网上爬虫的教程实在太多了,去知乎上搜一下,估计能找到不下一百篇。大家乐此不疲地从互联网上抓取着一个又一个网站。但只要对方网站一更新,很可能文章里的方法就不再有效了。
每个网站抓取的代码各不相同,不过背后的原理是相通的。对于绝大部分网站来说,抓取的套路就那么一些。今天这篇文章不谈任何具体网站的抓取,只来说一个共性的东西:
如何通过 Chrome 开发者工具寻找一个网站上特定数据的抓取方式。
我这里演示的是 Mac 上的英文版 Chrome,Windows 中文版的使用方法是一样的。
> 查看网页源代码
在网页上右击鼠标,选择“查看网页源代码”(View Page Source),就会在新标签页中显示这个 URL 对应的 HTML 代码文本。
此功能并不算是“开发者工具”一部分,但也很常用。这个内容和你直接通过代码向此 URL 发送 GET 请求得到的结果是一样的(不考虑权限问题)。如果在这个源代码页面上可以搜索到你要内容,则可以按照其规则,通过正则、bs4、xpath 等方式对文本中的数据进行提取。
不过,对于很多异步加载数据的网站,从这个页面上并不能搜到你要的东西。或者因为权限、验证等限制,代码中获取到的结果和页面显示不一致。这些情况我们就需要更强大的开发者工具来帮忙了。
> Elements
在网页上右击鼠标,选择“审查元素”(Inspect),可进入 Chrome 开发者工具的元素选择器。在工具中是 Elements 标签页。
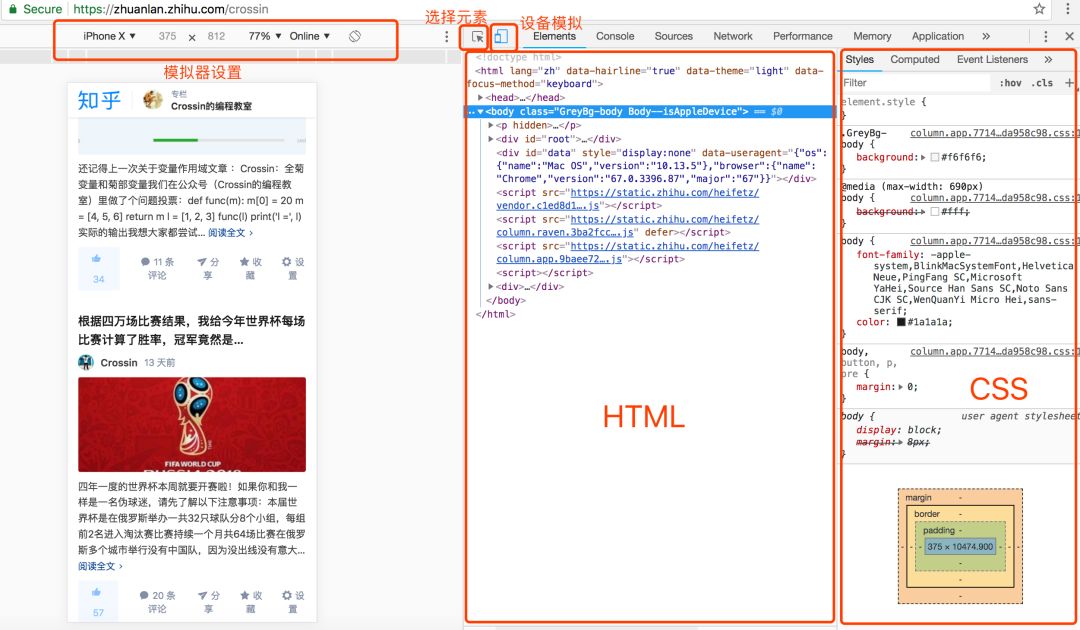
Elements 有几个功能:
-
