
大数据文摘作品
翻译:大力、白丁、阮雪妮、Lisa、彭湘伟、Shan LIU、钱天培
物理和机器学习,这两个听起来不相关的领域,居然有着千丝万缕的联系!
文摘菌第一次听说时也吓了一跳。
而就真有这样一个神奇的模型,将物理和机器学习紧密联系到了一起——它就是伊辛模型。
伊辛模型——一个描述物质磁性的简单模型——会帮助阐释两个领域之间的广泛联系。
今天,文摘菌会先从简单物理直觉谈谈这个模型,然后导出物理学中著名的变分原理,从而严格推出这个模型。
然后我们就会发现,正是这个变分原理打开了机器学习的窗口。我们将玻尔兹曼分布归为指数组,使一一对应透明化,并且通过变分原理来证明近似后验推断与大量的数据之间的关系。
如果你有物理学基础的话,我希望看了这篇文章后会对机器学习有更好的认知,并且可以读懂相关领域的论文。如果你专攻机器学习,我希望你看了这篇文章之后可以看得懂统计物理学中平均场论和伊辛模型的论文。
物理学中的伊辛模型
现在我们来思考一个自旋向上或者向下的晶格:
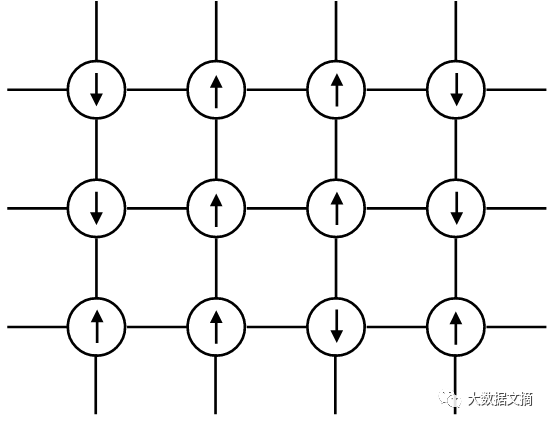
什么样的特性会促使这个系统变成一个可靠的磁性模型呢?
想想你玩磁铁的情景——如果你把两块磁铁放的很近,它们会彼此拉的更近。如果它们是同性的磁极则会相斥。如果它们离的很远,则完全不会发生这种吸引的情况。
这意味着在我们的模型里,邻近的自旋会互相影响:如果围绕s_i点的自旋都是向上的,那它也会是向上的。
我们参照位置i处的自旋为s_i。自旋只能处于两种状态中的一种:向上(s_i=+1)或向下(s_i=-1)。
我们引入交互作用参数J,用物理学的直觉来推论出自旋会相互吸引(它们想指向相同的方向)或相互排斥(它们要指向相反的方向)。
这个参数描述了自旋i和自旋j之间的交互强度。
如果两个相邻自旋指向相同的方向,我们用J来表示它们交互的总能量;如果指向相反的方向,则用J来表示。
然后我们就可以得到系统的能量方程,或者叫哈密顿量:
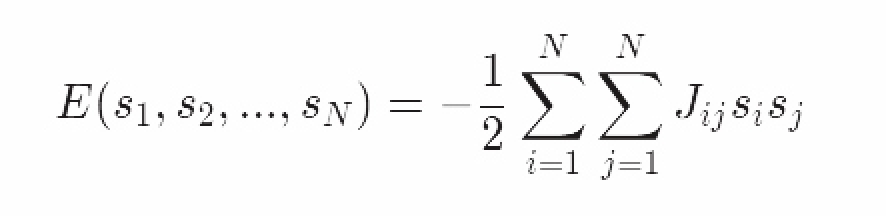
如果自旋i和自旋j相邻,J_ij=J;反之J_ij=0。因子1/2是考虑到i和j求和时候的重复计算。注意系统的自旋是有限多的(N个自旋)。
自旋组态或者系统的状态是所有自旋的特定值的组合。集合{s_1=+1,s_2=+1,s_3=−1,...,s_N=+1}是组态的一个例子。
热力学第二定律告诉我们在固定温度和熵的情况下,系统会寻求最小化其能量的组态方法。这让我们可以推理出交互作用的情况。
如果交互作用强度J为零,自旋之间没有交互联系,所有组态的系统能量也为零(能量小到可以忽略不计)。但如果强度J为正,自旋会按照某种规则排列起来使系统的能量E(s_1,s_2,...,s_N)最小。由于能量方程中求和前面的负号,这便与最小化一致。
然后引入磁场H。假定自旋的晶格在磁场中,比如地壳周围的磁场。磁场对每个自旋单独作用,每个自旋都会试图与磁场方向保持一致。我们可以加入每个自旋的作用的求和项来表示系统在磁场中的能量方程:
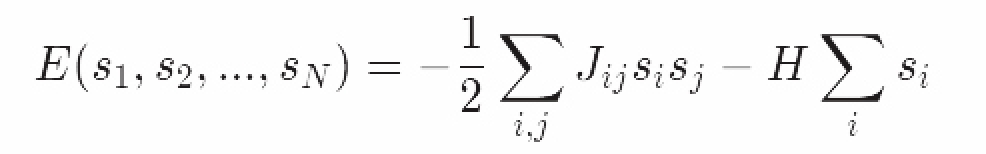
我们可以通过观察磁场强度H变大或变小(增强或减弱)会发生什么来推导出H的大小。如果H变大,自旋之间的交互作用减弱,磁场项会起主导作用,自旋就会按照磁场分布排列以使系统能量最小。但是如果磁场很小就很难推导出来了。
现在我们明确了伊辛模型的定义和它的性质,我们来思考一下我们的目标。关于伊辛模型我们可以解决什么问题?例如,如果我们观察系统,它会处于什么状态?最可能的自旋组态是怎么样的?平均磁化强度是怎么样的?
玻尔兹曼分布
我们可以把目标设定的更清晰一些数学更简明一些吗?那么我们需要定义一个自旋组态的分布。很显然的我们可以得出系统处于平衡态的概率。
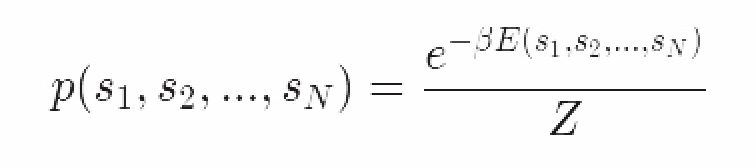
这便是玻尔兹曼分布。对于一个特定的组态,分子叫做玻尔兹曼因子。这个因子给一个特定的系统和其能量状态提供了可高可低的权重。
我们想要知道,给定一个特定的自旋组态,系统处于这个状态的概率的玻尔兹曼分布。
譬如,我们的组态的第一批自旋是向上、向上、向下,等等。我们将这个情况代入到公式里面得到P(s_1=+1,s_2=+1,s_3=−1,...,s_N=+1)=0.7321这意味着这种状态发生的可能性很大。
这个分布与直觉相符:低能量的比高能量的状态更可能出现。例如,在J=+1的情况下,自旋会开始排列,其中最可能出现的排列状态是所有的自旋指向相同的方向。为什么呢?因为这符合最小化能量的方程,其中的玻尔兹曼因子有最大的权重。
参数β与温度的倒数成正比,β=1/T*k_B并且用来方便的标记。(准确的说,这包括了使概率密度无量纲化的常数k_B)温度控制着粒子间的交互作用的强度进而影响整个模型。如果T→∞,温度很高,温度的倒数就很低,β≪1,所以交互强度J就不重要。但是在低温状态下,J除以一个较小的数就很大,因此交互强度够大会显著影响系统状态。
配分函数
分母Z是最重要的。它确保了分布的积分为1,由此这是一个合理的概率分布。我们需要这个正则化来计算系统的性质。计算平均值和其他值只能借助一个概率质量函数。Z被称为“配分函数”或者“正则常数”,它是每个状态下玻尔兹曼因子的和。
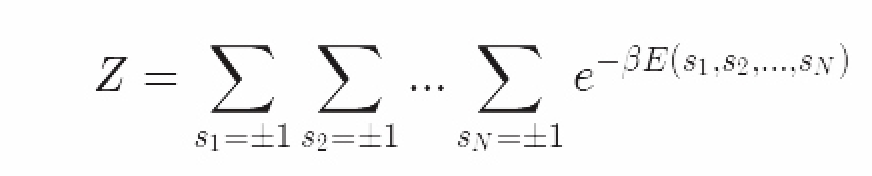
为了阐述为什么我们不能求出分布的精确解,我将这个和明确地写出来:我们需要将所有可能的组态求和。每个自旋都有两种状态,又有N个自旋。这意味着求和的阶数会有2^N。即使对一个只有一百个自旋的微小系统来说,这个计算量已经比整个宇宙的原子数量还要多了,我们没有可能算得出来。
利用玻尔兹曼分布来计算系统特性
我们得到的概率分布反映了系统可能处于的状态,但是被卡在了配分函数这个磨人的小妖精上。暂时假定我们能够通过无穷运算得出玻尔兹曼分布的配分函数,那么从系统的波尔茨曼分布中我们能了解到哪些有趣的情况呢?
