
源 / 程序员共成长
前两天,公众号咪蒙注销成为热点话题。历史文章都不能看了,好在今天一个小伙伴分享了咪蒙所有文章的压缩包。
因为是直接从文件中读取数据,相比于从公众号中抓取文章要方便很多。最吸引我的说实话就是标题,读者都是被标题吸引了才去选择是否读你的文章。咪蒙这一点真的厉害。
总共1013篇文章,直接读取文件夹中的所有文件就好,
import os
import re
files = os.listdir(r"E:\BaiduNetdiskDownload\咪蒙\咪蒙全部文章PDF")
for i in files:
# 通过正则匹配标题中的日期
mat = re.search(r"(\d{4}_\d{1,2}_\d{1,2} )", i)
re_str = mat.groups()[0]
# 替换日期和文件后缀名
file_name = i.replace(re_str,'').replace('.pdf','')
# 去掉图片标题
if file_name == "分享图片":
continue
print(file_name)

更直观的去看标题,可以通过WorldCloud生成词云图。这里文章太多,生成所有标题的词云可能看不太清,所以只生成了近期部分标题。
import numpy as np
from PIL import Image
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取所有文件的标题,存在txt文本中
with open('标题.txt', 'r', encoding='utf-8') as f:
word = (f.read())
f.close()
# 图片模板和字体
image = np.array(Image.open('背景图片.jpg'))
# 指定字体,否则汉字不显示
font_path='yahei.ttf'
# 结巴粉刺
wordlist_after_jieba = jieba.cut(word)
# 分词结果
wl_space_split = " ".join(wordlist_after_jieba)
# 关键一步
my_wordcloud = WordCloud(scale=4, font_path=font_path,mask=image, background_color='white',
max_words=1000, max_font_size=55, random_state=24).generate(wl_space_split)
# 显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
# 保存生成的图片
my_wordcloud.to_file('result.jpg')
为了美观用在线工具生成了词云,就假装是我生成的吧


从上图中看出来,真的是在标题上煞废了苦心。标题只是让用户打开,只有内容才能真正的留住用户。那究竟什么内容这么吸引人呢?
因为拿到的文件格式是PDF文件,因此可以通过Python的pdfminer3k库进行操作。
安装库
pip3 install pdfminer3k
代码如下
import sys
import importlib
import os
importlib.reload(sys)
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
def readPDF(path, toPath):
# 以二进制的形式打开PDF文件
with open(path, "rb") as f:
# 创建一个PDF解析器
parser = PDFParser(f)
# 创建PDF文档
pdfFile = PDFDocument()
# 文档放入解析器中
parser.set_document(pdfFile)
pdfFile.set_parser(parser)
# 初始化密码
pdfFile.initialize()
# 检测文档是否可以转换成txt
if not pdfFile.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 解析数据
# 数据管理
manager = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(manager, laparams=laparams)
# 解释器对象
interpreter = PDFPageInterpreter(manager, device)
# 开始循环处理,每次处理一页
for page in pdfFile.get_pages():
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
if(isinstance(x, LTTextBoxHorizontal)):
with open(toPath, "a") as f:
str = x.get_text()
# print(str)
f.write(str.encode("gbk", 'ignore').decode("gbk", "ignore")+"\n")
path = r"E:\BaiduNetdiskDownload\咪蒙\咪蒙全部文章PDF"
# 获取文件下所有PDF文件数组
files = os.listdir(r"E:\BaiduNetdiskDownload\咪蒙\咪蒙全部文章PDF")
for i in files:
# 拼接文件路径
content_url = path + '/' + i
readPDF(content_url, 'content.txt')
print(f"{content_url} 读取完成")
全部文章大概300多万字左右,这里推荐使用多线程去操作。然后进行数据清洗,因为资料包里有些不相关的推广信息,以及文章的编辑、排版、配图人员的署名、日期等信息。
然后通过分词计算出热点关键词出现的次数。
import jieba
import csv
article = open('content.txt','r').read()
words = list(jieba.cut(article))
articleDict = {}
for w in set(words):
if len(w)>1:
articleDict[w] = words.count(w)
articlelist = sorted(articleDict.items(),key = lambda x:x[1], reverse = True)
#打开文件,追加a
out = open('mm_csv.csv','a', newline='')
#设定写入模式
csv_write = csv.writer(out,dialect='excel')
for i in range(10):
# 关键词
word = articlelist[i][0]
# 出现次数
num = articlelist[i][1]
arr = [word, num]
csv_write.writerow(arr)
print('已保存为csv文件.')
结果如下图所示

