菜鸟学Python粉丝的第25篇投稿
阅读本文大概需要5分钟
说起武侠小说,不得不提中国武侠小说三大宗师——金庸、梁羽生、古龙,从上世纪七八十年代开始,大量的武侠经典出现在荧幕之中。三位大师的文字作品几乎都读过,在学习Python和数据分析后又发现了很多好玩的东西,今天就用数据分析来探索一下武侠小说。
要点:
- 谁是主角(金庸)
- 用词习惯(梁羽生)
一
谁是金庸小说的主角
天龙八部是一部多主角小说,萧峰、虚竹、段誉三兄弟各有际遇,曾经还因谁才是第一主角的问题引发过一阵争论。
现在我们已经懂得用数据思维来考虑问题,看看怎样对中文小说进行数据分析吧。出场率是评价一个小说人物的重要指标,我们就先来对《天龙八部》中人物的出场情况进行一下统计分析吧。
1.分词
中文分词是中文信息处理的基础,但是由于汉语的博大精深,中文分词的难度比英文要高出一大截,好在python有很多用于中文分词的库,jieba就是其中受欢迎程度比较高的一款,下面我们就来体会一下它的妙用。
因为文件太大,每次只读取固定长度的字符串

-
jieba用起来非常简单,短短几行代码就完成了分词工作(下图),可是...仔细一看发现哪里不对了
-
“段誉”作为一个姓名没有被单独分出来,而是和其他一些动词连在一起,另外也有一些角色名字被拆分成了两个甚至更多的单词,例如“神仙姊姊”被分成了“神仙”和“姊姊”两个词。
-
不过这也难怪,中文的灵活性太强,一个词往往有多层含义和多种用法,看来直接使用jieba分词还是会有不小的误差,我们得想办法来解决这个问题,不然会对分析结果造成干扰。

2.优化
jieba本身带有词库,而且具备很强大新词识别的功能,但是为了获得更高的准确率我们必须载入自定义词库。
因为这次的目的是对人物姓名进行分析,我们先从网上找一份热心网友整理的《天龙八部》人物大全,然后参照“jieba/dict.txt”的格式(一个词占一行,每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒)做成词典文件my_dict.txt。

