
阅读文本大概需要 3 分钟。
今早朋友圈已经被张小龙的四小时演讲给刷了屏,张小龙一手缔造了微信帝国,被誉为中国最牛逼的产品经理,他的一言一行都会产生巨大的影响,刷屏也是预料之中的事。但随着演讲文章刷屏的同时,另一张图片也疯狂被转发,来自饭统的戴老板。

不得不说作为产品之神的张小龙,如今的境界已经不是普通人可以触达的。
做为技术人的我,第一眼看到这张图的时候,大脑就想到如果用 Python 统计演讲稿,又会是哪些词被提及最多?想到这里不一会儿我就写了一段代码,输出了以下内容。
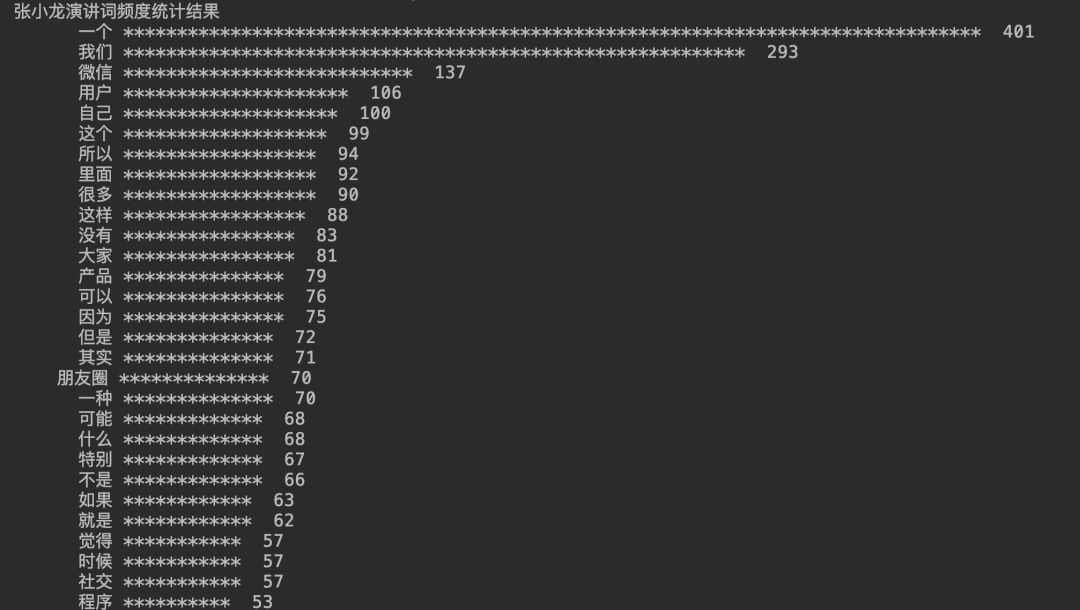
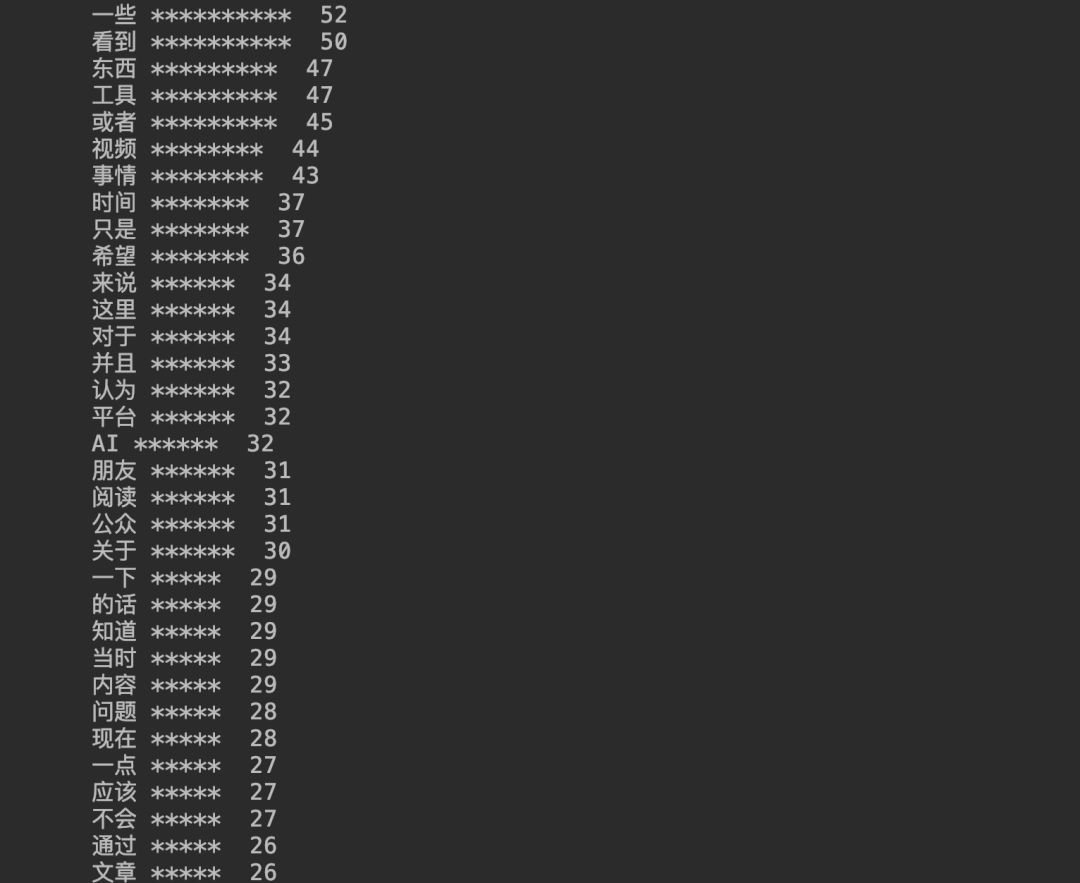

