
作者:胡言 R语言中文社区专栏作者
知乎ID:
https://www.zhihu.com/people/hu-yan-81-25
前言
我的天空里没有太阳,总是黑夜,但并不暗,因为有东西代替了太阳。虽然没有太阳那么明亮,但对我来说已经足够。凭借着这份光,我便能把黑夜当成白天。你明白吗?我从来就没有太阳,所以不怕失去。”
每每读完一本东野圭吾的书,我都要感慨一次:《白夜行》真是太好看了!
本文利用R和python分别对该书做分词并画词云,为今后更深一层的文本分析打基础。
R语言最常用的分词包为jiebaR和Rwordseg,jiebaR分词对名称识别更有优势,Rwordseg效率更高。安装包时需要为电脑安装java,安装过程较繁琐,请各位看官自行百度。
1library(rJava)
2library(Rwordseg)
3library(wordcloud2)
将《白夜行》小说txt版本读入R,查看wordbase有7851行:
1setwd('C:/Users/Administrator/Documents/GitHub/play_20180925_wordcloud_whitenight')
2wordbase<-read.csv("white_night.txt")
3dim(wordbase)OutPut
1## [1] 7851 1
清除小说中的各种标点符号,这里用到类似正则表达式的gsub()函数:
1word_clean<-NULL
2word_clean$msg <- gsub(pattern = " ", replacement ="", wordbase[,1])
3word_clean$msg <- gsub("\t", "", word_clean$msg)
4word_clean$msg <- gsub(",", "???", word_clean$msg)
5word_clean$msg <- gsub("~|'", "", word_clean$msg)
6word_clean$msg <- gsub("\\\"", "", word_clean$msg)
7#head(word_clean)
将清理后的文本进行分词,此处手动加入不希望被拆散的词“亮司”、“雪穗”,jieba包对人名的识别很厉害,在后文python部分我们可以看一下二者的对比:
1insertWords(c('亮司','雪穗'))
2seg_word<-segmentCN(as.character(word_clean))
3head(seg_word)
OutPut
1## [1] "c" "阿" "日本" "第一" "畅销书" "作家"
segmentCN()函数将文本拆成了单个的词汇。
将分词后的结果做频数统计:
1words=unlist(lapply(X=seg_word, FUN=segmentCN))
2word=lapply(X=seg_word, FUN=strsplit, " ")
3v=table(unlist(word))
4v<-rev(sort(v))
5d<-data.frame(word=names(v),cnt=v)
6d=subset(d, nchar(as.character(d$word))>1)
7d[1:30,]
OutPut
1## word cnt.Var1 cnt.Freq
2## 22 雪穗 雪穗 823
3## 23 没有 没有 806
4## 28 什么 什么 716
5## 49 知道 知道 483
6## 60 一个 一个 410
7## 66 一成 一成 369
8## 67 他们 他们 355
9## 72 这么 这么 341
10## 73 自己 自己 335
11## 74 因为 因为 332
12## 77 这个 这个 313
上述结果为部分截取,我们可以看到雪穗是小说中出现次数最多的词,而亮司却不在前10位。
但是出现次数最多的词汇里,“没有”、“什么”、“一个”等词没有任何意义,因为任何作品都会
用到这些最常用的词,所以我们下一步需要去掉停用词stopwords。
1write.table(v,file="word_result2.txt")
2ssc=read.table("word_result2.txt",header=TRUE)
3class(ssc)
4ssc[1:10,]
5ssc=as.matrix(d)
6stopwords=read.table("wordclean_list.txt")
7class(stopwords)
8stopwords=as.vector(stopwords[,1])
9wordResult=removeWords(ssc,stopwords)
10#去
11kkk=which(wordResult[,2]=="")
12wordResult=wordResult[-kkk,][,2:3]
13wordResult[1:40,]
OutPut
1## cnt.Var1 cnt.Freq
2## 22 "雪穗" "823"
3## 90 "男子" "285"
4## 118 "调查" "218"
5## 121 "警察" "215"
6## 122 "电话" "214"
7## 123 "东西" "212"
8## 131 "回答" "195"
9## 132 "发现" "195"
10## 137 "工作" "189"
11## 149 "公司" "173"
12## 155 "声音" "167"
去停用词后,出现频数很高的词汇,我们明显可以感到《白夜行》特有的严肃和悲凉的气息。
终于可以画词云了,
星星词云:
1write.table(wordResult,'white_night_cloud.txt')
2mydata<-read.table('white_night_cloud.txt')
3#mydata<-filter(mydata,mydata$cnt>=10)
4wordcloud2(mydata,size=1,fontFamily='宋体')