选择元素:通过鼠标去选择页面上某个元素,并定位其在代码中的位置。
-
模拟器:模拟不同设备的显示效果,且可以模拟带宽。
-
代码区:显示页面代码,以及选中元素对应的路径
-
样式区:显示选中元素所受的 CSS 样式影响
从 Elements 工具里定位数据比我们前面直接在源代码中搜索要方便,因为你可以清楚看到它所处的元素结构。但这边特别提醒的是:
Elements 里看到的代码不等于请求网址拿到的返回值。
它是网页经过浏览器渲染后最终呈现出的效果,包含了异步请求数据,以及浏览器自身对于代码的优化改动。所以,你并不能完全按照 Elements 里显示的结构来获取元素,那样的话很可能得不到正确的结果。
> Network
在开发者工具里选择 Network 标签页就进入了网络监控功能,也就是常说的“抓包”。
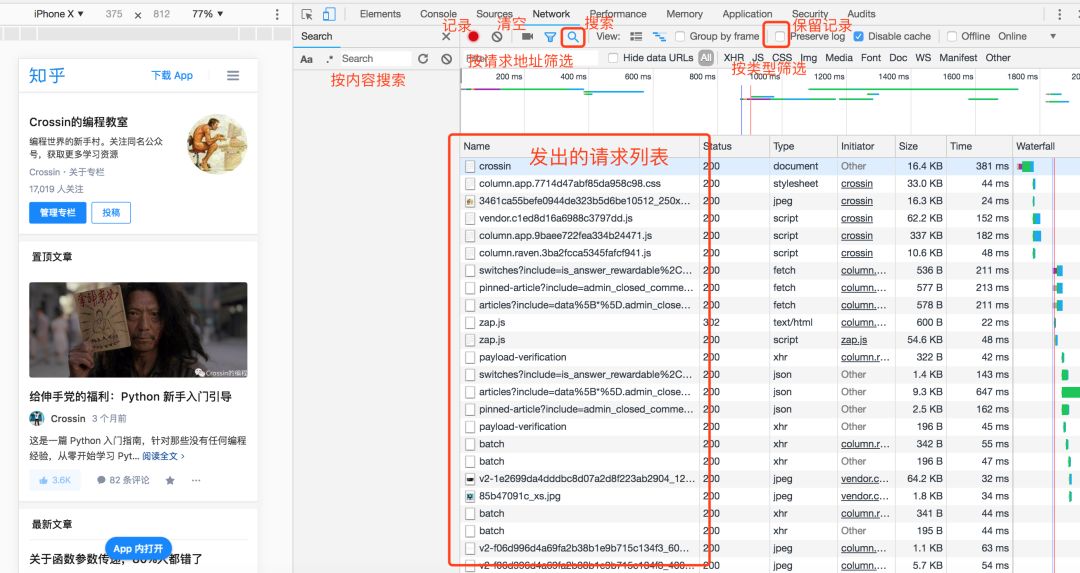
这是爬虫所用到的最重要功能。它主要解决两个问题:
-
抓什么
-
怎么抓
抓什么,是指对于那些通过异步请求获取到的数据,如何找到其来源。
打开 Network 页面,开启记录,然后刷新页面,就可以看到发出的所有请求,包括数据、JS、CSS、图片、文档等等都会显示其中。从请求列表中可以寻找你的目标。
一个个去找会很痛苦。分享几个小技巧:
-
点击“搜索”功能,直接对内容进行查找。
-
选中 Preseve log,这样页面刷新和跳转之后,列表不会清空。
-
Filter 栏可以按类型和关键字筛选请求。
找到包含数据的请求之后,接下来就是用程序获取数据。这时就是第二个问题:怎么抓。