该分布使我们能够把系统作为一个整体,利用期望值(例如计算可观测量)来计算其特性。举个例子,磁化强度m是所有自旋粒子的磁化强度均值。
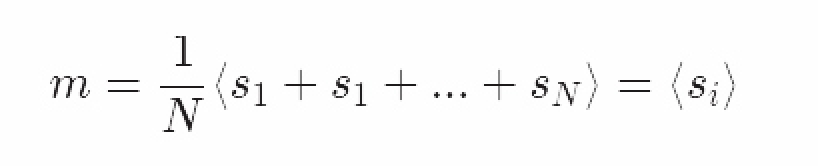
我们为什么要关注这个磁化强度呢?因为它能够反应系统的宏观状态,而非某个特定的微观状态。我们丢失了特异性,因为我们对第一个自旋粒子s_1一无所知,但是透过所有其余自旋粒子可能出现的状态,我们掌握了其运动状态。
相同的自旋方向意味着系统处于有序状态,磁性为阴极或阳极;而相反的自旋方向则说明系统处于无序状态,平均磁化强度为零。
以上都是系统在全球范围内不同的相位,与温度息息相关。如果温度T无限升高,其倒数β则趋近于零度,系统的所有状态就会像波尔茨曼分布描述的那样处于等可能状态,此时系统可以在有序相和无序相间来回切换。
这种相变以及温度对其的影响方式在衡量伊辛模型与真实世界物质匹配程度高低中发挥着重要作用。
别忘了我们求不出配分函数Z的值。想要回答磁化强度值等此类有趣的问题,我们似乎陷入了一个无解的境地。然而谢天谢地,通过独立分析每个自旋粒子并估出近似值,这个问题就被进一步简化了。
物理学中的平均场理论
鉴于我们无法通过计算得出配分函数计算所需的总值,我们就改换山头转向平均场理论吧。
这个“约莫”的技巧使我们依然有能力回答平均磁化强度等关于系统的一系列问题。我们将继续研究磁化强度m与温度的依赖性。
从单个自旋粒子入手更容易把这个技巧说明白:
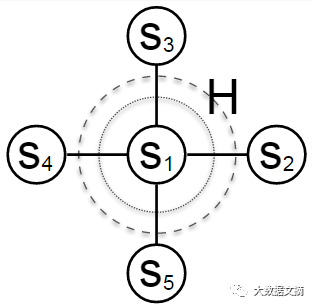
伊辛模型在H磁场中的第一个自旋粒子。磁场用虚线表示。其附近的粒子通过互动形成了有效磁场,表示为连接粒子的线。
这个单一粒子对系统全部能量的贡献一言以蔽之,就是能量中的对应项。
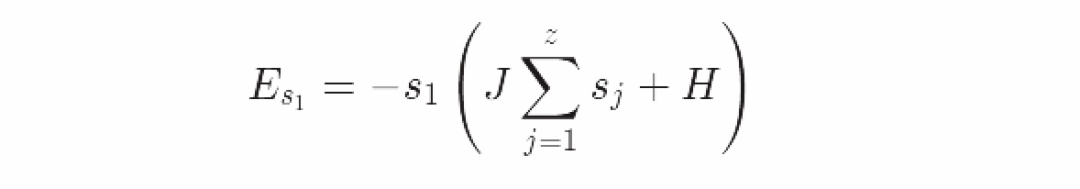
总值大于z距离最近的粒子。在我们正在探讨的二维点阵中,z=4。根据单一粒子围绕平均值上下波动,我们能够为这个自旋粒子重写能量函数如下:
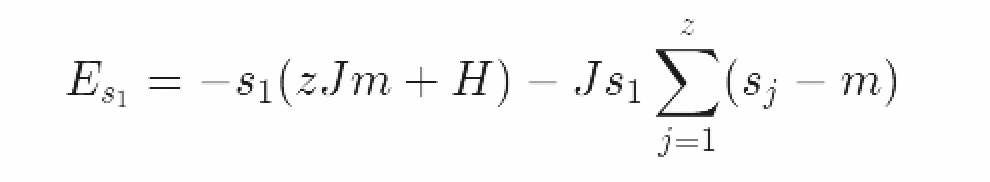
接下来的这一步至关重要:我们将忽略相邻自旋粒子均值附近的波动。换句话说,我们假设项(s_j−m)→0,这样一来s_0的所有邻居都等于其平均值,s_j=m
这在什么时候会成立呢?
