码中,首先读取弹幕文本,用pkuseg进行分词,然后对照中文停用词表和特殊字符串去除干扰项,最后得到分词结果。

绘制词云图都是老套路了,直接上图看结果:

由于我们取的是整段视频的弹幕,其中自然会有一些关于其他人物的吐槽,比如《倚天》中一位重量级人物——杨逍,还有文章开头提到的周海媚饰演的“最美”灭绝师太,这些都清晰地体现在了词云图中。
再有就是我们本文的主角青翼蝠王了,仔细一看图中充斥着“哮天犬、狗王、养眼、青毛犬、啸天、蝠贵、病狗、黄眉大王”等字样,不得不说我们的网友还真是腹黑,也难为他们能想出这么多形象的词语。
03
最后比对一下分析效果
上面用pkuseg进行了分词分析,效果到底怎样还没办法得出准确的判断,下面就用传统的jieba再进行一次分词,比对一下结果。
jieba分词的过程与pkuseg基本相似,只需要将上面代码中的:
seg = pkuseg.pkuseg(model_name='web')
pkwords = seg.cut(txt)
替换成:
jbwords = jieba.cut(txt)
其他部分稍作修改就可以了。分词结束后再来绘制词云图看看结果:

在这幅图中,“杨戬、哮天、蝙蝠侠”等与青翼蝠王有关主题的字样更加突出,然而仅通过这一点似乎不能说明jieba的分词效果比pkuseg优秀,还是要进一步进行定量的比对。


使用python的内置模块collections中的Counter方法对分词结果进行定量统计,上面的图是pkuseg的分词结果次词频统计,下面这幅图是jieba的分词结果词频统计。可以看到,pkuseg成功地将“杨逍”保存了下来,而对于“周芷若”、“灭绝师太”等词语的判断jieba更胜一筹。
剧中美女非常多,尤其是4大女主角,说说你心中的女神是谁,欢迎留言吱一声!
需要源码可以在小号领取
大家支持一下我的小号
扫码输入:【倚天屠龙记】

长按识别二维码关注
近期热门:

文章评论