
2018 AI 开发者大会是一场由中美人工智能技术高手联袂打造的 AI 技术与产业的年度盛会!这里有 15+ 硅谷实力讲师团、80+AI 领军企业技术核心人物、100+ 技术&大众实力媒体、1500+AI 专业开发者——我们只讲技术,拒绝空谈!

参加 2018 AI 开发者大会,请点击 ↑↑↑

相信各位同学多多少少在拉钩上投过简历,今天突然想了解一下北京Python开发的薪资水平、招聘要求、福利待遇以及公司地理位置。
既然要分析那必然是现有数据样本。本文通过爬虫和数据分析为大家展示一下北京Python开发的现状,希望能够在职业规划方面帮助到大家!!!

爬虫
爬虫的第一步自然是从分析请求和网页源代码开始。从网页源代码中我们并不能找到发布的招聘信息。但是在请求中我们看到这样一条Post请求。
如下图我们可以得知:
-
url:
https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false
-
请求方式:Post
-
result:发布的招聘信息
-
total Count:招聘信息的条数
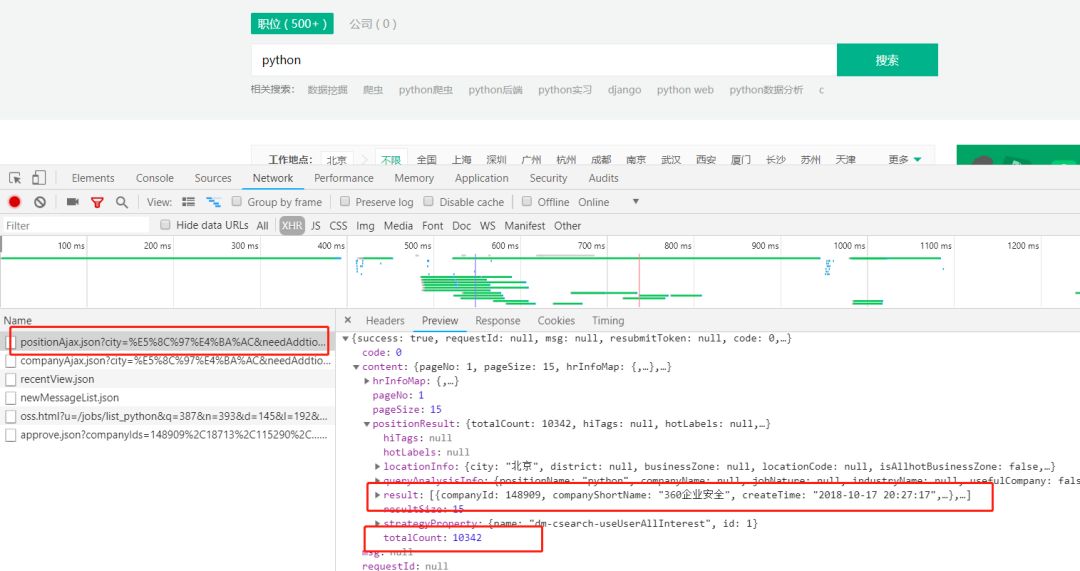
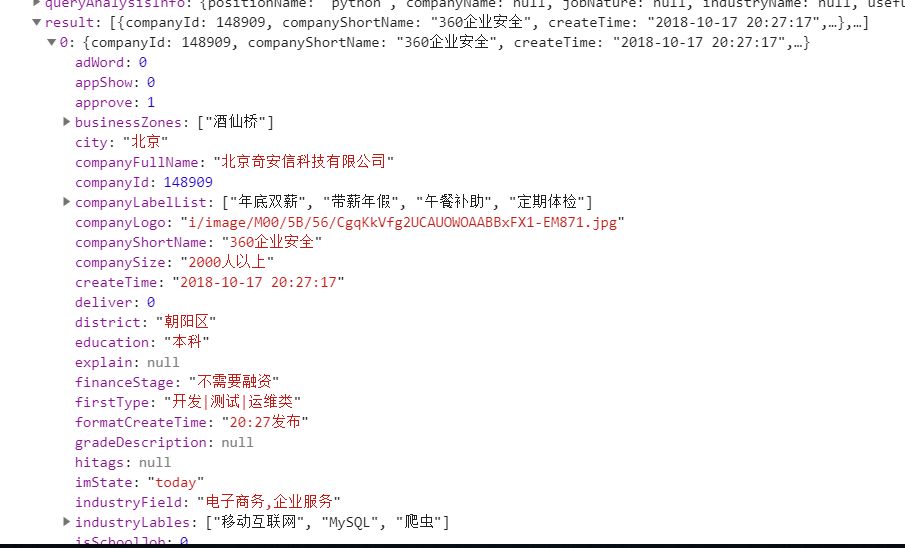
点击查看更清晰
通过实践发现除了必须携带headers之外,拉勾网对IP访问频率也是有限制的。一开始会提示 '访问过于频繁',继续访问则会将IP拉入黑名单。不过一段时间之后会自动从黑名单中移除。
针对这个策略,我们可以对请求频率进行限制,这个弊端就是影响爬虫效率。
其次我们还可以通过代理IP来进行爬虫。网上可以找到免费的代理IP,但大都不太稳定。付费的价格又不太实惠。具体就看大家如何选择了。
1 思路
通过分析请求我们发现每页返回15条数据,total Count又告诉了我们该职位信息的总条数。
向上取整就可以获取到总页数。然后将所得数据保存到CSV文件中。这样我们就获得了数据分析的数据源!
Post请求的Form Data传了三个参数:
-
First : 是否首页(并没有什么用);
-
PN:页码;
-
KD:搜索关键字。
2 No bb, show code
# 获取请求结果
# kind 搜索关键字
# page 页码 默认是1
def get_json(kind, page=1,):
# post请求参数
param = {
'first': 'true',
'pn': page,
'kd': kind
}
header = {
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
# 设置代理
proxies = [
{'http': '140.143.96.216:80', 'https': '140.143.96.216:80'},
{'http': '119.27.177.169:80', 'https': '119.27.177.169:80'},
{'http': '221.7.255.168:8080', 'https': '221.7.255.168:8080'}
]
# 请求的url
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
# 使用代理访问
# response = requests.post(url, headers=header, data=param, proxies=random.choices(proxies))
response = requests.post(url, headers=header, data=param, proxies=proxies)
response.encoding = 'utf-8'
if response.status_code == 200:
response = response.json()
# 请求响应中的positionResult 包括查询总数 以及该页的招聘信息(公司名、地址、薪资、福利待遇等...)
return response['content']['positionResult']
return None
接下来我们只需要每次翻页之后调用getJSON获得请求的结果,再遍历取出需要的招聘信息即可。
if __name__ == '__main__':
# 默认先查询第一页的数据
kind = 'python'
# 请求一次 获取总条数
position_result = get_json(kind=kind)
# 总条数
total = position_result['totalCount']
print('{}开发职位,招聘信息总共{}条.....'.format(kind, total))
# 每页15条 向上取整 算出总页数
page_total = math.ceil(total/15)
# 所有查询结果
search_job_result = []
#for i in range(1, total + 1)
# 为了节约效率 只爬去前100页的数据
for i in range(1, 100):
position_result = get_json(kind=kind, page= i)
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
# 当前页的招聘信息
page_python_job = []
for j in position_result['result']:
python_job = []
# 公司全名
python_job.append(j['companyFullName'])
# 公司简称
python_job.append(j['companyShortName'])
# 公司规模
python_job.append(j['companySize'])
# 融资
python_job.append(j['financeStage'])
# 所属区域
python_job.append(j['district'])
# 职称
python_job.append(j['positionName'])
# 要求工作年限
python_job.append(j['workYear'])
# 招聘学历
python_job.append(j['education'])
# 薪资范围
python_job.append(j['salary'])
# 福利待遇
python_job.append(j['positionAdvantage'])
page_python_job.append(python_job)
# 放入所有的列表中
search_job_result += page_python_job
print('第{}页数据爬取完毕, 目前职位总数:{}'.format(i, len(search_job_result)))
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
ok! 数据我们已经获取到了,最后一步我们需要将数据保存下来。
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=search_job_result,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '工资', '职位福利'])
df.to_csv('lagou.csv', index=False, encoding='utf-8_sig')
运行main方法直接上结果:
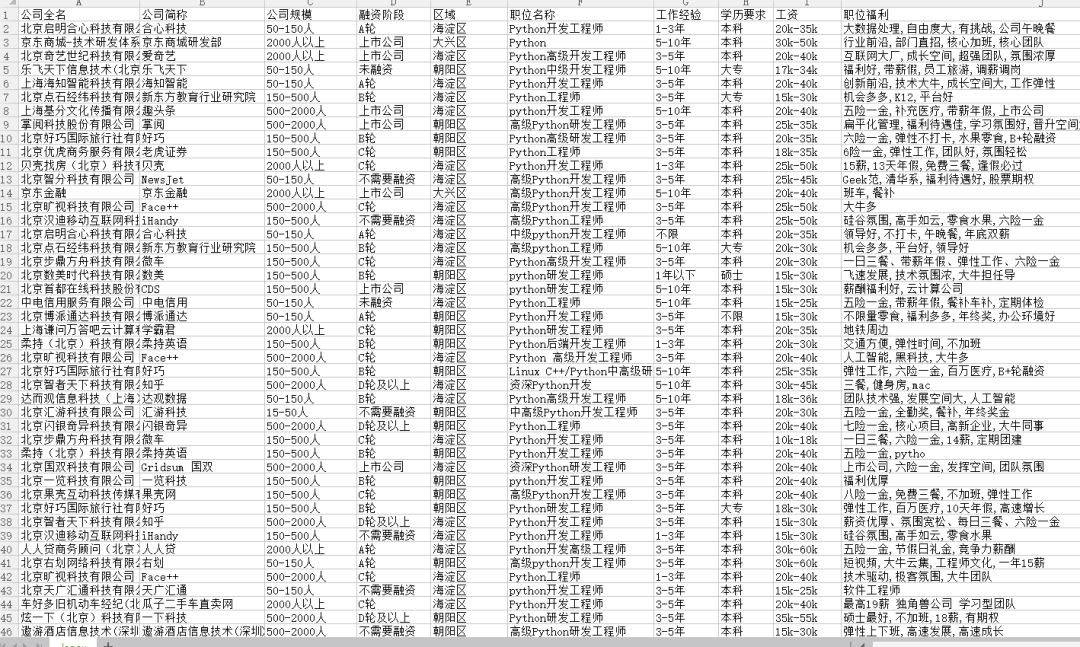
点击查看更清晰