并不是所有 URL 都能直接通过 GET 获取(相当于在浏览器里打开地址),通常还要考虑这几样东西:
-
请求方法,是 GET 还是 POST。
-
请求附带的参数数据。GET 和 POST 传递参数的方法不一样。
-
Headers 信息。常用的包括 user-agent、host、referer、cookie 等。其中 cookie 是用来识别请求者身份的关键信息,对于需要登录的网站,这个值少不了。而另外几项,也经常会被网站用来识别请求的合法性。同样的请求,浏览器里可以,程序里不行,多半就是 Headers 信息不正确。你可以从 Chrome 上把这些信息照搬到程序里,以此绕过对方的限制。
点击列表中的一个具体请求,上述信息都可以找到。
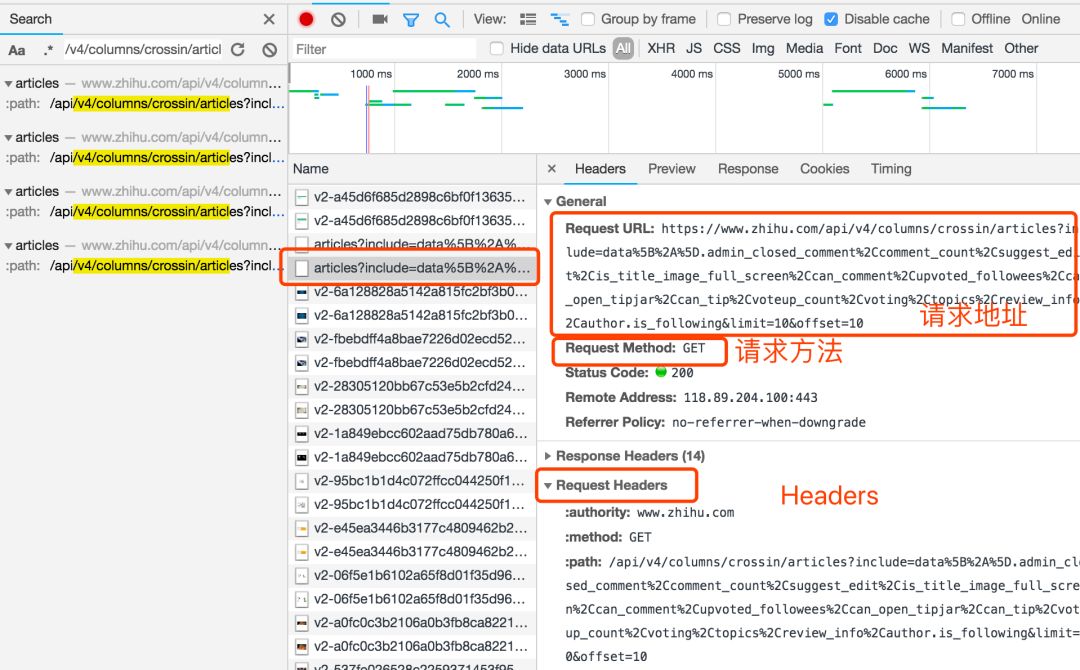

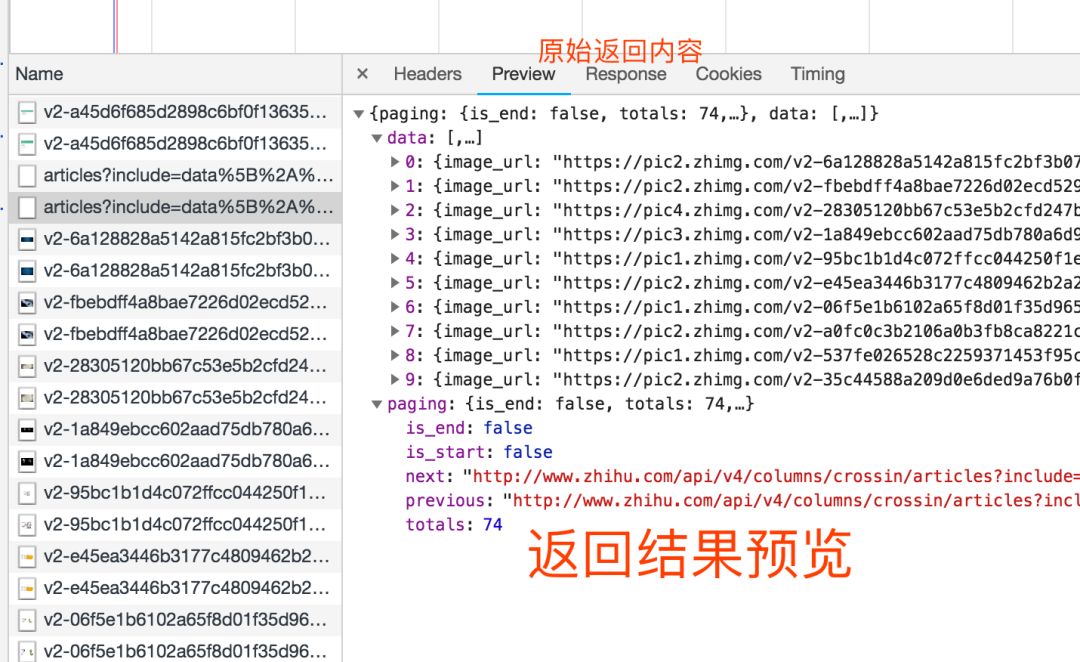
找对请求,设对方法,传对参数以及 Headers 信息,大部分的网站上的信息都可以搞定了。
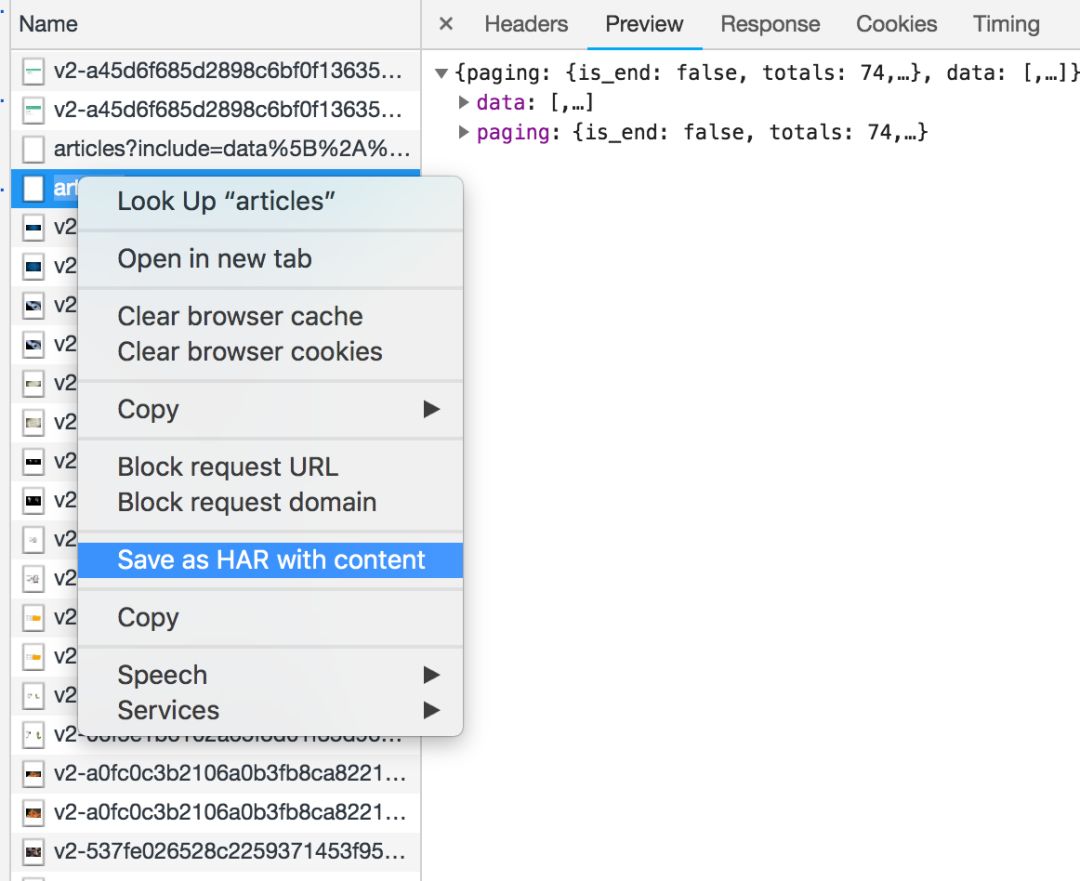
Network 还有个功能:右键点击列表,选择“Save as HAR with content”,保存到文件。这个文件包含了列表中所有请求的各项参数及返回值信息,以便你查找分析。(实际操作中,我发现经常有直接搜索无效的情况,只能保存到文件后搜索)
除了 Elements 和 Network,开发者工具中还有一些功能,比如:
Sources,查看资源列表和调试 JS。