当均值附近波动很小时,比如低温“有序”相。该假设大大简化了该自旋粒子的哈密尔顿量。
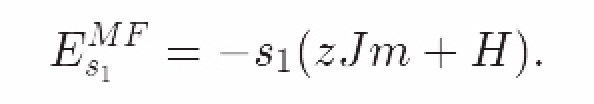
这是单一自旋粒子的平均场能量函数,相当于一个处于有效磁场中的非相互作用自旋粒子H^{eff}=zJm+H。
我们为什么说这个自旋粒子是非相互作用的呢?该自旋粒子的能量方程仅依赖于其状态,s_1,与任何其他自旋粒子的状态无关。通过引入相邻自旋粒子我们得到了平均磁场强度,进而估算出了交互效果,也就是平均场。
在这个平均场大的模型中,每个自旋粒子都受到整个系统所在的磁场H的影响,以及其相邻自旋粒子zJm的“有效”平均磁场的影响。
我们用下面的公式来进行说明
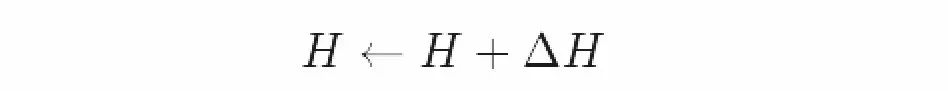
公式中ΔH=zJm是每个自旋粒子相邻粒子的平均磁场(平均场)。
忽略了每个自旋粒子的波动之后,问题被进一步简化。现在位于均匀磁场H中的是N独立自旋粒子,而非N相互作用自旋粒子;并通过ΔH这个小小的矫正值来体现相互作用的影响。
我们将平均场模型的能量函数写作:
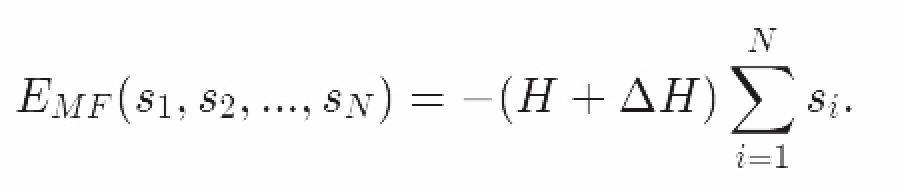
可见函数中不再出现相互作用项了(s_is_j这一项未出现在能量函数中)
换句话说,我们既可以单独观察每个自旋粒子,也能够将所有结果合理汇总,得到整个系统的模型。
我们从根本上改变了问题的本质。
我们现在要做的就只是计算单一自旋粒子的配分函数,而非整个系统的配分函数Z了。
我们能够用解析解4直接作出回答:
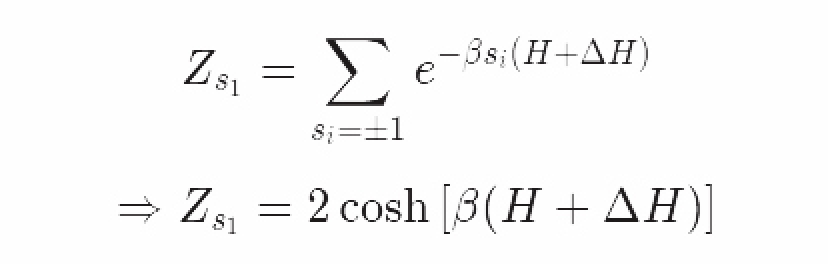
那么由N自旋粒子推导出的整个平均场模型的配分函数就是
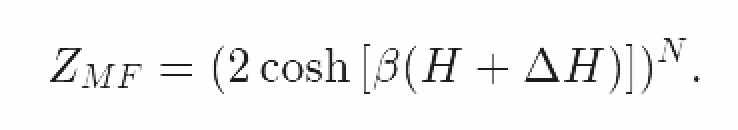
配分函数在手,波尔茨曼分布我有;回答诸如磁化强度等与系统有关的问题也不在话下。
我们利用自旋粒子分布的期望值推导除了磁化强度。最后一步需要该值来计算任意自旋粒子i的情况,其平均磁化强度应等于系统整体的平均磁化强度:
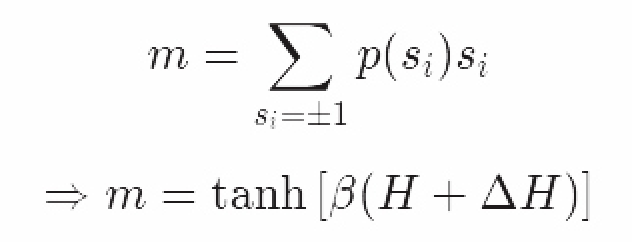
由此我们得到了一个简明易懂的磁化强度等式
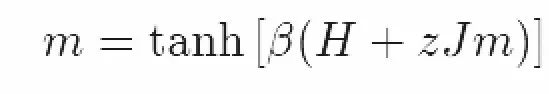
这里我们用到的平均场参数为ΔH=zJm。
这个针对磁化强度m的公式是一个温度函数。虽然它并没有封闭解,但是我们能够调整等式两端,查找交集部分来得到隐含解(拖动滑块来设定新温度):
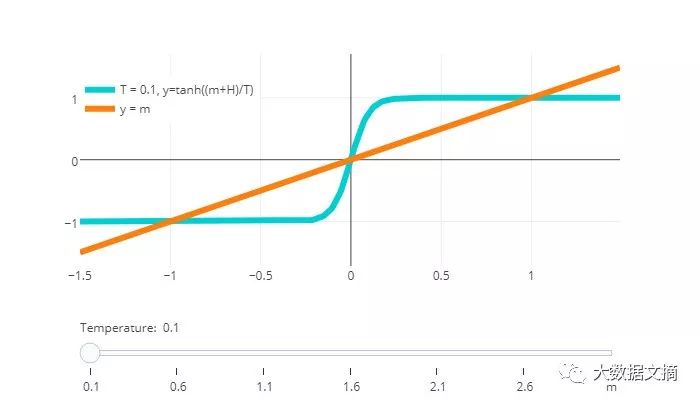
首先,我们来考虑一下没有外磁场的情况,即H=0。
高温条件下等式只有唯一解:m=0。这与我们的直觉是一致的-如果考虑整个系统的能量情况,温度倒数β趋近于零,所有自旋粒子的所有状态都处于等可能水平,其平均值为零。
低温条件下有3个解:m=0和m=±∣m∣。增加的±解的出现条件是tanh函数在原点的坡度大于以下:
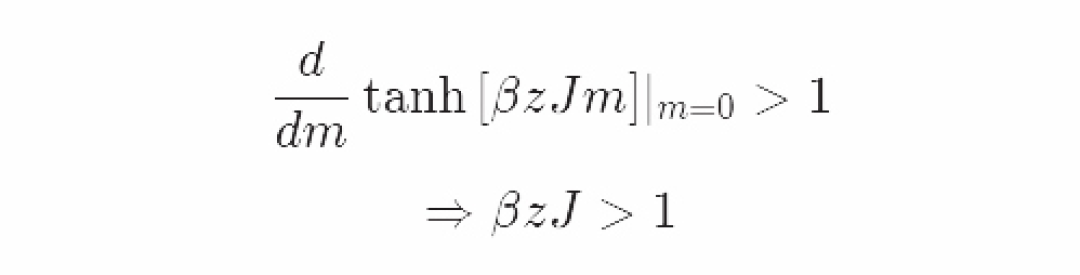
相变“临界温度”的出现条件是βzJ=(1/T*k_B)*(zJ)=1,或(k_B)*(T_c )= zJ。
由此我们得到了一个可检验的预测:我们能够取一个磁性物体,然后测量其相变温度。
我们的目标达成了吗?
我们最初的目标是从磁化强度等全球特质的角度,掌握该模型在不同温度下的表现。
通过研究单一自旋粒子和估算其他自旋粒子作为有效磁场的影响,我们显著降低了问题的复杂程度。以此为基础,我们能够进一步研究相变。然而,我们的论证总感觉有些底气不足,所以接下来我们继续深入研究,打牢地基,证明我们的直觉。
推导变分自由能原理:Gibbs-Bogoliubov-Feynman不等式
我们是否能知道,当我们做出“忽略自旋粒子在其均值附近的波动”的假设时,我们做出了什么样的权衡取舍呢?更具体地说,我们应该如何评价我们从平均场理论中所得到的结论呢?