数据分析
通过分析CVS文件,为了方便我们统计,我们需要对数据进行清洗
比如剔除实习岗位的招聘、工作年限无要求或者应届生的当做0年处理、薪资范围需要计算出一个大概的值,而学历无要求的当成大专。
# 读取数据
df = pd.read_csv('lagou.csv', encoding='utf-8')
# 数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# print(df.describe())
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = 'd+'
df['work_year'] = df['工作经验'].str.findall(pattern)
# 数据处理后的工作年限
avg_work_year = []
# 工作年限
for i in df['work_year']:
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
# 如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df['工作经验'] = avg_work_year
# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['工资'].str.findall(pattern)
# 月薪
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] = avg_salary
# 将学历不限的职位要求认定为最低学历:大专
df['学历要求'] = df['学历要求'].replace('不限','大专')
数据通过简单的清洗之后,下面开始我们的统计
1 绘制薪资直方图
# 绘制频率直方图并保存
plt.hist(df['月工资'])
plt.xlabel('工资 (千元)')
plt.ylabel('频数')
plt.title("工资直方图")
plt.savefig('薪资.jpg')
plt.show()
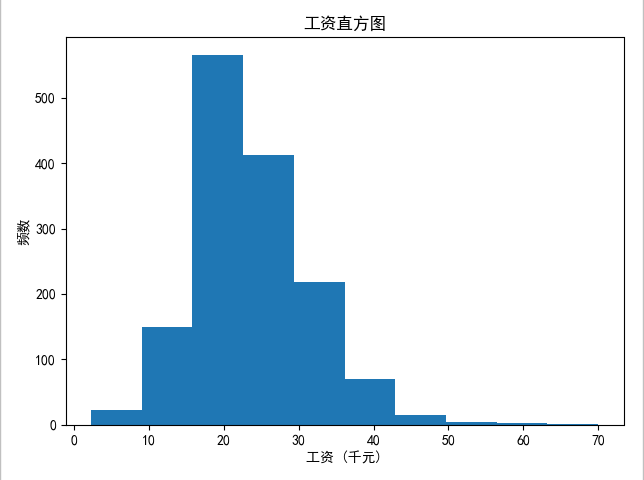
结论:北京市Python开发的薪资大部分处于15~25k之间。
2 公司分布饼状图
# 绘制饼图并保存
count = df['区域'].value_counts()
plt.pie(count, labels = count.keys(),labeldistance=1.4,autopct='%2.1f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('pie_chart.jpg')
plt.show()
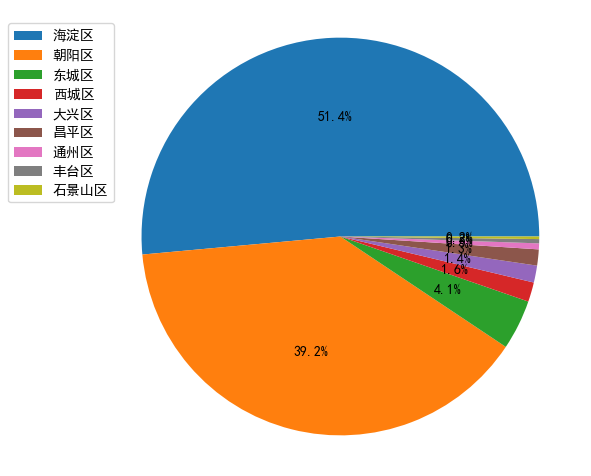
