
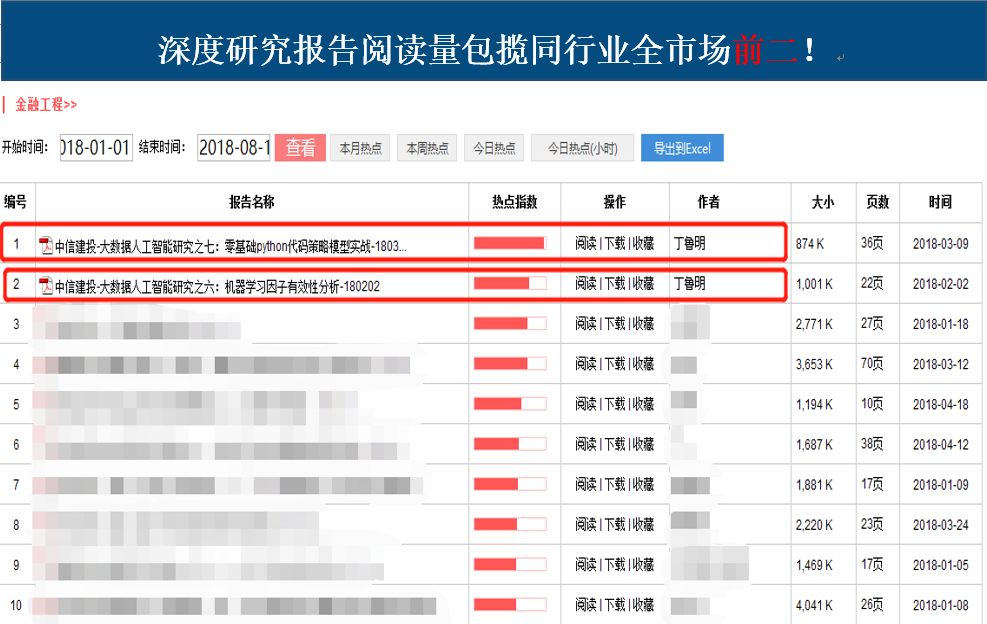
研报市场影响力

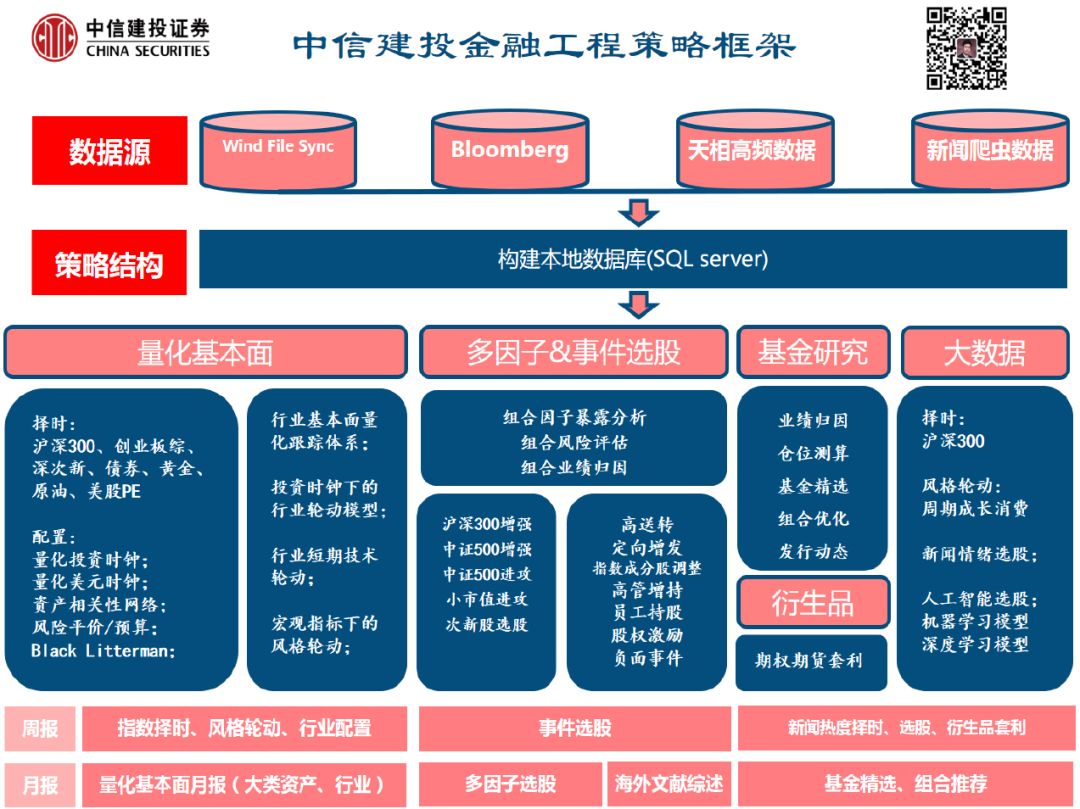
研究框架
研究服务
输入标题
编者按
《中信建投金融工程丁鲁明团队 经典回顾》将与您一起,重温中信建投金融工程团队今年以来的经典深度专题报告。这些专题涉及领域包括量化基本面、大类资产配置、多因子选股和选股策略,以及FOF、大数据及衍生品等。自9月20日起,我们将连续在公众号推出相关专题供您参考。
本文《零基础python代码策略模型实战》,属于大数据选股领域,报告发布时间为2018年3月8日。
正文内容
内容摘要
本文概述
本文主要介绍了python基础、爬虫、与数据库交互、调用机器学习、深度学习、NLP等。分别介绍了各个模块的安装,环境的搭建等。并且以机器学习选股为例,把各个模块连贯起来,核心代码基本都有详尽的解释。
2
大数据AI时代,python无往不胜
Python的包装能力、可组合性、可嵌入性都很好,可以把各种复杂性包装在Python模块里,非常友好的供调用。Python资源丰富,深度学习如keras,机器学习如sk-learn,科学计算如numpy、pandas,自然语言处理如jieba等。
3
Python将极大提高工作效率
无论是科学计算,还是图形界面显示;无论是机器学习还是深度学习;无论是操作excel,txt等还是连接数据库;无论是搭建网站还是爬虫;无论是自然语言处理还是打包成exe执行文件,python都能快速完成。以最少的代码,最高效的完成。
4
人人可编写人工智能模型
人工智能给人感觉难于入手,重要原因是机器学习、深度学习、自然语言处理等门槛太高;python则以最简洁的方式,让你快速使用人工智能相关算法。本文以实战为目的,对模块的安装,搭建环境,核心代码等进行了详细的介绍。
5
人工智能选股模型策略(Logistic为例)
以传统因子滚动12个月值为特征值,个股下一期按收益大小排序,排名前30%作为强势股,排名靠后30%作为弱势股。用机器学习算法进行训练预测。用当期因子作为输入,预测未来一个月个股相对走势的强弱。根据个股的相对强势,我们把排名靠前20%的作为多头,排名后20%的作为空头进行了研究,样本外20090105到20171130期间,行业中性等权年化多空收益差为16.45%,年化波动率为7.34%,最大回撤为10.84%。
 ◢ Part I ◣ Python基础介绍
◢ Part I ◣ Python基础介绍
Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明。有以下优点简单、易学、免费开源、可移植性、解释性强;缺点为单行语句输出、同C++和Matlab比运行速度较慢。Python有较为强大的标准库和模块,方便用户进行调用:如科学计算的Numpy、Pandas、Scipy库;如机器学习和深度学习的Scikit-learn、Keras库;如爬虫的Pyquery、BeautifulSoup、Scrapy库。Python的应用领域较为广泛包括Web开发、人工智能、云计算、网络爬虫,游戏开发等。
一
Python的科学计算库
1、Numpy库
Numpy是Python的一个科学计算的库,提供了矩阵运算的功能,其一般与Scipy、matplotlib一起使用。其实,list已经提供了类似于矩阵的表示形式,不过Numpy为我们提供了更多的函数。操作方法有以下几种:
1) 导入模块;
2) 以list或tuple变量为参数产生一维或者多维度的数组;
3) 通过reshape方法,创建一个只改变原数组尺寸的新数组,原数组的shape保持不变;
4) arange函数通过指定开始值、终值(不包括)和步长来创建一维数组;
5) linspace函数通过指定开始值、终值(包括)和元素个数来创建一维数组;
6) 合并数组可以分为vstack(垂直方向)和hstack(水平方向)操作;

2、Pandas库
pandas核心为两大数据结构,即Series和DataFrame。数据分析相关的所有事务都是围绕着这两种结构进行,pandas库的Series对象是由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即Index)组成。DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尓值等),DataFrame既有行索引(Index),也有列索引(Columns)。
Pandas的相关操作有以下几种:
1) 导入模块(与Numpy类似);
2) 创建Series,DataFrame;
3) 用describe()函数对数据的快速汇总;
4) 运用concat合并DataFrame;
5) 进行groupby分组;
6) 按值进行排序。

3、Scipy库
SciPy库是基于Numpy构建的一个集成了多种数学算法和方便的函数的Python模块。通过给用户提供一些高层的命令和类,SciPy在python交互式会话中,大大增加了操作和可视化数据的能力。

