选自Statsbot
机器之心编译
参与:Smith、俞云开
现如今,许多公司使用大数据来做超级相关推荐,并以此来增加收益。在海量推荐算法中,数据科学家需要根据商业限制以及需求来选择最佳算法。为使其简单化,Statsbot 团队为现有的主要推荐系统算法准备了一份概述。
协同过滤
协同过滤(CF)及其变式是最常用的推荐算法之一。即使是数据科学的初学者,也能凭之建立起自己的个性化电影推荐系统,例如,一个简历项目。
当我们想要向某个用户推荐某物时,最合乎情理的事情就是找到与他/她具有相同爱好的用户,分析其行为,并且为之推荐相同的东西。或者我们可以关注那些与该用户之前购买物品相似的东西,并推荐相似的产品。
协同过滤(CF)有两种基本方法,它们分别是:基于用户的协同过滤技术和基于项目的协同过滤技术。
该推荐算法的以上情形中均包含两步:
1. 找到数据库中有多少用户/项目与目标用户/项目相似。
2. 在给定与某产品用户/项目更相似的用户/项目的总权重时,评估其它用户/项目,来预测你给用户的相关产品的评分。
在该算法中,「最为相似」意味着什么?
我们拥有的是每一位用户的偏好向量(矩阵 R 的列),以及每一个产品的用户评分的向量(矩阵 R 的行)。
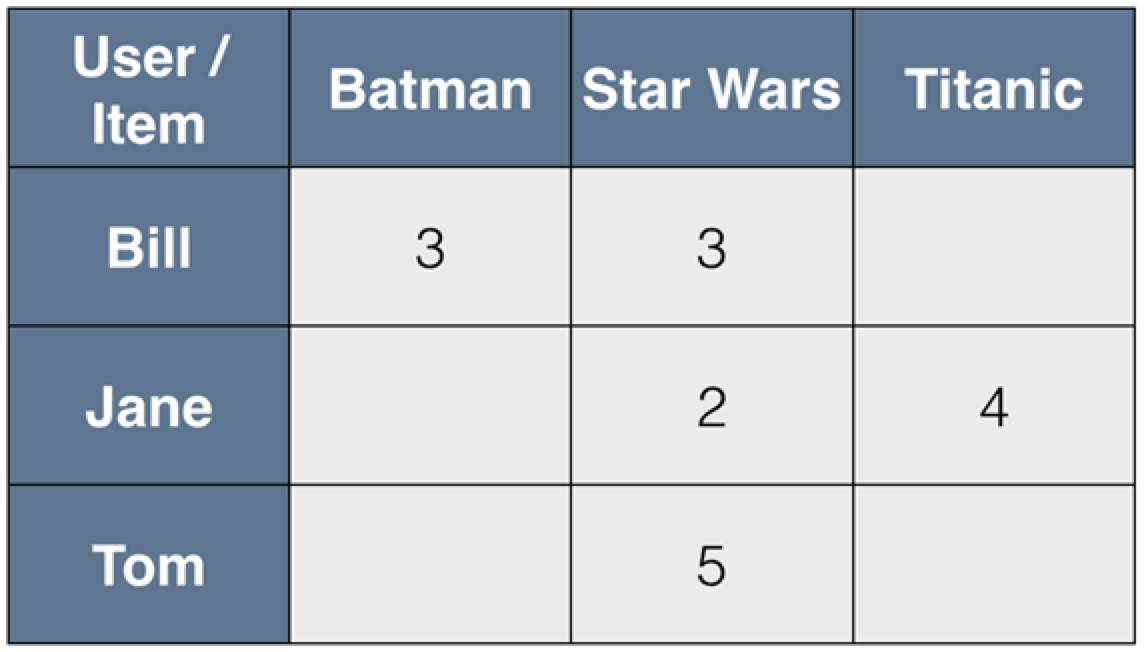
首先,只留下两个向量中值都已知的元素。
举个例子,如果我们想比较 Bill 和 Jane,我们知道的信息是 Bill 没有看过泰坦尼克号,Jane 没有看过蝙蝠侠,那么我们只能通过星战来衡量他们的相似度。怎么可能会有人不看星战,对吧?(微笑)