我们可以通过直接研究这个棘手的配分函数来重新得到在之前部分中出现的平均场的结果。我们可以试着用一个简单一点的函数来估计这个配分函数。
让我们一起回顾一下,这个系统的配分函数Z是
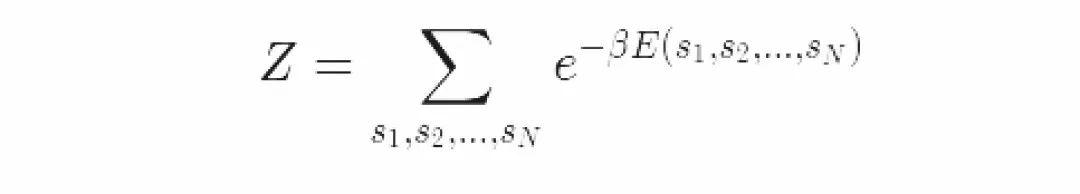
和之前一样,系统的能量是
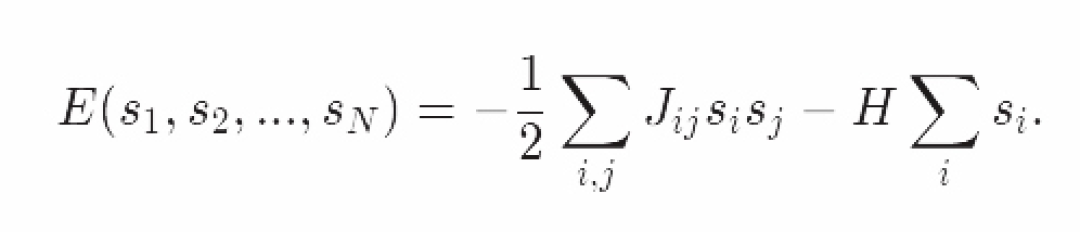
计算这个配分函数的难度来源于带有s_is_j的交叉项。我们发现如果没有这一项的话,我们就能把问题简化为处理一个由独立的自旋粒子组成的系统了。
为了导出变分原理,我们假设一个有如下形式的能量函数
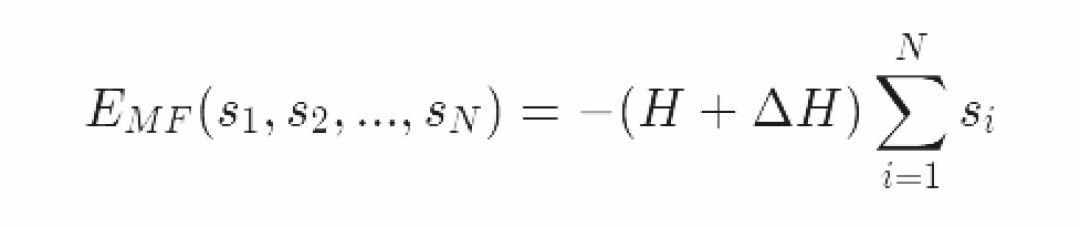
在之前的推导中我们已经通过我们的物理直觉得到了平均场参数为ΔH=zJm。
现在就有一个问题:这是最优的有效磁场吗?我们可以认为ΔH是通过调整能得到原始系统最优解的平均场模型的参数。
这被称为“微扰法”:我们对系统的磁场进行微扰,并试着寻找能够得到原始系统一个好的近似的最优扰动。
一个好的近似需要什么?我们的困难在于计算配分函数。因此我们想要用我们的平均场系统的变分函数Z_{MF}来近似估计原始系统的配分函数。但愿Z_{MF}是容易计算的,不需要进行和宇宙中原子个数相同量级的求和运算。
首先让我们看看能否用我们的近似来表达原始系统Z的配分函数。通过计算能量的波动,我们可以计算平均场系统的能量偏离参考系的程度。
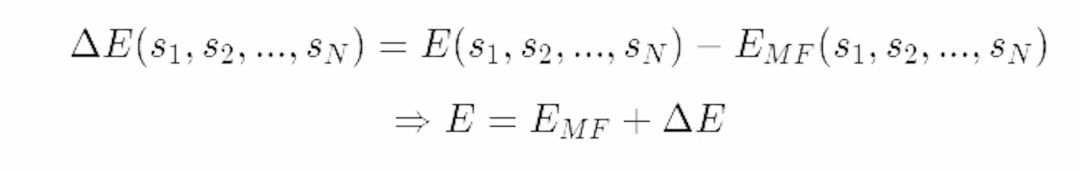
让我们把原来的配分函数重新表达为:
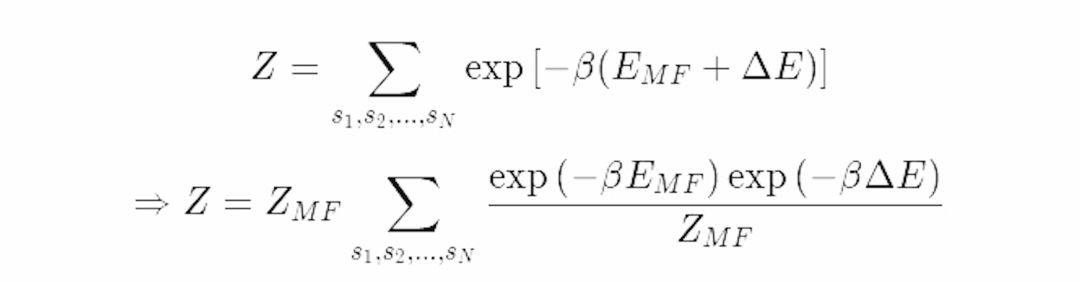
在下一步中,我们需要定义函数A关于平均场波兹曼分布的期望。
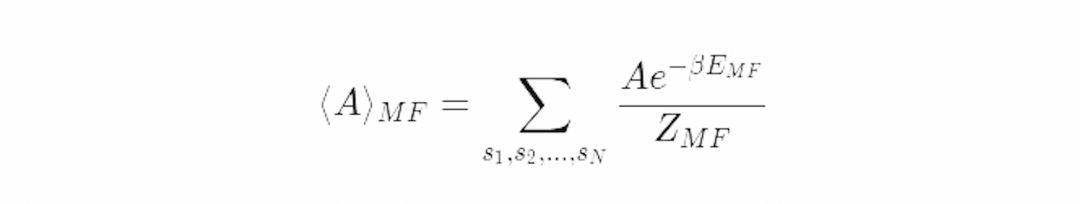
这就意味着我们可以把原系统的配分函数表达为平均场配分函数的函数。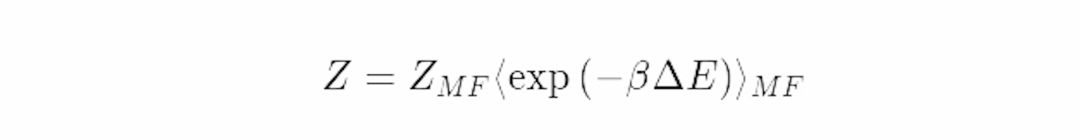
这就是原始系统的配分函数的一个因式分解。这是以偏离参考系的能量波动的期望波兹曼因子为权重的平均场配分函数。
然而,对这个复杂的指数函数积分是很困难的,即使是对平均场系统来说也不容易。我们将利用一个经典的物理技巧来简化这一过程——将它泰勒展开。
假定能量波动很小;ΔE≪1。于是我们便可以对这个指数进行泰勒展开: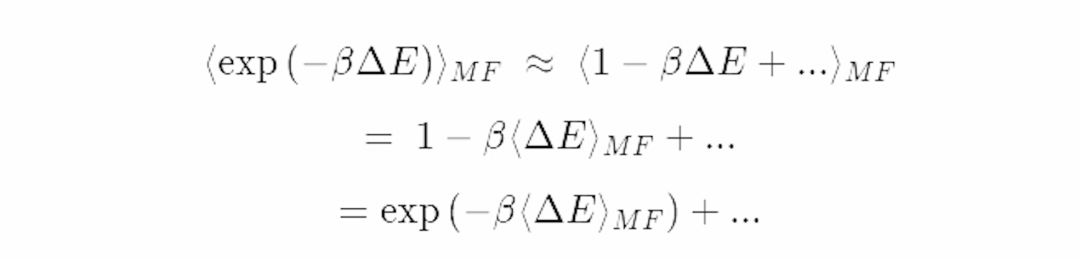
在上式中我们省略了波动ΔE的二次项。于是我们得到了对原始系统配分函数使用一阶微扰法的结果: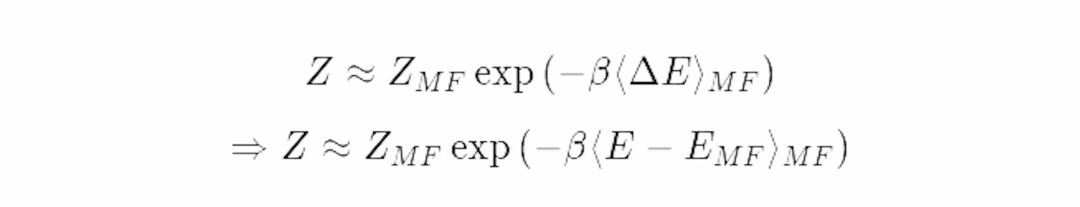
这个估计有多好呢?让我们引入一个简单的恒不等式:e^x≥(x+1)。
把这个式子用到配分函数的准确因式分解的期望中,取f=−β*ΔE: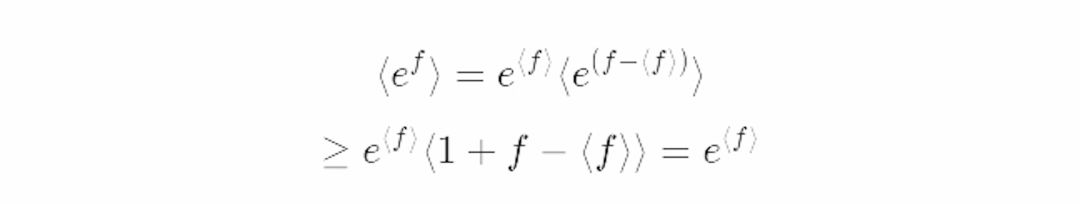
现在我们得到了配分函数的一个下界: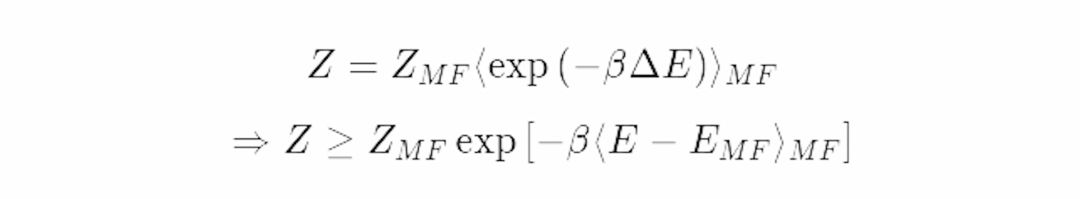