使用 jieba.load_userdict()函数加载到程序中。如果在程序运行过程中发现其他问题,还可以使用add_word()、suggest_freq()等函数对词典和词频进行动态调整。
-
用load_userdict导入自定义字典,file_name 为文件类对象或自定义词典的路径
-
add_word()可在程序中动态增加词典
-
del_word()可在程序中动态删减词典
-
suggest_freq()可调节单个词语的词频,使其能(或不能)被分出来
现在我们已经成功解决了人名被意外分割的问题,而对于“段誉听”、“段誉见”这类包含姓名但分割不彻底的单词,我们可以使用suggest_freq函数调整词频进行强制分割
不过我感觉这样做毕竟麻烦,还是决定用正则表达式的方法把我们需要的人名单独取出来,同时将我们不需要的信息(不包含人名的单词)过滤掉。
3.制图
经过上面两步操作获得了一份仅包含《天龙八部》人名的文本,我们可以很轻易地将它读取并转换为list格式,
现在是不是有一种“我为刀俎,它为鱼肉”的感觉了。经过简单的数据处理,我们得到了每个人物的名字在小说中出现的频次,由于萧峰和乔峰是同一个人,为了方便统计将两个名字的出场次合并。
然后取出场率排名前30位的角色数据,用图表的形式展示出来。
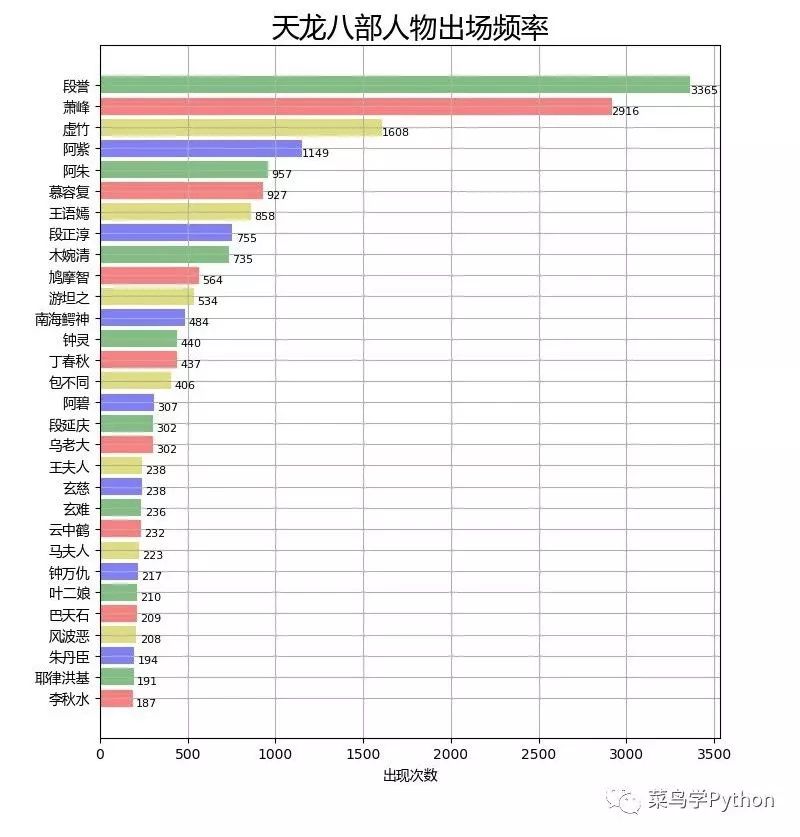
虽然在很多人心中萧峰的形象更适合本书主角,但从分析结果来看,“段誉”这个名字在小说中的出场频率是最高的。
萧峰(乔峰)紧随其后,难怪有人为谁是第一主角的事发起过争论。不过人物的重要性也不能只看戏份多少,像慕容博,萧远山,玄慈,段正淳这些人的出场率虽然不是特别高。
但正是这几个人上一代的宿命恩怨,引发了萧峰虚竹段誉三兄弟的江湖故事,实实在在是另一条暗线的主角。
关于主角的问题我们就不展开讨论了,从图中还可以看到其他一些角色的出场频率,仔细琢磨一下还是蛮有意思的。
其实《天龙八部》的中心思想就是“求不得”:
-
段誉不想学武功却练成了绝世神通
-
一心追求王语嫣最终美人对慕容复不离不弃
-
萧峰立志保卫大宋没想到自己居然是契丹人
-
决定与阿朱塞外牧马,然而造化弄人,心爱的人却死在自己手上
世间种种往往难以掌控,所以我们平时阅读、学习的过程中也不必过于心浮气躁、急功近利,还是要平心静气、踏实苦练,即使目标无法完全实现也可能遇到“有心栽花花不开、无心插柳柳成荫”的境遇。
二
小说里的用词习惯
每个人写作都会有自己的风格,而写作风格很大程度上可以在用词习惯上体现出来,刚才我们分析了金老的作品, 这次我们来看下被誉为新派武侠小说开山祖师梁羽生的两部部代表作品——《萍踪侠影录》和《云海玉弓缘》。
1.取词
既然是中文语言分析那第一步当然还是分词了,考虑到“说”、“走”、“开始”、“平常”等简单词语使用频率通常很高且难以体现写作风格。
这里我们仅提取词长度不小于4的成语、俗语和短语进行分析。同时,考虑到某些人名(例如:上官婉儿、澹台灭明)等专有名词会对分析结果造成干扰,在分词取词的时候可以一并过滤掉,最终得到这样一份词语文件:

2.云图
对用词习惯的分析更倾向于定性分析,我们这里使用词云图来作展示,首先绘制《萍踪侠影录》的词云图。

我们可以看到在这篇小说中“微微一笑”、“哈哈大笑”、“大吃一惊”、“非同小可”等词语使用频率非常高,再来看另一部作品《女帝奇英传》,词云图如下:

我们很容易就发现,这部小说中使用频率最高的还是“微微一笑”、“哈哈大笑”、“大吃一惊”、“非同小可”这几个词, 继续查看其他一些使用频率较高的词也会发现类似的规律。
看来梁老先生写作的用词习惯还是有迹可循的,有兴趣的朋友也可以拿其他大师的文学作品或者网络小说来进行分析,说不定会发现很有趣的规律哈。

中文分词其实是一个非常有意思的事情,特别是对这些武侠小说的探索!我自己也是一个武侠迷,超级喜欢金庸的小说。飞雪连天射白鹿 笑书神侠倚碧鸳,每一本书都是非常经典。除了上面两个维度,我们还有一个人物关系的分析文章,正在创作中,大家敬请期待。

近期热门:

文章评论