

作者 | 量化小白H
责编 | 郭芮
“不以大小论英雄。”《蚁人2》已热映多天,本文就来看看豆瓣电影上的这部片子评分如何,从代码和数据层面给出最客观的解读。
作为练手,笔者本来打算把豆瓣上的短评爬下来作为分析的素材。然而并没有成功爬到所有的短评,一波三折,最终只爬到了500条,当然这也是豆瓣目前可见的最大数量。
本文将细致分析爬虫的整个过程,并对爬到的数据加以分析,蚁小见大。整篇文章共包含数据爬取和文本分析两部分,因为爬到的数据包含信息较少,所以分析过程相对简单,包含描述统计分析、情感分析和分词词云。

爬虫部分
首先说明一下目标和工具:
-
软件:Python3.6;
-
Packages:selenium jieba snownlp wordcloud(后三个是之后文本分析用的)。
-
目标网址:https://movie.douban.com/subject/26636712/comments?status=P。
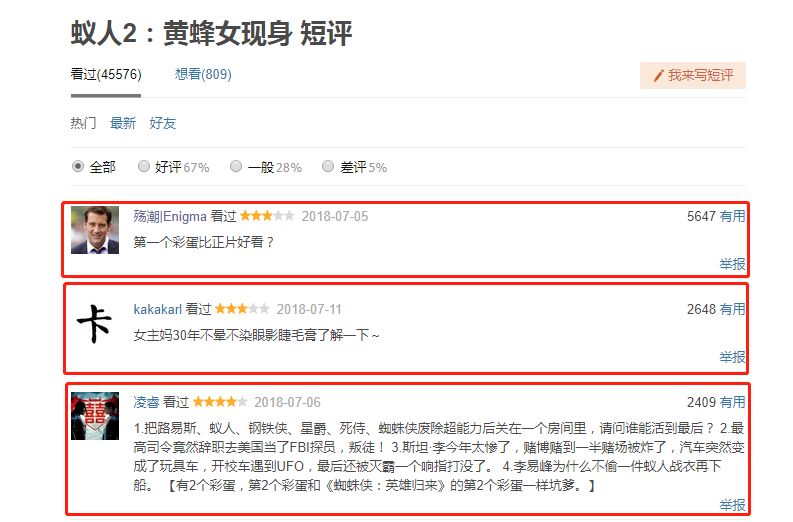
豆瓣上的影评分为两种,一种是长篇大论的影评,还有一种是短评,类似上图。这次爬虫的目标就是上图中红色框线中的短评,信息包括用户名、星级评价、日期、有用数、评论正文。
虽说主页显示45576条,但其实可见的只有500条,每页是20条短评,多一条都不给,手动去点,点到25页之后就没有任何信息了。
第一遍直接用Selenium去爬只爬到了200条,200条之后就自动停止了,后来检查了半天发现必须登录豆瓣上去才能看到更多的评论,然后又加了登陆的代码,之后尝试过程中登陆的次数太多又有了验证码,又加了一个手动输入验证码的部分,最终成功爬到了500条,因为之前没有处理过登陆相关的,所以折腾了很长时间,整体过程如下。
登陆
登陆页面是豆瓣主页https://www.douban.com/,并不是我们爬取的网站,所以首先通过Selenium模拟登陆之后,再获取蚁人2短评页面进行爬虫。
通过Chrome开发者工具获得账户名、密码、验证码的位置、账户名和密码直接输入,验证码获取图片后先存到本地,打开后手动输入,输入之后关掉验证码图片,代码继续执行,就登录成功了,刚开始登的时候不需要验证码。
账户名位置(点开放大):
密码位置(点开放大):

验证码位置(点开放大):
代码如下:
1def gethtml(url):
2 loginurl='https://www.douban.com/' # 登录页面
3
4 browser = webdriver.PhantomJS()
5 browser.get(loginurl) # 请求登录页面
6 browser.find_element_by_name('form_email').clear() # 获取用户名输入框,并先清空
7 browser.find_element_by_name('form_email').send_keys(u'你的用户名') # 输入用户名
8 browser.find_element_by_name('form_password').clear() # 获取密码框,并清空
9 browser.find_element_by_name('form_password').send_keys(u'你的密码') # 输入密码
10
11 # 验证码手动处理,输入后,需要将图片关闭才能继续执行下一步
12 captcha_link = browser.find_element_by_id('captcha_image').get_attribute('src')
13 urllib.request.urlretrieve(captcha_link,'captcha.jpg')
14 Image.open('captcha.jpg').show()
15 captcha_code = input('Pls input captcha code:')
16 browser.find_element_by_id('captcha_field').send_keys(captcha_code)
17
18 browser.find_element_by_css_selector('input[class="bn-submit"]').click()
19 browser.get(url)
20 browser.implicitly_wait(10)
21 return(browser)爬短评
登录之后,转到我们要爬的蚁人2短评页面。爬完一页之后,找到后页的位置click跳转到下一页继续爬,循环一直到最后一页。
从开发者工具可以看到,第一页的后页XPath是"//*[@id='paginator']/a",之后每一页的后页的xpath都是"//*[@id='paginator']/a[3]"。
但最后一页的XPath不是这两个,因此可以通过循环的方式,第一页之后,只要"//*[@id='paginator']/a[3]"找得到,就跳转到下一页继续爬,直到找不到为止。