这个不等式就是Gibbs-Bogoliubov-Feynman 不等式。这个式子告诉我们,通过平均场近似,我们可以得到原配分函数的一个下界。
利用Gibbs-Bogoliubov-Feynman不等式对伊辛模型进行变分处理
让我们来应用这一理论:在伊辛模型中我们是否能得到同样的磁化强度呢?
在平均场伊辛模型中,我们独立地处理每个自旋粒子,因此系统的能量函数就分解为独立的部分:
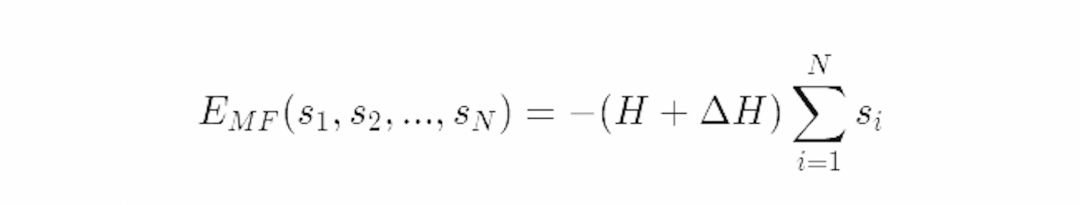
这里ΔH是有效磁场强度。这是配分函数下界取最大值时的参数。
把它代入从Gibbs-Bogoliubov-Feynman不等式中得到的配分函数的下界中,并求导来使下界取到极大值:
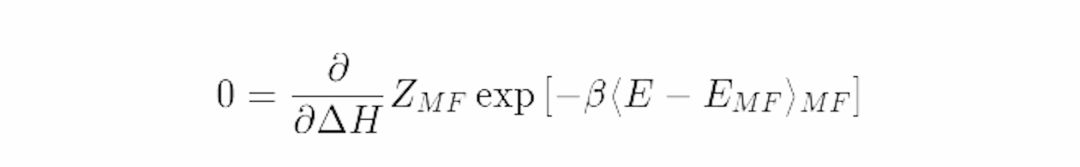
首先我们得求出期望:
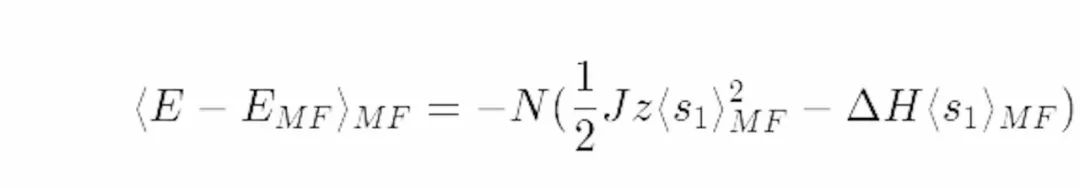
在这里我们用到了平均场的假设:自旋粒子是各自独立的。因而有:
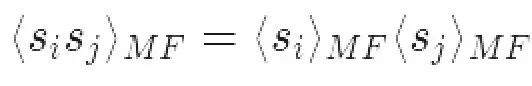
我们还假定,对于一个足够大的系统,模型边缘上的自旋粒子(边界条件)可以被忽略。因此所有的自旋粒子都有相同的平均磁化强度:
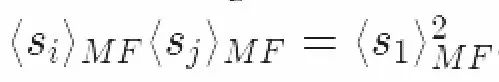
把它代入配分函数的下界并求导,有
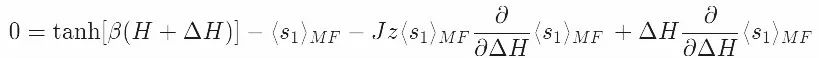
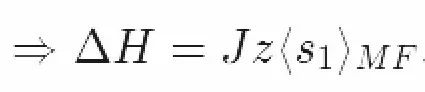
这里用到了之前的结论:
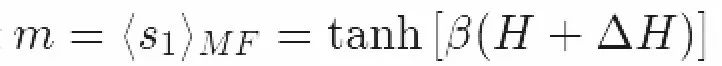
这证实了我们之前的推理:最优的平均场参数是ΔH=Jzm。在这一过程中共有三个步骤。我们首先定义了我们关心的模型,然后写下了它的平均场近似,最后我们对配分函数的下界求极大值。
以机器学习视角对Ising模型的展望
现在,让我们以机器学习的语言来构建我们刚刚的思考过程。更具体的说,让我们以随机建模的思路来思考这个问题。
在机器学习中,我们需要一些定义来展现变分原理与变分推断之间的等价关系。
Ising模型是一种无向图模型,或者说马尔科夫随机场。我们可以用图表来表示模型里的条件依赖关系;图中的节点为随机变量。这些随机变量是伊辛模型的自旋,如果两个节点会相互影响,就用一条边链接他们。由此我们可以对下图中随机变量的联合分布进行编码:
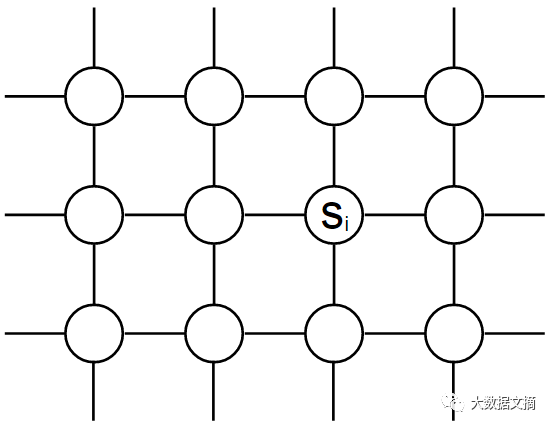
Ising模型的无向图模型表达。节点为随机变量,边表示他们分布的条件依赖关系。
将该图像模型联合分布参数化,就得到波尔兹曼分布。该图与物理自旋表现非常相似,再次强调,自旋代表随机变量。 我们同样可以将节点分布写成指数形式。指数族分布可以使我们推导出一个广泛类的数个模型。
指数族
指数族是一种将类似Ising模型的概率分布数据化的方式。这些分布族支持可以写成如下具体简单的数学公式
