
夕爷、写词高手、词圣,这是大家公认的金牌词人林夕的各种称号。哥哥、张学友、王菲、陈奕迅、杨千嬅等等天王天后,有了林夕的量身定做,便包揽了几代人的耳朵。在夕爷的三千余首词中,随便拈一首, 便不知有多少人为之痛哭流涕或暗自泪流。安妮宝贝说:“林夕是高手,轻描淡写,也伤人三分。”
夕爷的词为何有如此强大的催泪能力,歌词本身传递了什么讯息?借助火爆的python,和强大的jieba、wordcloud等模块,让我们看看夕爷都写了些啥。
处座选了夕爷的2563首作品,作为分析的样本。首先做文本预处理,整理停用词表stopwords,如我、你,还有各种标点符号等,防止这些无意义且词频高的词影响分析结果。
下面就要真正开始分析歌词啦。
“彼此多么好,也不得不分开”
jieba包是很好用的中文分词工具(“结巴”这个名字也很切合分词的目的,说话结巴,自然就分词啦,哈哈~)加载jieba模块,对歌词文本进行切词,再去掉停用词表中的词,就得到了切分后的字词。
程序代码如下(上下滑动可看):
“故事平淡,但当中有你已经足够”
在去掉停用词的前提下,利用wordcloud模块将处理后的歌词文本生成词云,大家随意感受一下,不管酸甜还是苦辣,满满的都是爱情的味道~