具体爬的时候,用一个DataFrame来存所有的信息,一行为一个用户的所有数据,数据位置仍然通过开发者工具获得,细节不再赘述。
相关代码如下:
1def getComment(url):
2 i = 1
3 AllArticle = pd.DataFrame()
4 browser = gethtml(url)
5 while True:
6 s = browser.find_elements_by_class_name('comment-item')
7 articles = pd.DataFrame(s,columns = ['web'])
8 articles['uesr'] = articles.web.apply(lambda x:x.find_element_by_tag_name('a').get_attribute('title'))
9 articles['comment'] = articles.web.apply(lambda x:x.find_element_by_class_name('short').text)
10 articles['star'] = articles.web.apply(lambda x:x.find_element_by_xpath("//*[@id='comments']/div[1]/div[2]/h3/span[2]/span[2]").get_attribute('title'))
11 articles['date'] = articles.web.apply(lambda x:x.find_element_by_class_name('comment-time').get_attribute('title'))
12 articles['vote'] = articles.web.apply(lambda x:np.int(x.find_element_by_class_name('votes').text))
13 del articles['web']
14 AllArticle = pd.concat([AllArticle,articles],axis = 0)
15 print ('第' + str(i) + '页完成!')
16
17 try:
18 if i==1:
19 browser.find_element_by_xpath("//*[@id='paginator']/a").click()
20 else:
21 browser.find_element_by_xpath("//*[@id='paginator']/a[3]").click()
22 browser.implicitly_wait(10)
23 time.sleep(3) # 暂停3秒
24 i = i + 1
25 except:
26 AllArticle = AllArticle.reset_index(drop = True)
27 return AllArticle
28 AllArticle = AllArticle.reset_index(drop = True)
29 return AllArticle调用以下两个函数爬取数据,其实对于豆瓣上别的电影影评,估计稍微改一改也可以爬了:
1url = 'https://movie.douban.com/subject/26636712/comments?status=P'
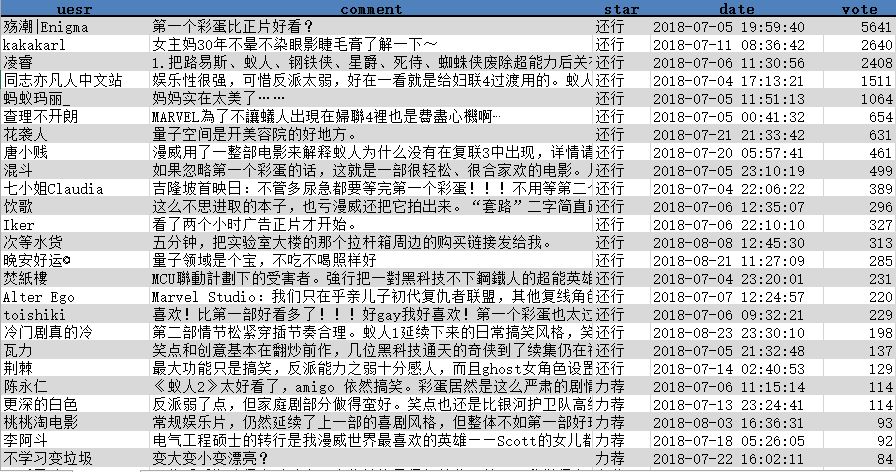
2result = getComment(url)最终爬下来的数据大概是这样子:

文本分析
描述统计分析
首先看一看拿到的样本中各星级评价的分布情况,None表示没有星级评价。

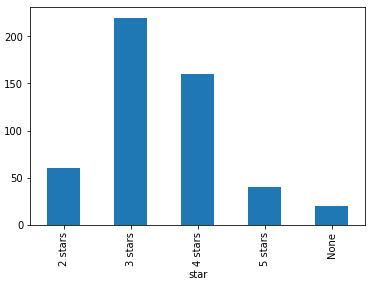
整体来看,三星四星评价巨多,说明大家对于蚁人2整体评价还不错。
再来看看哪些短评大家最认可,投票数最多:
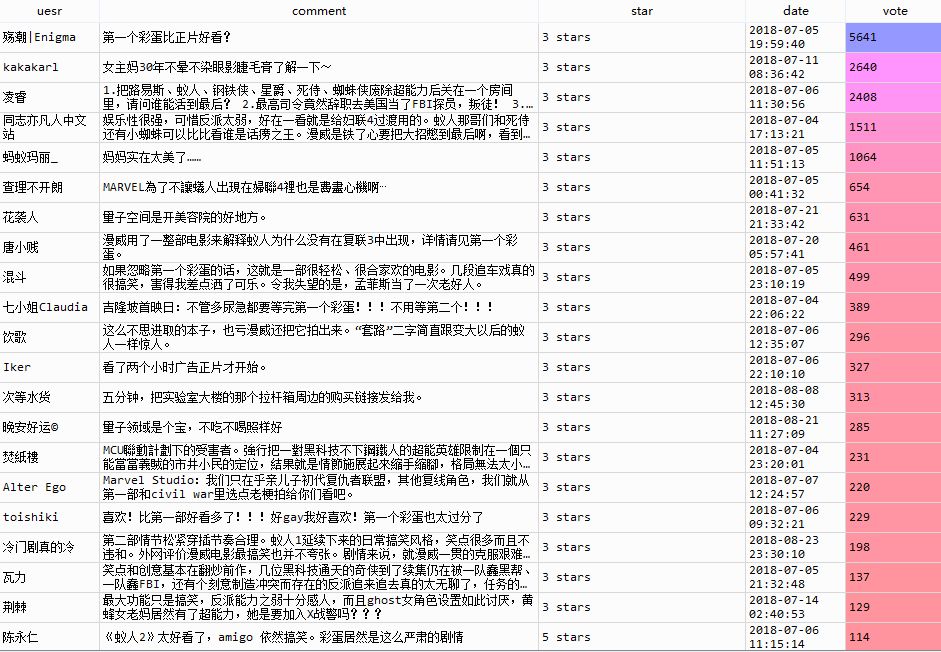
可以看出......