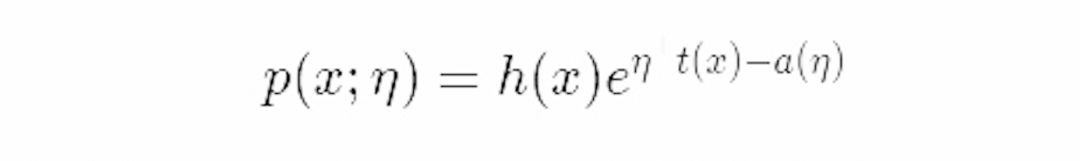
这里η是自然参数,h(x)是基础度量值,t(x)是充分统计量
a(η)是对数配分函数, 也叫对数正规化子。有很长一段时间内我对于指数族倍感困惑,最后是具体是具体的推导过程帮助了我理解。
例如,我们看到过伯努里分布的以下表达:
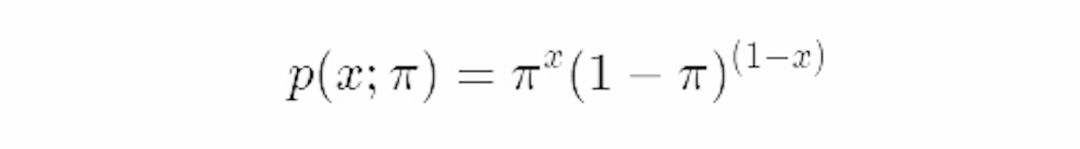
我们可以把他写成指数族的形式
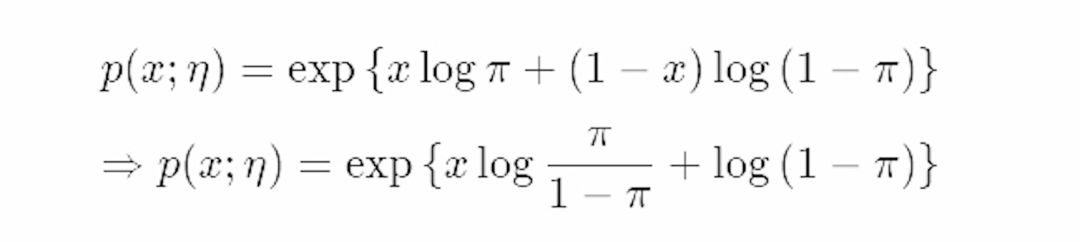
与以上公司相比,指数族展示了伯努利的自然参数,基础度量值,充分统计量,分别为η=log(π\1−π),t(x)=x,a(η)=−log(1−π)=log(1+e^η)和h(x)=1。
和物理学更多的联系:对数正规化子是配分函数的对数。这一点在伯努利的指数族中尤为明显:
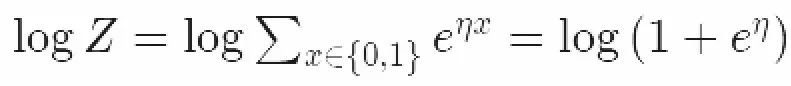
现在我们可以确定η类似于温度,拥有自旋x。我没找到了Ising模型的指数族形式!
Ising模型的指数族形式
让我们通过伯努利分布的指数族公式把Ising模型的能量公式与指数族形式联系起来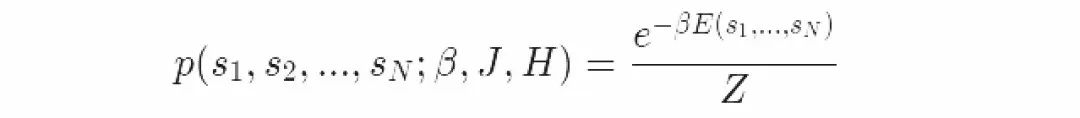
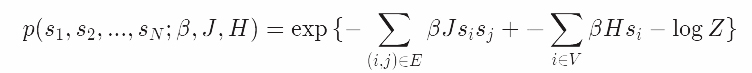
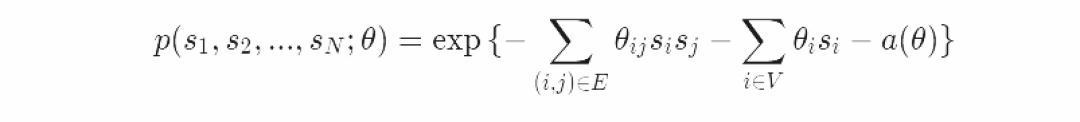
我们引入了一些新的注释到图像模型中:我们把一个节点分布除以一个图中在顶点V上的自然变量的集合,并与E中的边联合。
这就是Ising模型的指数族形式,一个关于θ的概率模型。为了使它和我们之前得到的形式一样。如果i和j共享一条边(比如他们相邻)设θ_ij=(1/2)*βJ,并设θ_i = H。
我们可以看到,Ising模型有两组模型参数。自旋与自旋的相互作用参数乘以温度 βJ的倒数,控制着图中每条边的影响。温度倒数乘以磁场影响着每个自旋。我们也可以得出结论:温度倒数是一个全局模型参数。对一个已定的互动场或磁场,我们可以通过改变温度来索引一个具体的模型。
这点既很微妙有很重要。我们的在随机变量(N自旋)上的联合分布由模型参数索引。通过改变倒温度参数β,我们可以选择一个具体的模型(在对应温度下的伊辛模型)。对于一个特定的自旋与自旋相互作用参数j也是亦然。
关于模型我们能问什么问题?
计算磁化强度m=(1/N)*⟨s_1+...+s_N⟩=⟨s_i⟩意味着计算E_p(si)的期望。从概率的角度来说,这意味着计算node i的边际期望。
但计算边际分布是很棘手的,基于我们之前讨论过的原因:它需要边际化所有 j≠i的点
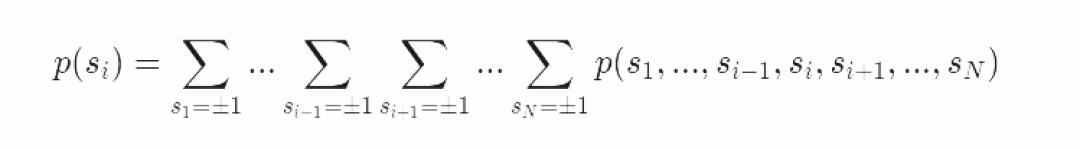
这种情况是不可行的:我们不仅需要为N点的联合分布计算标准化的定值,这需要2^N个项,而且我们需要边际化N−1个变量(另外的2^(N-1)个项)
当从物理角度考虑这个模型时,这等同于我们在配分函数里面看到的那样。
我们还可以继续依靠变分原理来回答有关边际分布的问题吗?