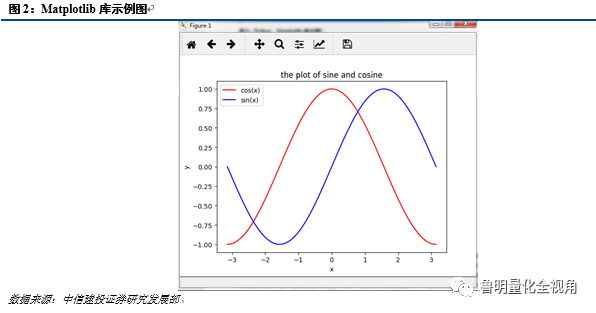
4、Matplotlib库
Matplotlib库是一个用于创建出版质量图表的桌面绘图包(主要是2D方面),这是一个用Python构建的MATLAB式的绘图接口,所以库函数的参数以及调用方法大都与MATLAB一致。以下是Matplotlib使用的简单示例:
二
Python的爬虫相关库
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
网络爬虫的基本工作流程如下:
1) 首先选取一部分精心挑选的种子URL;
2) 将这些URL放入待抓取URL队列;
3) 从待抓取URL队列中取出URL,解析DNS,得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4) 分析已抓取URL队列中的URL,分析其对应网页中的其他子URL,并且将未抓取过的子URL放入待抓取URL队列,从而进入下一个循环。

1、Scrapy库
Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试、信息处理和历史档案等大量应用范围内抽取结构化数据的应用程序框架,广泛用于工业和大数据领域。Scrapy的安装步骤如下:
1) 在dos窗口输入:pip install scrapy回车;
2) 测试scrapy是否安装成功,在dos窗口输入scrapy回车;
Scrapy主要包括了以下组件:
1) 引擎,用来处理整个系统的数据流处理,触发事务。
2) 调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
3) 下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
4) 蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
5) 项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6) 下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与 下载器之间的请求及响应。
7) 蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应

2、BeautifulSoup库
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。BeautifulSoup对象表示的是一个文档的全部内容。大部分时候,可以把它当作Tag对象,它支持遍历文档树和搜索文档树中描述的大部分的方法。BeautifulSoup的安装方法如下:
① 在dos窗口输入pip install beautifulsoup4
② 进入python,输入from bs4 import BeautifulSoup运行,若不报错则安装成功。

3、Pyquery库
Pyquery是一个类似jquery的库, 通过使用lxml来处理xml和html. 所以在使用pyquery时得先安装lxml库,在使用前需要先安装lxml,下载地址如下:
① http://codespeak.net/lxml/lxml-2.2.8.tgz
② http://pypi.python.org/packages/source/p/pyquery/pyquery-0.6.1.tar.gz
快速简便的安装方法是在dos窗口输入:
① pip install libxml2-devel, pip install libxslt (Anaconda一般默认已安装,直接第下一步便可)
② pip install pyquery
到此时安装已经完成。但以作者的经验,不知是PyQuery的bug还是什么原因,对于中文是乱码,解决方法如下:
把pyquery/openers.py 的_requests 函数中的 if encoding: resp.encoding = encoding
换成 resp.encoding = encoding or None

以上是目前主流的一些爬虫框架,相对来说,Scrapy功能最强大,BeautifulSoup比较经典,Pyquery则处理中文更加友好。当然,在爬虫中,会比样例复杂太多,爬虫者对css,js等前端技术有了解则更好,有些目标网页可能会有反爬虫机制,这是一个斗智斗勇的过程,你可能需要设置代理IP,模拟浏览器等相关技术。
三
Python的数据交互
Python提供了多种数据的接口包括与MySQL,SQL Server,Wind等多类数据库,同时对于小批量的数据格式,例如csv、excel和txt等文件也可以完成数据的导入和导出。
1、Python与数据库的交互
PyMySQL是用于Python连接MySQL数据库的接口,在使用之前需要安装,安装的语句为:
pip install pymysql
其主要操作如下:
1) 查询记录;
2) 插入数据;
3) 更新数据;
4) 删除数据。

Pyodbc是用于Python连接SQL Sever数据库的接口,在使用之前需要安装,安装的语句为:
pip install pyodbc
其主要操作如下:
1) 查询记录;
2) 插入数据;
3) 更新数据;
4) 删除数据。