最流行的测量相似度的方法,是测量用户/项目向量的余弦相似度(cosine similarity)或相关度(correlations)。最后一步是根据相似程度,采取加权算术平均方法,填满表中的空单元格。
用于推荐的矩阵分解
另一个有趣的方法是使用矩阵分解。这是一种优雅的推荐算法,因为通常在矩阵分解时,我们不会过多考虑结果矩阵的行列中哪些项(item)会被保留。但使用该推荐工具时,我们可以清楚地看到 u 是关于第 i 个用户的兴趣的向量,而 v 是关于第 j 部电影的参数的向量。
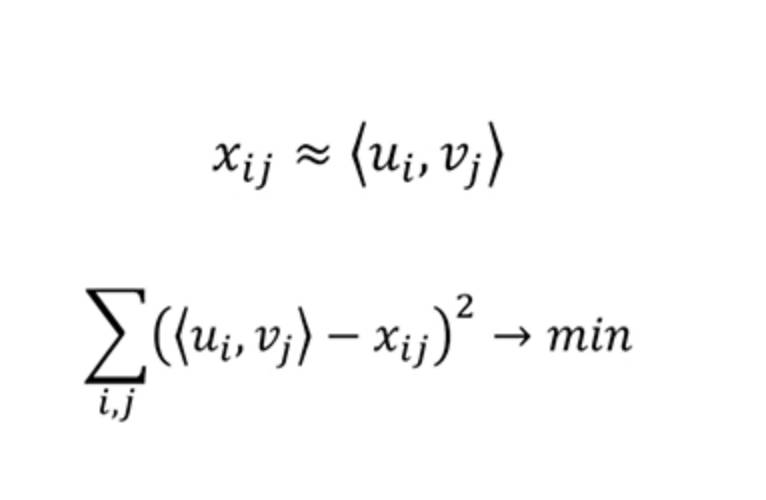
于是我们能够通过 u 和 v 的点积来估计 x(第 i 个用户对第 j 部电影的评分)。我们用已知的评分建立这些向量并以此预测未知的评分。
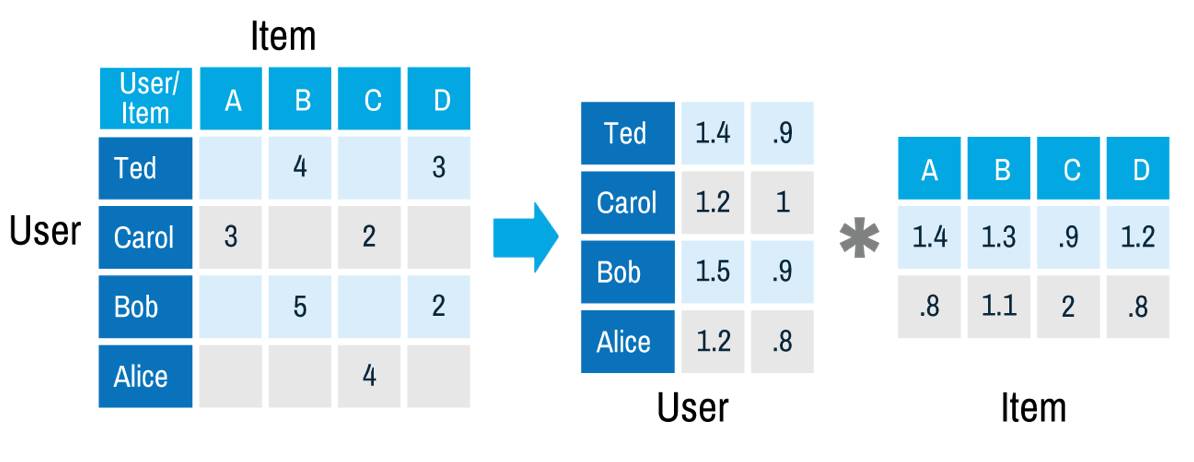
举个例子,矩阵分解后我们获得了 Ted 的向量(1.4;.9)和电影 A 的向量(1.4; .8),现在我们可以仅仅通过计算(1.4; .9)和(1.4; .8)的点积来还原电影 A-Ted 的评分,评分结果为 2.68。
聚类
以前的推荐算法比较简单并且适用于小系统。而且直到现在,我们仍把推荐问题设想成一个监督式机器学习任务。现在是时候用非监督方法来解决此类问题了。
设想一下,我们是正在建造一个大型推荐系统,在此系统中协同过滤和矩阵分解这两项工作的时间应该更长。而第一种设想就是聚类(clustering)。
在业务的开始阶段,往往是缺乏先前用户的等级划分的,而聚类则是最好的方法。