机器学习中的变分推论
如果我们可以计算所有随机变量的配置总和,我们就可以计算这个配分函数。但我们不能,因为这个总和以2^N级增长。
以物理学家的身份,我们的策略是估算配分函数。
从机器学习的角度,这个技术叫做变分推论。我们改变一些简单的东西来推论复杂的东西。
让我们来看看机器学习是怎样推导变分自由能,并且应用在估测配分函数上的。
我们有一个随机变量的概率模型pθ(s_1,...,s_N),然后我们想要寻找计算它的标准化常量或者配分函数。
让我们构建一个更简单的概率分布qλ(s_1,...,s_N), 以λ为参数,并且用它来估测我们的模型。
我们的估测怎么样呢?一个测量方法是看我们的估测和目标分布之间的Kullback-Leibler差异有多大。
这个qqq和ppp之间的差异,或者相对熵,计算了当使用q来估计p时的信息损失总量(以bits或者nats为单位)这给了一个调整我们估测的标准。我们调整λ参数直到最小化估测的Kullback-Leibler误差。
KL差异是由以下双竖线组成的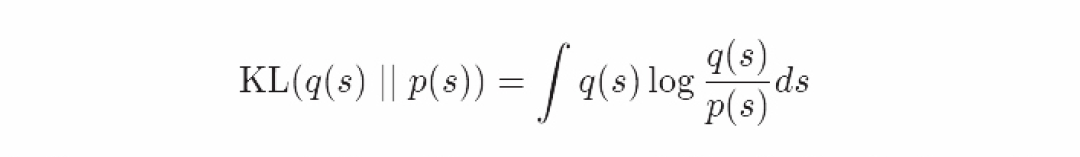
让我们假定我们正在处理一个指数家族的分布例如Ising模型。已知能量方程E(s_1, ..., s_N),我们让p在模型中呈Boltzmann分布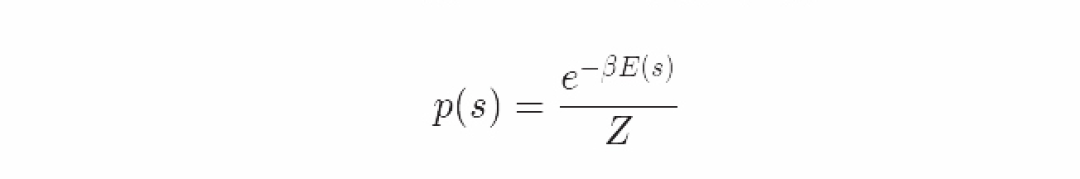
假设qqq的分布的能量方程是有λ参数的: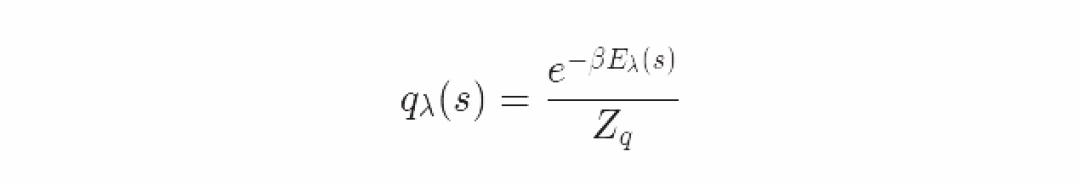
为了测量我们使用qqq代替ppp来估测所损失的信息,我们把他们代入Kullback-Leibler差异中: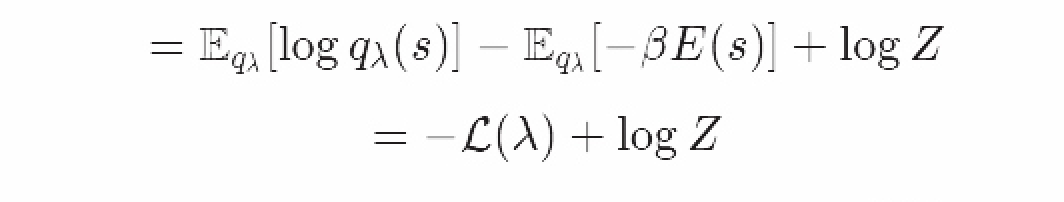
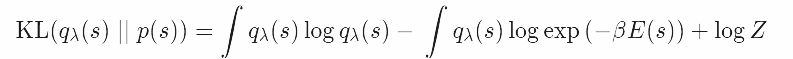
我们定义变量下限L(λ)如下: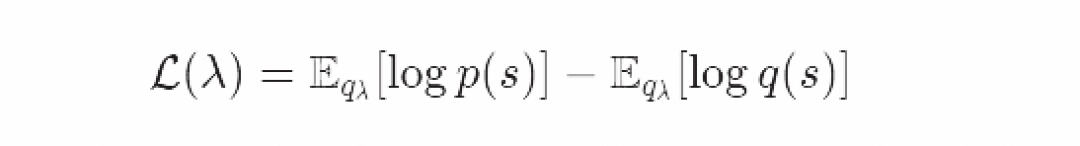
我们可以把变量下限移到方程的另一边来得到以下的等式: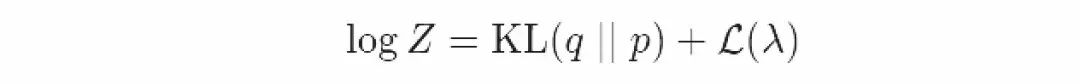
根据Jensen’s不等式,易得KL差异总是大于等于零。这意味着如果我们将L(λ)变大,KL差异一定变小(同时,我们的估测必须改善)。因此我们可以降低偏分方程的边界: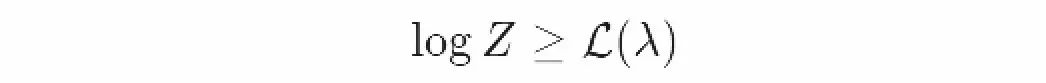
这意味着我们可以调整我们估测中的参数λ来提高下限值,并且得到一个对变分方程更好的估测!