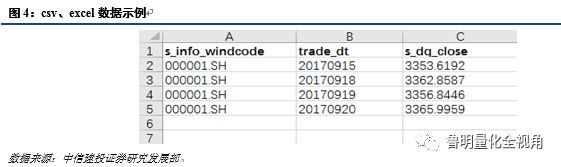
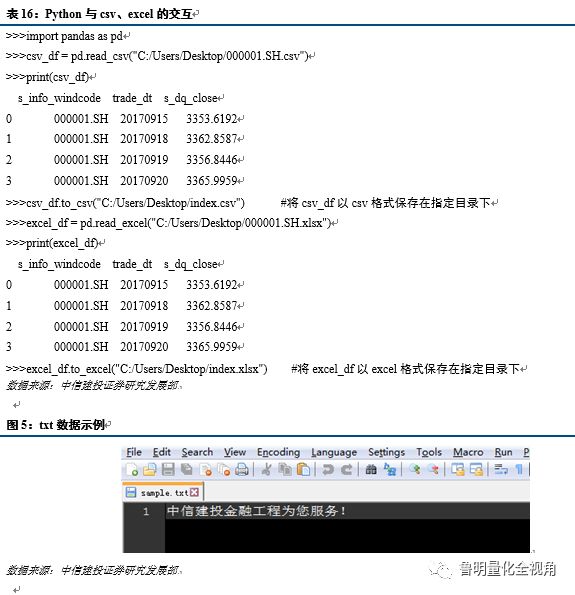
二、 Python与csv、excel和txt文件的交互
对于csv、excel和txt格式的文件,Pandas和Python内置函数提供了导入和保存数据的方法,具体如下:
 三、 Python与Wind客户端的交互
三、 Python与Wind客户端的交互
1) 正常WindPy接口安装
打开Wind资讯终端,点击“量化”选项,出现下方的界面,点击“Python插件”,会弹出广告说明;
2) 特殊安装WindPy方式
假设Wind终端安装在C:\Wind\Wind.NET.Client\WindNET目录(目录下有bin等等子目录),Python安装在C:\python28目录。首先通过Windows进入cmd命令,然后输入如下命令即可:
C:\Python28\python.exeC:\Wind\Wind.NET.Client\WindNET\bin\installWindPy.py C:\wind\wind.net.client\windnet
按任意键WindPy安装过程结束。
说明:以上接口安装说明来自于wind客户端,若有更新,请参考最新wind说明。

◢ Part II ◣ python与人工智能
一
Python自然语言的处理
1、jieba库
jieba是一个python实现的分词库,对中文有着很强大的分词能力。Jieba安装方法为:
pip install jieba
jieba库的优点如下:
1) 支持三种分词模式;
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
2) 支持繁体分词
3) 支持自定义词

除了jieba分词外,还有以外分词库等也非常流行:
1) NLTK库
在使用 Python 处理自然语言的工具中也处于领先的地位。它提供了 WordNet 这种方便处理词汇资源的接口,以及分类、分词、词干提取、标注、语法分析、语义推理等类库。
网站
http://www.nltk.org/
安装 :
pip install -U nltk
2) TextBlob库
TextBlob 是一个处理文本数据的 Python 库。它提供了一个简单的 api 来解决一些常见的自然语言处理任务,例如词性标注、名词短语抽取、情感分析、分类、翻译等等。
网站:
http://textblob.readthedocs.org/en/dev/
安装:
pip install -U textblob
二
Python与机器学习
基于python的机器学习库非常多,主要有以下几类:
1)Scikit-learn 是一个简单且高效的数据挖掘和数据分析工具,易上手,可以在多个上下文中重复使用。它基于NumPy, SciPy 和 matplotlib,开源,可商用(基于 BSD 许可)。
2)Statsmodels 是一个 Python 模块,可以用来探索数据,估计统计模型,进行统计测试。对于不同类型的数据和模型估计,都有描述性统计,统计测试,绘图功能和结果统计的详细列表可用。
3)Shogun 是一个机器学习工具箱,它提供了很多统一高效的机器学习方法。这个工具箱允许多个数据表达,算法类和通用工具无缝组合。
等等。以下主要介绍Scikit-learn。
1、Scikit-learn库
Scikit-learn是Python里面一个机器学习相关的库,它是构建于NumPy, SciPy, and matplotlib基础上的简单高效的数据挖掘和数据分析工具,而且是开源的,内部自带的算法包较多。
安装方法如下:
Anaconda一般都包含了这些包,但有时可能需要更新,更新方法为:
pip install -U scikit-learn
主要内容如下:
1) 按算法的功能分类,分为分类(classification),回归(regression),聚类(clustering),降维,预处理等。sklearn提供了很全面的算法实现;
(具体清单可以参考http://scikit-learn.org/stable/index.html)
2) 测试数据集,比如iris,boston房价等,总共10个左右;
3) 数据预处理,比如二值化,正规化,特征提取;
4) 测试数据选择、测试算法以及确定参数,甚至pipeline化的支持;
5) 其他支持功能,比如评分matrix;
使用sklearn进行计算的主要步骤:
1) 数据准备。需要把数据集整理为输入X[sample_count, feature_count],结果y[label_count]的格式,其中sample_count应该等于label_count;
2) [可选的降维过程],原始数据维度大可能会出现The curse of dimensionality 问题,严重影响性能和算法的扩展性,sklearn会以降维(PCA等)或者一些原型算法(Kmeans,Lasso等,也叫shrinkage)去掉贡献度低的一些维度;
3) 学习以及预测的过程。生成一个算法的预测器Estimator,同时可以自己设置参数,比如K近邻聚类;调用该预测器的fit(x,y)函数对输入数据和结果label进行学习,从中得到学习的结果,即分类器的各种参数;对未知数据进行预测;
4) 反复学习的过程。仅仅使用一个预测器,或者使用一个预测器的一种参数,对未知数据进行预测可能会有不准确性,所以会使用多种策略:把已知的数据分为多份进行多次计算,常用的是k-fold ,k-label-fold, leave-1, leave-1-lable等;多个预测器进行预测,或者独立进行预测,或者组合预测;对一个预测器设置不同的参数进行多次进行预测,同时把数据分组。基本上每一种分类器都有cross- validation(交叉验证)版本,即把预测器加上cv,比如LassoCV。