Python 统计的词频与上面的结果不谋而合。那文中所说的词频统计我们要如何实现?
其实对 Python 来说要想实现对中文词频的统计,是非常简单的一件事,要写的代码总共不到 21 行就可以完成。这里我就要给大家介绍一个非常牛逼的中分分词库「jieba」。
一 jieba 库

GitHub 地址:https://github.com/fxsjy/jieba
“结巴”中文分词:做的最好的 Python 中文分词组件
特点
-
支持三种分词模式:
-
精确模式,试图将句子最精确地切开,适合文本分析;
-
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
-
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
-
支持繁体分词
-
支持自定义词典
-
MIT 授权协议
在 Python 中你只需要使用「pip install jieba」即可安装使用。接下来我们看看具体的代码实现,如何用 Python 统计张小龙的演讲词频。
二 词频统计代码实现
程序非常的简单总共不到 21 行代码。首先导入我们要统计的文本,然后用 jieba.cut() 函数,得到一个分词后的 list。随后我们在用 collections 的 Counter 来帮我们筛选出,排名前 100 的分词数,最后再按一定的格式输出就好。
#! python3
# -*- coding: utf-8 -*-
import os, codecs
import jieba
from collections import Counter
def get_words(txt):
seg_list = jieba.cut(txt)
c = Counter()
for x in seg_list:
if len(x) > 1 and x != '\r\n':
c[x] += 1
print('常用词频度统计结果')
for (k, v) in c.most_common(100):
print('%s%s %s %d' % (' ' * (5 - len(k)), k, '*' * int(v / 5), v))
if __name__ == '__main__':
with codecs.open('weixin.txt', 'r', 'utf8') as f:
txt = f.read()
get_words(txt)
程序中所用到的演讲文本,我已上传到后台上,公众号回复「演讲」即可获得。
推荐阅读:
人必有痴,而后有成


文章评论