Console,显示页面的报错和输出,并且可以执行 JS 代码。很多网站会在这里放上招聘的彩蛋(自己多找些知名网站试试)。

但这些功能和爬虫关系不大。如果你开发网站和优化网站速度,就需要和其他功能打交道。这里就不多说了。
总结一下,其实你就记住这几点:
-
“查看源代码”里能看到的数据,可以直接通过程序请求当前 URL 获取。
-
Elements 里的 HTML 代码不等于请求返回值,只能作为辅助。
-
在 Network 里用内容关键字搜索,或保存成 HAR 文件后搜索,找到包含数据的实际请求
-
查看请求的具体信息,包括方法、headers、参数,复制到程序里使用。
理解了这几步,大部分网上的数据都可以拿到,说“解决一半的问题”可不是标题党。
当然咯,说起来轻松几点,想熟练掌握,还是有很多细节要考虑,需要不断练习。但带着这几点再去看各种爬虫案例,思路会更清晰。
如果你想要针对爬虫更详细的讲解和指导,我们的“爬虫实战”课程了解一下,也有面向零基础的入门课程。
课程详情公众号里回复 码上行动
如需了解视频课程及答疑群等更多服务,请号内回复 码上行动
代码相关问题可以在论坛上发帖提问 bbs.crossincode.com
推荐阅读:
世界杯 | 高考 | 我用Python | 知乎 | 排序 | 朋友圈 | 电影票 | 百万关注 | 技术宅 | 火车票 | 单词表 | 押韵工具 | 新手建议 | 就业
欢迎加入
Crossin的编程教室
crossincode.com

请把我们分享给身边爱学习的小伙伴 :)
☟点击文末“阅读原文”,查看更多学习资源

文章评论