2、分类算法,以朴素Bayes为例
单一的分类方法主要包括:决策树、贝叶斯、人工神经网络、K-近邻、支持向量机和基于关联规则的分类等;另外还有用于组合单一分类方法的集成学习算法,如Bagging和Boosting等。以下主要介绍朴素贝叶斯。
朴素贝叶斯方法,其中朴素指的是特征条件独立,贝叶斯指的是基于贝叶斯定理。分类:通过学到的概率,给定未分类新实例X,就可以通过上述概率进行计算,得到该实例属于各类的后验概率。具体步骤如下:先计算该实例属于类的概率,再确定该实例所属的分类其中。
下面用具体的sklearn中的案例来说明朴素Bayes分类的应用:

3、回归算法:以 Logistic为例
回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。常见的回归算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)。以下主要介绍Logistic回归。
Logistic回归是研究二分类观察结果与一些影响因素之间关系的一种多变量分析方法。通常的问题是,研究某些因素条件下某个结果是否发生。根据线性回归可以预测连续的值,对于分类问题,我们需要输出0或者1。所以,在分类模型中需要将连续值转换为离散值。我们可以预测: 当大于等于0.5时,输出为y=1;当小于0.5时,输出为y=0。
4、聚类算法:以 k-means为例
聚类指事先并不知道任何样本的类别标号,通过某算法来把一组未知类别的样本划分成若干类别,叫作 unsupervised learning (无监督学习)。在本文中,我们主要介绍一个比较简单的聚类算法:k-means算法。
我们把样本间的某种距离或者相似性来定义聚类,即把相似的(或距离近的)样本聚为同一类,而把不相似的(或距离远的)样本归在其他类。
k-means算法是一种很常见的聚类算法,它的基本思想是:通过迭代寻找k个聚类的一种划分方案,使得用这k个聚类的均值来代表相应各类样本时所得的总体误差最小。k-means算法的基础是最小误差平方和准则。
k-means 算法的主要实现步骤如下:
1) 从N个数据对象中随机挑选k 个对象当作聚类的初始聚类的中心,即种子点;
2) 分别计算剩下其它对象与这些聚类的中心的相似度即其距离,然后将其分别将它们划分给与相似最多的聚类心;
3) 计算该聚类中所有相关对象的平均值,即点群中心点,然后种子点移动到属于他的“点群”的中心;重复2,3过程,一直到其标准测度的函数开始收敛结束,即种子点没有移动。
三
Python与深度学习
目前常用的深度学习框架包括Caffe、CNTK、TensorFlow、Theano和Torch,keras等。
Caffe开始于2013年底,具有出色的卷积神经网络实现。在计算机视觉领域Caffe依然是最流行的工具包,但对递归网络和语言建模的支持很差。在Caffe中图层需要使用C++定义,而网络则使用Protobuf定义。
CNTK中网络会被指定为向量运算的符号图,运算的组合会形成层。CNTK通过细粒度的构件块让用户不需要使用低层次的语言就能创建新的、复杂的层类型。
TensorFlow是一个理想的RNN(递归神经网络) API和实现,TensorFlow使用了向量运算的符号图方法,使得新网络的指定变得相当容易,但TensorFlow并不支持双向RNN和3D卷积,同时公共版本的图定义也不支持循环和条件控制。
Theano支持大部分先进的网络,现在的很多研究想法都来源于Theano,它引领了符号图在编程网络中使用的趋势。Theano的符号API支持循环控制,让RNN的实现更加容易且高效。
Torch对卷积网络的支持非常好。Torch通过时域卷积的本地接口使得它的使用非常直观。Torch通过很多非官方的扩展支持大量的RNN,同时网络的定义方法也有很多种。与Caffe相比,在Torch中定义新图层非常容易,不需要使用C++编程,图层和网络定义方式之间的区别最小。
本文主要介绍keras,原因如下:
1) 纯Python,方便查看/修改源代码
2) 支持theano和Tensorflow两种模式
3) 配置非常简单,可快速搭建自己的模型
4)文档齐全,社区非常活跃
5)封装的非常好,简单好用
1、Keras框架
1)简单介绍
Keras是基于Theano、TensorFlow的一个深度学习框架,它的设计参考了Torch,用Python语言编写,是一个高度模块化的神经网络库,支持GPU和CPU(使用的文档为http://keras.io/)。以下是深度学习几个说明:
激活函数:加入非线性因素的,因为线性模型的表达能力不够
放弃层(Dropout):防止过拟合
损失函数:模型试图最小化的目标函数,衡量模型预测的好坏
池化层:Mean pooling(均值采样)、Max pooling(最大值采样)、Overlapping (重叠采样)、L2 pooling(均方采样)、Local Contrast Normalization(归一化采样)、Stochasticpooling(随即采样)、Def-pooling(形变约束采样)。其中最经典的是最大池化,作用是降维,可以扩大感知野
优化算法:最常用的为SGD算法,也就是随机梯度下降算法
全连接层(Dense):负责分类或者回归;全连接层会丢失一些特征位置信息,矩阵乘法,相当于一个特征空间变换,可以把有用的信息提取整合;维度变换,尤其是可以把高维变到低维,同时把有用的信息保留下来。
2)框架搭建
1) 以Windows版本作为基础环境
2) 目前Tensorflow不支持Windows版本,所以本文选用Theano安装
3) Python环境建议使用Anaconda3
4) 安装Theano ,首先要安装C++ 编译器,因为windows下面没有,所以首先安装MinGw,这是一个GCC的编译环境:
1、在cmd中输入conda install mingw libpython
2、配置环境变量:path:C:\Anaconda\MinGW\bin;C:\Anaconda\MinGW\x86_64-w64-mingw32\lib;
3)、path中还要加入:C:\Anaconda2;C:\Anaconda2\Scripts;
注:以以路径请修改为自己的anaconda所在位置
5) 安装theano库
pip install theano
6) 安装keras库
pip install keras
7) 在用户文件夹的.keras子文件夹下找到keras.json,然后记事本编辑改'tensorflow'为'theano'(不能为Theano,必须全部小写,否则报错)
8) 验证keras是否安装成功
>>> import keras
Using Theano backend.
没有报错则恭喜您,深度学习环境已搭建成功!
2、长短期记忆网络
经济学家靠ARMA模型预测的时间序列模型。该模型对小数据集效果很好,可容纳时间序列的记忆效应,如持久性、均值回归、季节性等。在深入学习中,长短期记忆(Long short-term memory,LSTM)可类比于ARIMA。LSTM是一个循环神经网络,能记忆通过网络预先输入的信息。LSTM对RNN进行了结构上的修改,来避免长期依赖问题。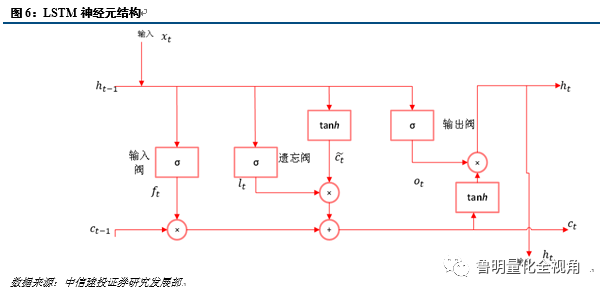