亮司与雪穗:
1write.table(wordResult,'white_night_cloud.txt')
2mydata<-read.table('white_night_cloud.txt')
3#mydata<-filter(mydata,mydata$cnt>=10)
4wordcloud2(mydata,size=4,fontFamily='楷体',figPath='boyandgirl.jpg')
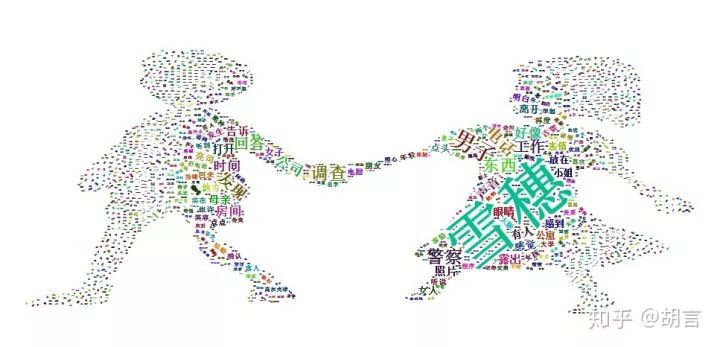
python同样可以画词云,用到jieba、wordcloud模块。
画词云的过程中需要用到ttf格式的字体,需要手动下载。
1from os import path
2from wordcloud import WordCloud, ImageColorGenerator
3import jieba
4import pandas as pd
5import numpy as np
6from scipy.misc import imread
7from PIL import Image
用同样的文本,即《白夜行》小说的txt文件,
1txt=open('white_night.txt',encoding="gbk")
2line=txt.readlines() #读取文字
3type(line) #list无法完成jieba分词
4line=','.join(line) #将list转化为str
5type(line)
1stoplist=open('wordclean_list.txt',encoding="gbk")
2stopwords = [line.strip() for line in open('wordclean_list.txt', 'r',encoding="gbk").readlines()]
3#stopwords={}.fromkeys([line.rstrip() for line in stoplist]) #字典
4for add in ['雪穗','桐原','笹垣','友彦','唐泽','秋吉','筱冢','今枝','典子','利子','一成','']:
5 stopwords.append(add)
6#stopwords=','.join(stopwords) 此处不需要转化为string
1word_list=jieba.cut(line,cut_all=False)
2#word_cut=','.join(word_list)
3word_cut=list(word_list)
4type(word_cut
1cloud_mask = np.array(Image.open('/Users/huxugang/Github/boyandgirl.jpeg'))
2
3back_color = imread('/Users/huxugang/Github/boyandgirl.jpeg')
4image_colors = ImageColorGenerator(back_color)
5
6wd=WordCloud(font_path='/Users/huxugang/Github/wordcloud_whitenight/simhei.ttf',\
7 background_color='white',max_words=500,
8 max_font_size=30,
9 random_state=15,
10 width=1200, # 图片的宽
11 height=400, #图片的长
12 mask=cloud_mask)
13
14WD=wd.generate(word_cut)
15
16import matplotlib.pyplot as plt
17WD.to_file('whitenight.jpg')
18# 显示词云图片
19plt.figure(figsize=(10,10))
20plt.axis('off') #去掉坐标轴
21plt.imshow(WD.recolor(color_func=image_colors))
22#plt.show()

比较R语言和python,个人感觉R语言的wordcloud更人性化一下,字体设置更方便,更漂亮。
python画的词云可以实现字体颜色向背景图片同化(R语言是否可以我尚不清楚,有机会再研究),字体设置不太方便。两种工具我都将继续学习,做更多更有趣的实践。
愿世间没有伤害,愿天底下的雪穗和亮司都能无忧无虑地成长,快乐幸福地度过一生。

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
给我【好看】
你也越好看!


文章评论