为了看看夕爷的用词偏好,处座先统计出了前2000个高频词,然后从三个维度对这2000个词进行了统计。
程序代码如下(上下滑动可看):
#
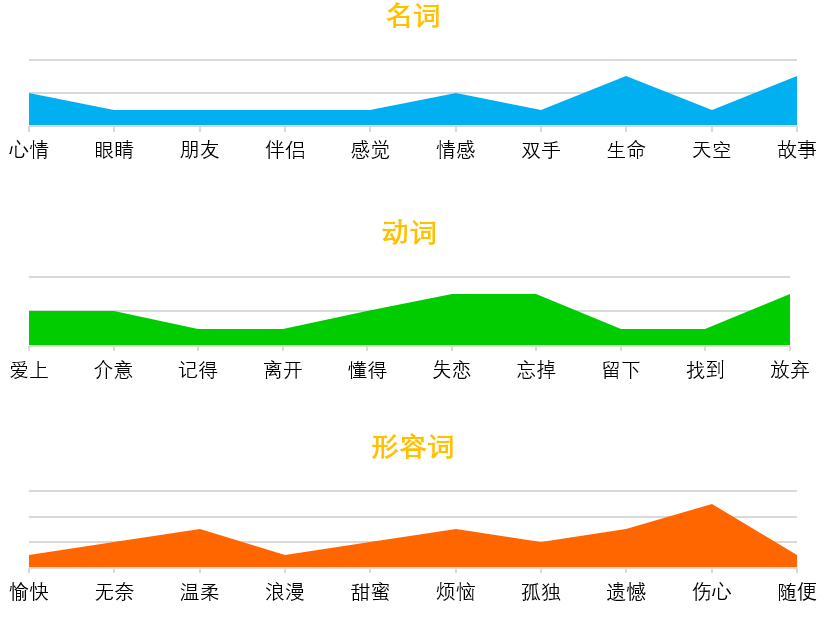
词 性
名词、动词、形容词是最具实际意义的词性,因此对这三类分别进行统计,每类选取前十个做可视化处理。在夕爷的词里,爱情是甜蜜的,可我却尝遍了爱情里所有的苦,不是想放弃,而是不知如何坚持。这前十个词中,名词多为深沉的感悟,如“生命”、“故事”等,动词则用了“忘掉”、“放弃”这类词,而形容词作为情感的直接表达,“伤心”等词更直抒胸臆,从中隐约能感受到想用力抓住爱情,但处处都是无力感。
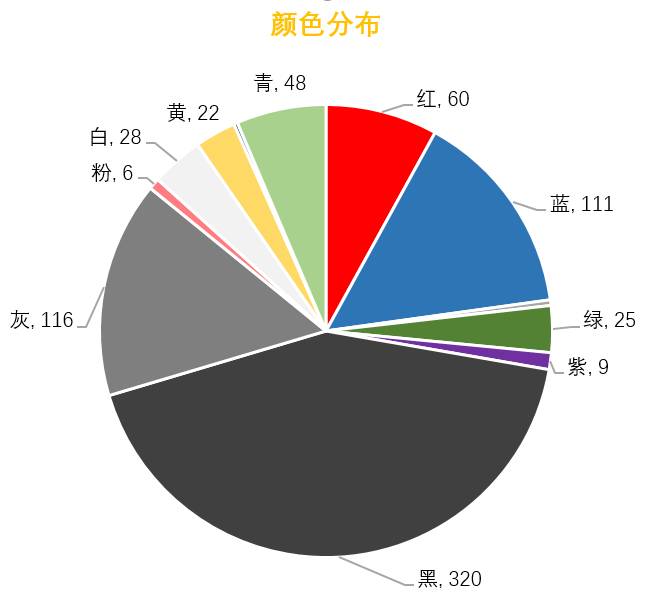
颜 色
心理学中,不同的颜色有不同的寓意。比如,红色寓意热情、活泼,绿色寓意健康、希望,紫色优雅、可爱,黑色深沉、忧郁,灰色寂寞、冷淡……对前2000个高频词中的颜色进行统计,这部分的统计需要人工辅助,比如“红尘”,出现了“红”字,但它并不代表红色。从下面的饼状图中也能发现黑和灰是歌词的主色调。衣服、披肩、天空,甚至连雨都被夕爷写成了黑色,而明亮的寓意希望的颜色,比如红、绿,则出现甚少。歌词对于黑、灰等颜色的偏爱,深化了忧郁的感觉。
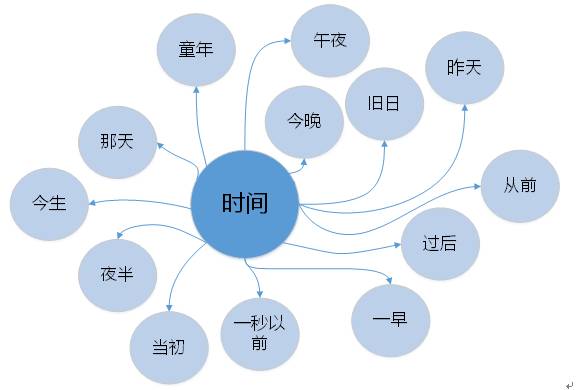
时间用词
从前2000个高频词中提取出时间用词,夜半时分,或忆童年,或追往事,或念昨天,却不望未来,就算偶尔想到未来,也是没有你的日子。时间用词偏向回忆过去,而不是对未来的向往,回忆往往能触动内心,所以听歌会哭的,大概都是有故事的人吧。
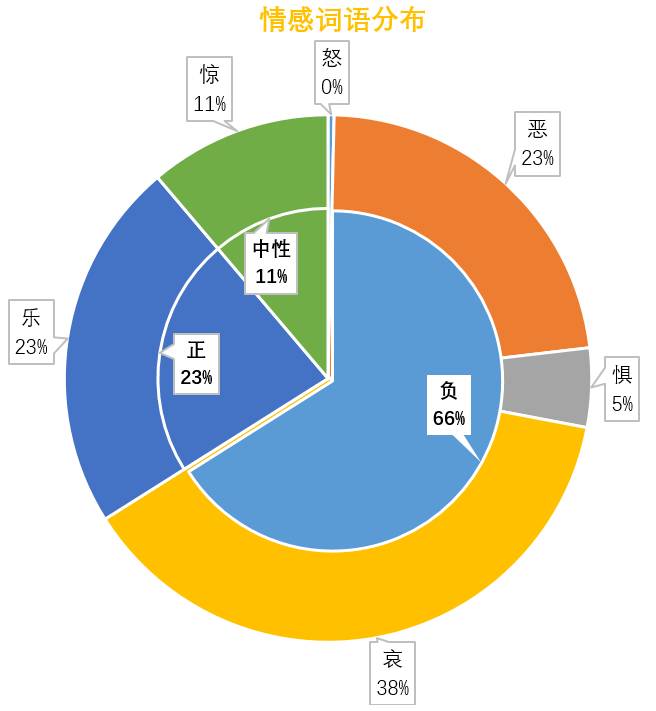
“喜怒和哀乐,由我来重蹈你覆辙”
调用nlpir对前2000个高频词进行情感分析,自动识别情感词和计算权重,采用Bootstrapping策略,通过迭代,最终得到情感属性及其相应的权重。从下面的双层饼状图可以看出,如果按照正负中来分类,负面情绪词语占66%,绝对碾压正面情绪的词语。再将情绪细分,占比最大的是“哀”,如苦、哭。

上述几个维度的数据已经让我们感受到了夕爷赋予文字的神奇力量,通过分词、感性分析,能够帮助我们更好理解歌词的用语特征和情感倾向。
但中文常富含深意,一个句子的效果可能远强于字词。所以不可避免地漏掉了一些无法用程序识别,但人心感受强烈的词语或语句,比如 “原来我非不快乐,只我一人未发觉”,细品几遍,愈感伤心,把不快乐过成了快乐的样子,是比悲伤更悲伤的感觉。
jieba分词是很好用很强大的中文文本处理工具,关于jieba模块的其它用法以及文本处理更深入的讨论,还有待处座继续摸索。最后,借夕爷的词,献给你——“什么都可以错过,请别再错过我”。

▼▼▼
为了促进行业从业人员之间的学习和交流,目前已开通1.贷前风控、2.反欺诈、3.Python交流群、4.FinTech大数据技术等四个微信交流群。扫描下列二维码,添加管理员为好友,并回复管理员你所关注喜好领域的关键词,管理员将拉你进入对应的500人交流群。

▼▼▼

文章评论