3、卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)一种专门处理图像的特殊的多层神经网络,包括卷积层(alternating convolutional layer)和池层(pooling layer)。CNN的基本结构一般包括两层,一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。随着该局部特征被提取,它与其它特征间的位置关系也确定下来。二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。

◢ Part III ◣ 结论分析
一
人工智能因子打分策略
1、策略代码实战
整体策略模型,我们基本都是模块化编写,即各功能都是严格分开编写,方便后续修改,也方便代码重用。各大模块代码实战分析:
1) 提取数据库模块代码分析
该模块功能主要用于从数据库提取数据,但不作任何处理。

核心代码分析:
def conFactor():
该函数为数据库连接模块,顾名思义,就是连接数据库模块
import pyodbc:导入连接数据库驱动模块,pyodbc用于Python连接sql server数据库
import configInfo:导入参数模块,为了方便修改,我们把所有参数放在该模块
sql_data:查询语句,此处功能是查询指定个股指定时间的指定因子值
cur.execute(sql_data):执行查询语句
for row in cur.fetchall():用于获取所有查询到的数据,然后进行封装。
Python需要严格缩进。否则代码则出错。比如函数体都需要缩进,for循环等也需要缩进。
2) 数据预处理模块
a.没满一年的新股不进行机器学习因子计算:因为需要用最近历史一年的数据作为训练。
b.对于缺失值,用平均值代替,当缺失达到10%,则该因子丢弃。
c. z-score标准化,要求原始数据的分布可以近似为高斯分布,否则效果不好。
对a_value,turnover_1等这一类不不符合高斯分布因子,需要用ln(t1/t0)(同一个股当期与上期比值的对数)进行处理,才近似高斯分布。但对sec_return_1,MACD等这一类变化率等相关因子,直接用原始值便可以,因为他们本身已经近似符合正态分布。
预处理之所有没有处理掉极值和去掉涨跌停个股因子,原因是因为此处只是训练特征,而不是最终选股。再次,我们所选的因子是经过人工核对的,基本没有太多相似性,故也没有降维这一步。