结论:Python开发的公司最多的是海淀区,其次是朝阳区。准备去北京工作的小伙伴大概知道去哪租房了吧
3学历要求直方图
# {'本科': 1304, '大专': 94, '硕士': 57, '博士': 1}
dict = {}
for i in df['学历要求']:
if i not in dict.keys():
dict[i] = 0
else:
dict[i] += 1
index = list(dict.keys())
print(index)
num = []
for i in index:
num.append(dict[i])
print(num)
plt.bar(left=index, height=num, width=0.5)
plt.show()
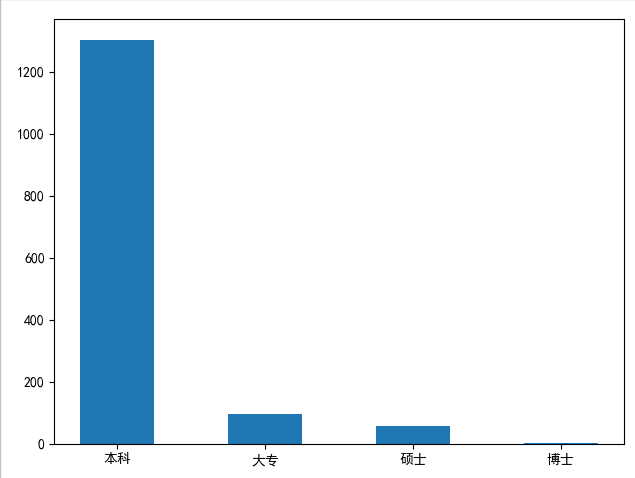
结论:在Python招聘中,大部分公司要求是本科学历以上。但是学历只是个敲门砖,如果努力提升自己的技术,这些都不是事儿
4 福利待遇词云图
# 绘制词云,将职位福利中的字符串汇总
text = ''
for line in df['职位福利']:
text += line
# 使用jieba模块将字符串分割为单词列表
cut_text = ' '.join(jieba.cut(text))
#color_mask = imread('cloud.jpg') #设置背景图
cloud = WordCloud(
background_color = 'white',
# 对中文操作必须指明字体
font_path='yahei.ttf',
#mask = color_mask,
max_words = 1000,
max_font_size = 100
).generate(cut_text)
# 保存词云图片
cloud.to_file('word_cloud.jpg')
plt.imshow(cloud)
plt.axis('off')
plt.show()

结论:弹性工作是大部分公司的福利,其次五险一金少数公司也会提供六险一金。团队氛围、扁平化管理也是很重要的一方面。
至此,此次分析到此结束。有需要的同学也可以查一下其他岗位或者地区的招聘信息哦~ 希望能够帮助大家定位自己的发展和职业规划。
作者:初一,曾在知名互联网公司担任java研发一职,项目带头人。18年中旬转行Python,热爱爬虫喜欢折腾新东西。coding与乐趣同在。Talk is cheap,Show me the code.
声明:本文为作者投稿,版权归其个人所有。

微信改版了,
想快速看到CSDN的热乎文章,
赶快把CSDN公众号设为星标吧,
打开公众号,点击“设为星标”就可以啦!

征稿啦”
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱([email protected])。
推荐阅读:


文章评论