初代黄蜂女的扮演者米歇尔·菲佛也成功引起了广大影迷的注意力。
情感分析
情感分析做得比较简单,主要借助于snownlp包,对于评论的情感倾向进行评分,0-1之间,越正面的情感倾向对应的分值越高。不过根据官方说明,这里用到的模型是用购物评价数据训练出来的,用到这里可能误差会有些大, 姑且一试吧,感觉效果还可以。
1# 情感分析
2def sentiment(content):
3 s = SnowNLP(str(content))
4 return s.sentiments
5
6
7result['sentiment'] = result.comment.apply(sentiment)
8
9# 负面评价
10result.sort(['sentiment'],ascending = True)[:10][['comment','sentiment']]
11
12# 正面评价
13result.sort(['sentiment'],ascending = False)[:10][['comment','sentiment']]先来看看正面评价,sentiment表示情感得分:
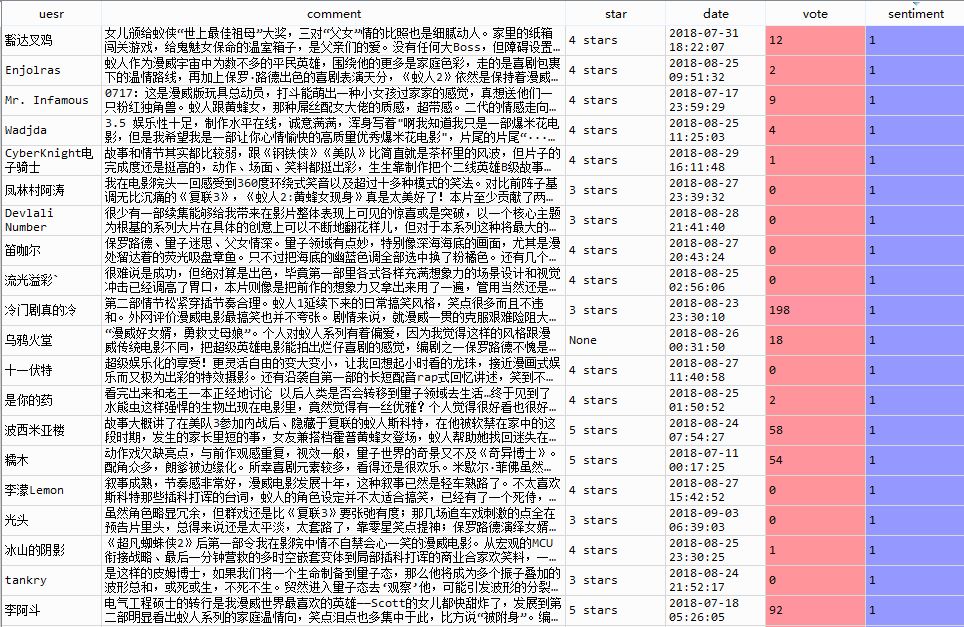
看上去正面评价基本都是高星级评分的观众给出的,有理有据,令人信服。再来看看负面评价:
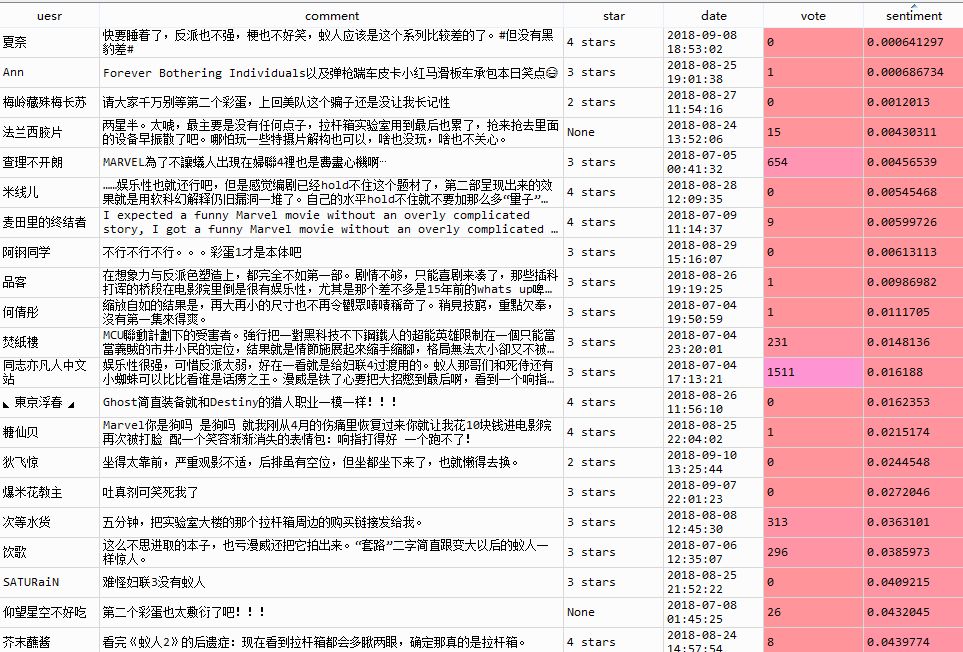
分词词云
通过jieba进行分词,根基TF-IDF算法提取关键词,代码及部分关键词如下:
1texts = ';'.join(result.comment.tolist())
2cut_text = " ".join(jieba.cut(texts))
3keywords = jieba.analyse.extract_tags(cut_text, topK=500, withWeight=True, allowPOS=('a','e','n','nr','ns'))
4
5
6ss = pd.DataFrame(keywords,columns = ['词语','重要性'])
7
8fig = plt.axes()
9plt.barh(range(len(ss.重要性[:20][::-1])),ss.重要性[:20][::-1],color = 'darkred')
10fig.set_yticks(np.arange(len(ss.重要性[:20][::-1])))
11fig.set_yticklabels(ss.词语[:20][::-1],fontproperties=font)
12fig.set_xlabel('Importance')
13
14alice_mask = np.array(Image.open( "yiren.jpg"))
15text_cloud = dict(keywords)
16cloud = WordCloud(
17 width = 600,height =400,
18 font_path="STSONG.TTF",
19 # 设置背景色
20 background_color='white',
21
22 mask=alice_mask,
23 #允许最大词汇
24 max_words=500,
25 #最大号字体
26 max_font_size=150,
27 #random_state=777,
28 # colormap = 'Accent_r'
29 )
30
31
32
33plt.figure(figsize=(12,12))
34word_cloud = cloud.generate_from_frequencies(text_cloud)
35plt.imshow(word_cloud)
36plt.axis('off')
37plt.show()关键词
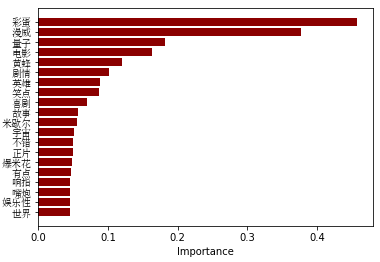
从分词结果来看,"彩蛋"毫无疑问是是蚁人2中大家最关心的点。最后,以蚁人分词词云作为文章结尾!

作者:量化小白一枚,上财研究生在读,偏向数据分析与量化投资,个人公众号量化小白上分记。本文为作者投稿,版权归对方所有。
征稿啦”
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱([email protected])。
————— 推荐阅读 —————





文章评论