核心代码分析:
from utils import publicVariables:有些公用变量,建议单独建在一个模块,这样方便调用。
from sklearn import preprocessing:导入预处理模块。
temp_factor[i,:] = np.log(factor[i]/temp[i-1]):经验告诉我们,有些因子已经近似为高斯分布,比如动量因子,普通的因子经过取对数后与高斯分布比较接近,比如流动市值因子。
array_data = preprocessing.scale(array_data):z-score标准化,要求原始数据的分布可以近似为高斯分布,否则效果不好。
3) 中性化处理模块
中性化处理我们包含二层含义,一是市值中性化,二是行业中性化。
首先,我们都知道,市值因子对个股的影响十分显著,如果不考虑市值带来的干扰,则我们的策略可能被市值因子带来严重的影响。为此,我们市值分成20组,分别在不同市值组各选取20%作为策略多头与空头,使多头与空头有相同的市值分布,以消除市值可能带来的影响。
其次,众所周知,不同行业,因子特征可能差异明显,放在一起可能不具备可比性。为了去除行业带来的影响,我们也分别在不同行业选取20%作为我们的空头与多头,使多头与空头保持同样的行业暴露,以消除行业带来的影响。
中性化处理代码相对比较简单,且基本是按照逻辑编写便可,在此不作详细介绍。
4) 机器学习模块
机器学习模块是核心,也是重点,也最简单,因为一般情况下,我们没有特殊要求,直接调用现在的机器学习包便可。重点要注意的是处理好数据成机器学习输入的形式就可以了。一般机器学习算法的输入形式为:自变量为n*m数组,n为样本数量,m为因子个数,因变量为对应的标签列表。

核心代码分析:
k = math.floor(np.sqrt(len(array_data))):经验参数,n一般少于训练集的平方根。表示n个邻近。
knn=KNeighborsClassifier(n_neighbors=k,weights='distance'):实例化算法,weights为加权方式,weights='distance',对距离加权,可以降低k值设定的影响。
knn.fit(array_data,list_target) :模型训练拟合。
list_predict = list(knn.predict_proba(array_predict)[:,1]):模型预测结果。
1) 策略计算模块
该模块主要负责计算策略整体评估功能,主要包括:计算多空收益差模块,计算IC模块,分N组计算各组收益模块。主要考虑了以下几种情况:
a. 当期单个因子在全市场缺失达40%时,则该因子丢弃,不进行计算。
b. 调仓当天停牌,涨停,跌停个股剔除。
c. 新股一个月之内不能作为候选股(上市小于20个交易日)。

核心代码分析:
import pandas as pd:导入pandas模块
order_data = pd.Series(order_data):原型为pd.Series(data, index=index), data是数据源,可以是Python字典类型,ndarray或者标量值。index代表轴标签,传递列表类型。若index省略,则默认为[0,1,2,…,len(data)-1]
order_data.corr(order_ret):计算序列order_data与序列order_ret的相关系数。
1) 结果入库模块
该模块功能简单明了,即只是把计算结果保存到数据库。