注意到在变量下限的定义中,我们不用担心计算变分方程的费力的任务:它不需要取决于λ。
这是很棒的:我们已经构建了对于p概率模型中的q_λ的估测并且找到一个调整参数来让估测变得更好的方法。
有趣的部分是我们可以不用通过计算它棘手变分函数的方式来提高模型的估测。我们只需要估测它的能量方程E(s),这是更容易去计算的。
这是不是厉害得难以置信?我们是不是忽视了什么?我们已经失去了用绝对项去测量这个估测好坏的能力,为了估测,我们仍然需要去计算变分方程来计算KL差异。我们确实知道只要我们改变λ来提高下限值L(λ),我们的估测就越好,并且这对一系列问题的变形都足够了。
变分推断就是Gibbs-Bogoliubov-Feynman不等式
我们来看看变分推断是否和我们在物理中看到的Gibbs-Bogoliubov-Feynman不等式是一回事。该不等式如下:
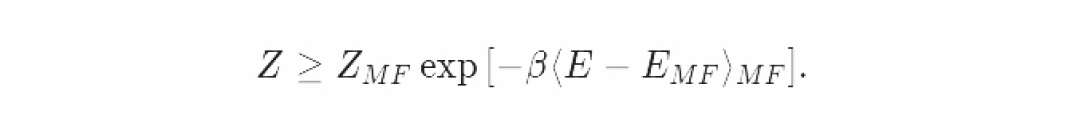
取对数后:
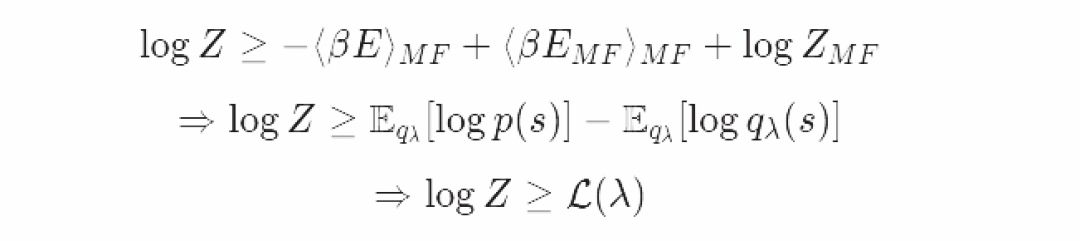
我们已经确认了变分族服从Mean-field Boltzmann分布
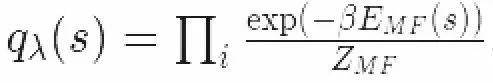
λ表示我们用于最大化下边界的变分参数。
这就表明了,变分推断在机器学习中,最大化了变分函数的下边界。这其实就是Gibbs-Bogoliubov-Feynman不等式。
近似后验推断中的evidence lower bound
在机器学习中,我们在意数据中存在的模式。这便引出了潜在变量这一概念。潜在变量是指未被观察到的,但实际上可以发现观测数据中存在的模式的变量。
例如,在线性回归中,我们可能假定人们年龄和他们收入之间存在线性关系。回归系数变捕捉到了我们想从大量数据对(年龄、收入)中发现的潜在模式。
我们把一个概率模型看作是潜在变量z和数据x构成的模型。潜在变量的后验分布(对于观测数据的条件概率)可以被写成p(z∣x)。
什么是后验呢?在年龄和收入相关关系的回归分析例子中,我们想得到回归系数基于观测数据的后验分布。我们选择系数的先验分布本身就是建模的一部分。先验分布的选取反应了我们希望观测到的统计关系。
后验分布由贝叶斯定理可以得到:
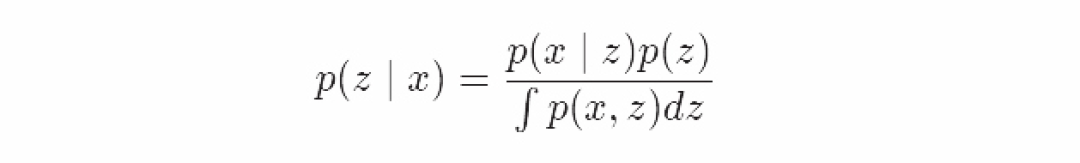
分母代表的数据的边际分布就是证据,p(x)=∫p(x,z)dz。这是关于潜在变量,数据和变分函数的标准化联合分布。这个变分函数含有一个由随机变量加和构成的结构。它就像我们之前两次看到的一样复杂。
我们是否可以在做后验推断时摒弃复杂的变分函数呢?
简化过程是类似的:虽然在变分函数中有一个复杂的加和,但是我们可以用之前开发的工具——变分推断,去近似它。 让我们写出变分函数中变分的下边界:
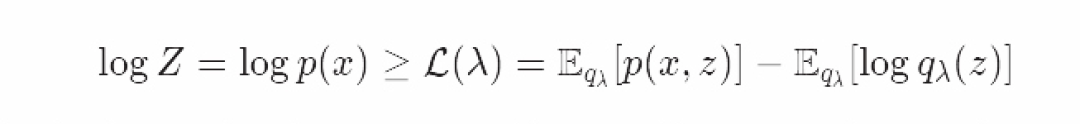
通过改变参数λ,我们可以得到一个近似的后验分布qλ(z)。它可以近似于我们想得到的,但又算不出来的后验分布,p(z∣x)。
如果我们用变分法去近似一个后验分布,我们的变分函数就是log{p(x)}。因此我们认为变分下界L(λ)就是Evidence Lower Bound or ELBO,并且可以通过最大化ELBO得到很好的近似后验分布。
过去20年中,这个技术被广泛应用于机器学习。它变得流行是因为复杂的变分函数在大型数据集中需要被分析。而变分的原理——最优化下边界,就是利用最优化的方法在大数据中计算贝叶斯推断。
这是一个令人兴奋的领域,因为随机优化的新技术可以让我们去探索物理和机器学习的新领域。
机器学习技术在物理中有用么?
在机器学习领域,大量用于近似变分函数的技术都可以在物理中见到。
例如,black box variational inference 和 automatic differentiation variational inference都是物理中的通用方法。它们为构建代表性的近似分布和高效的优化技术搭建了框架。
这就像在问熟悉变分法的物理学家,随机优化用在变分法中了么?这样有效么?
物理学中的工具对机器学习有用么?
是的!Gibbs-Bogoliubov-Feynman最初就是发展于物理领域。90年代,Michael Jordan在MIT的小组发现将其应用于机器学习的方式。
似乎有不同的方式来构建灵活的分布族以近似计算分布。Replica Trick,Renormalization Group Theory等其他的理论才刚刚从统计物理学中引入到机器学习中。
另一个从物理中引入工具的例子是Operator Variational Inference。在这项工作中,我们开发了一种构建算子的架构。这种算子用于描绘近似的效果。这个架构使我们可以很好地平衡近似精度和计算量。Langevin-Stein算子和Hamiltonian算子是等价的,他们最初都呈现于物理领域的论文中。
一个有趣的问题值得考虑:为什么KL会发散?物理学的解释是明确的。它对应于变分函数的一阶泰勒展开,并且有非均衡扰动分布的假设。(难道)有二阶泰勒展开对应于另一种发散么,并且能得到更精确的结果?
我最近学习了副本理论(Replica Theory)。Replica Trick是一种使用疯狂的公式,来精确计算系统中变分函数的技术。它引出一个问题:我们使用概率图模型时应该有什么假设?
我非常乐忠于看到更多的物理学工具迁移到数据科学和机器学习中去。
我们怎样才能转换地更快呢?我们怎样才能更有效率地传送机器学习和物理之间的技术呢?代码实例会有帮助么?
这篇博文的主旨在于以一个学科社区的语言(物理学)来匹配至另一个社区(机器学习)。同时这篇长综述通过举例,从机器学习的角度(黑盒变分推断,随机优化等)去思考统计物理的架构(with mean-field methods, replica theory, renormalization theory等)和当代变分推断,展现不同领域间是如何互补的。
术语解释
-
期望:角括弧⟨ ⋅ ⟩ 代表期望。在机器学习文献中,关于分布P的期望,被写作Ep[ ⋅ ]。例如⟨f(s)⟩表示旋转f(s)的函数的期望。这个期望是关于Bolrzman分布的:

-
物理学中的旋转,在统计和机器学习中成为随机变量
-
变分推断中的evidence lower bound是物理术语中的负自由能。
原文链接:
https://jaan.io/how-does-physics-connect-machine-learning/
【今日机器学习概念】
Have a Great Definition
精品课程推荐
数据科学实训营第5期
优秀助教推荐|土豆
现今纷纷扰扰的数据科学培训市场,是不是早已让你眼花缭乱,无处落足,还没有找到组织?不必慌张,土豆老司机拉住你的手,语重心长的要为你指条明道:究竟优质的数据科学教育培训是什么样的?
课程干货满满还不失风趣,讲师精力充沛还热爱分享,助教认真批改还热情反馈。
没错!数据科学实训营就是这样的明星课程!从基础的 Python 编程和Scrapy爬虫,到熟练运用 Numpy/Pandas/Matplotlib/Seaborn/Scikit-learn 等多种Python库,打通机器学习的任督二脉,在真实的数据科学竞赛案例和数据挖掘项目的打磨下,完成从数据科学小白到骨灰级玩家的华丽转变!
作为第4/5期的实训营助教,寄语小白学员:坚持跟上课程进度,按时完成所有作业,认真做好学习笔记,最终一定可以实现轻松入门数据科学哈!

志愿者介绍










文章评论