发现出现了很多社交关系中的称呼词。为了更直观的展示,可以通过pyecharts进行柱状图显示。
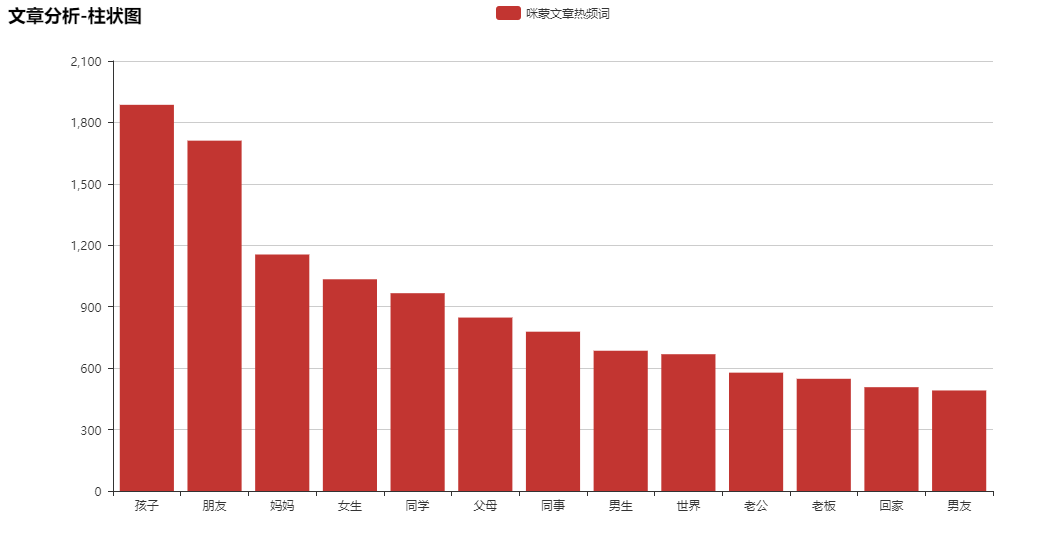
文章中大部分从孩子、父母、男生、女生、闺蜜等话题展开。另外之所以朋友这个词出现在前面,因为很多文章都是讲述"朋友"的故事。
之前看过一篇文章,分析了咪蒙的微博(现已关闭),粉丝将近200W,其中女性粉丝占据了85%。年龄段在23-28岁之间,这个年龄段的女生对理想中的生活比较向往,而咪蒙的文章就是说出了他们的心声,文中狂喷渣男,直男。作为理工男加程序员我的内心是这样子的。

最后根据高频词生成了一个词云图,背景图片用的是咪蒙的头像。

写在最后
翻了几篇文章发现配图非常的小清新,可能就是用来掩盖鸡汤的毒吧。《寒门状元之死》在网上扒出了许多槽点,为了人气不惜歪曲事实,虚构场景。而且很多文章中出现频繁出现不雅词语。

引用网上的一句话
一部分人讨厌咪蒙,
是因为无法忍受文明世界里一个满口脏话的公知,
是因为我们受够了她不良的蛊惑,
是因为我们相信我们关注的公众号应该有底线和正确的三观,
是因为我们还是一群有良知有思考的年轻人。
比起这种大起大落,我更愿意体会那些渺小的成就感。
比如,程序启动一切正常,说服产品不改需求了,发现BUG就知道哪里出了问题。
-END-
转载声明:本文选自「 程序员共成长 」
重磅推出全新学习模式
用打卡学Python
每天30分钟
30天学会Python编程

世界正在奖励坚持学习的人!

文章评论