核心代码分析:
sql = "insert into "+table+tableField+" values("+factors_str+")":插入数据库语句
cur.execute(sql):执行插入数据库语句
conn.commit():提交执行插入数据库语句
except pyodbc.Error as e:
print (sql) :若执行错误则输出。目的是为了调试,出了问题也方便第一时间找到原因。
2、策略结果(以Logistic为例)
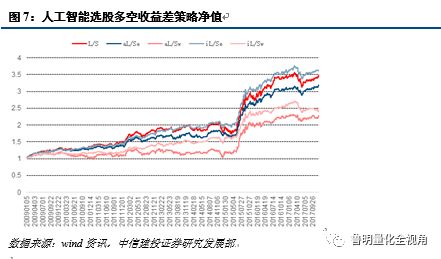
相关说明如下:
1) 所用因子:全市场训练得到的个股未来相对强势值。
2) L/S:全市场选股多空收益差净值。相对强势值排名靠前20%作为多头,相对强势值排名后20%作为空头。
3) aL/Se:市值等权多空收益差净值。分20小组,分别在组内选前20%作为多头,后20%作为空头,最后各组等权。
4) aL/Sw:市值加权多空收益差净值。分20小组,分别在组内选前20%作为多头,后20%作为空头,最后各组以市值组权重加权得到多空组合。
5) iL/Se:行业等权多空收益差净值。在中信一级行业,分别在行业内选前20%作为多头,后20%作为空头,最后各行业以等权到多空组合。
6) iL/Sw:行业加权多空收益差净值。在中信一级行业,分别在行业内选前20%作为多头,后20%作为空头,最后各行业以沪深300行业内权重加权得到多空组合。
◢ Part IV ◣ 一些总结
一
Python股票策略打包成Exe文件
运用pyinstaller打包成exe
在实际运行中,我们可能希望我们的模型能定期在后台运行,比较简单的方法就是打包成exe可执行文件,双点便可在后台运行。Python中提供了可以将.py文件打包成可执行文件exe的pyinstall包,其具体使用步骤如下:
1) 安装:pip install pyinstaller
2) Pyinstaller打包:
D:\Anaconda3\Scripts\pyinstaller.exe -F -w C:\Users\ Desktop\work\testPyinstaller\src\test.py
注:Pyinstaller的根目录:D:\Anaconda3\Scripts\pyinstaller.exe
需要打包的文件目录:C:\Users\ Desktop\work\testPyinstaller\src\test.py
实际运行请对应修改。
3) C:\Users\下面增加了build和dist文件夹,需要的test.exe在dist文件夹内。双击即可在后台运用
更多说明请参考链接:http://www.pyinstaller.org/
二
模型代码编写建议
作为一位量化投资相关人员,虽然编写代码不是核心,但拥有一个良好的编写代码习惯也是提高工作效率的关键。在此给出几点个人的代码编写建议。
1) 在开始编码之前,一定要有个大致的设计,比如模型分几大块:控制层模块(相当于总设计),读取数据模块、数据预处理模块、模型核心算法模块、数据结果保存或者展示模块等(通过情况下,我们一个简单的策略都可以分成这几大块)。
2) 优秀的代码文档跟编程语句一样重要。在代码源文件中,应该为主要的代码段添加注释,解释代码的基本逻辑,若模型交接方便接手人了解代码也方便日后自己回顾。若是日后修正代码,则应该注明修改日期,以及修改的原因。
3) 最好有一个README文件,注明每个源文件、数据文件等的作用。整个模型流程及功能及模型需要注意的事项也应该加以注明。
4) 变量名和函数名称尽可能写得有意义。例如,收盘价数组可定义为array_close,而不是直接写close或者c,array_close非常直观的可以让人知道这是一个array数组,用来存放close的。
5) 重复的代码一定不要出现。可用函数形式,用到时调用。这样方便日后修改,也不会出现某处忘记修改的情况。
6) 最后一项,也不是最不重要的一项,每次修改版本之前,一定要备份,否则出了问题,无法回到之前版本,那将是令人抓狂的一件事情。
输入标题
团队负责人
丁鲁明
中信建投证券金融工程首席分析师
同济大学金融数学硕士,中国准精算师,现任中信建投证券研究发展部金融工程方向负责人,首席分析师。10 年证券从业经验,历任海通证券研究所金融工程高级研究员、量化资产配置方向负责人;先后从事转债、选股、高频交易、行业配置、大类资产配置等领域的量化策略研究,对大类资产配置、资产择时领域均有较深入研究,创立国内“量化基本面”投研体系。多次荣获团队荣誉:新财富最佳分析师2009 第4、2012 第4、2013 第1、2014 第3 等;水晶球最佳分析师:2009 第1、2013 第1 等。
团队成员
王赟杰
上海交通大学数学博士,2016 年加入中信建投研究所金融工程团队,主要从事量化交易策略(包括:衍生品套利、选股等)和基金产品方面研究。
陈元骅
哥伦比亚大学金融数学硕士,专注于衍生品定价及交易策略研究,研究成果包括分级A 的轮动策略、期权套利策略等。
赵 然
中国科学技术大学统计与金融系硕士,专注于量化基本面和资产配置相关研究,研究成果包括全球大类资产配置框架,宏观因子投资体系,美股、原油和黄金等资产定价模型。
陈升锐
芝加哥大学金融数学硕士,三年基金公司量化投资研究工作经验,2018 年加入中信建投研究所金融工程团队,专注于量化选股研究。
段潇儒
上海交通大学安泰经济与管理学院金融学硕士。
胡一江
复旦大学管理学院金融硕士。
郭彦辉
复旦大学经济学院金融硕士。
免责声明:
本公众订阅号(微信号:中信建投金融工程研究)为丁鲁明金融工程研究团队(现供职于中信建投证券研究发展部)设立的,关于金融工程研究的唯一订阅号;团队负责人丁鲁明具备分析师证券投资咨询(分析师)执业资格,资格证书编号为:S1440515020001。
本订阅号不是中信建投证券金融工程研究报告的发布平台,所载内容均来自于中信建投证券研究发展部已正式发布的金融工程研究报告或对报告进行的跟踪与解读,如需了解详细的报告内容或研究信息,请具体参见中信建投证券研究发展部的完整报告。
在任何情况下,本订阅号所载内容不构成任何人的投资建议,中信建投证券及相关研究团队也不对任何因使用本订阅号所载任何内容所引致或可能引致的损失承担任何责任。
本订阅号对所载研究报告保留一切法律权利。
订阅者对本订阅号所载所有内容(包括文字、音频、视频等)进行复制、转载的,需注明出处,且不得对本订阅号所载内容进行任何有悖原意的引用、删节和修改

文章评论