但是如果单独使用,聚类就显得有一些薄弱了,因为事实上我们所做的事情其实是对用户组别进行鉴定,并且为本组里的每一位用户推荐相同的东西。当我们拥有了足够的数据的时候,使用聚类方法作为第一步是更好的选择,这样可以减少协同过滤算法中的相关近邻(neighbor)的选择。它也可以改善复杂推荐系统的性能表现。
每一个群集(cluster)都会被分配有代表性的偏好,这是以属于该群集的用户的偏好为基础的。每一组群集的用户都会收到在群集层面上计算过的推荐结果。
推荐系统的深度学习方法
在过去十年,神经网络的发展已经有了巨大的飞跃。现在它们正被应用于各种各样的应用,并且正在逐渐代替传统的机器学习方法。下面我将展示深度学习方法是如何在 Youtube 中被使用的。
毋庸置疑,由于其规模大,语料库不断变化,以及种种不可观测的外部因素,为这样的服务项目制作推荐系统是一项极具挑战性的任务。
根据「YouTube 推荐系统的深度神经网络」的相关研究,YouTube 推荐系统算法包含两部分神经网络:一个是用于候选集生成(candidate generation),另一个则是用于排序。如果你没有足够的时间,我将在这里给你进行一个简要的概括。
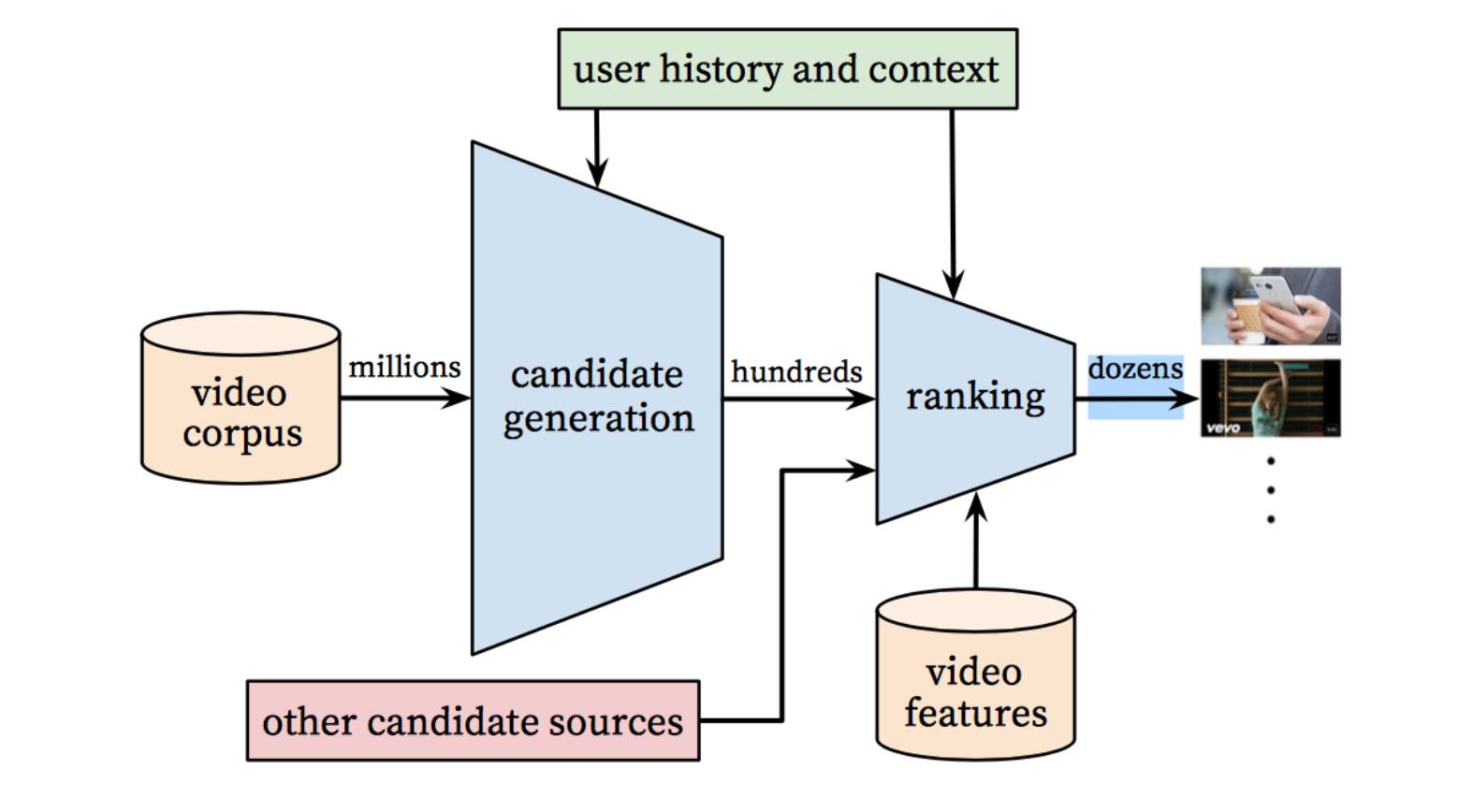
使用用户的历史作为输入,候选集生成网络(candidate generation network)显著地减少了视频的数量,并且可以从一个大型语料库中选取一组最相关的视频集。生成的候选集对用户来说是最为相关的,此神经网络的目的仅仅是为了通过协同过滤来提供一个宽泛的个性化服务。
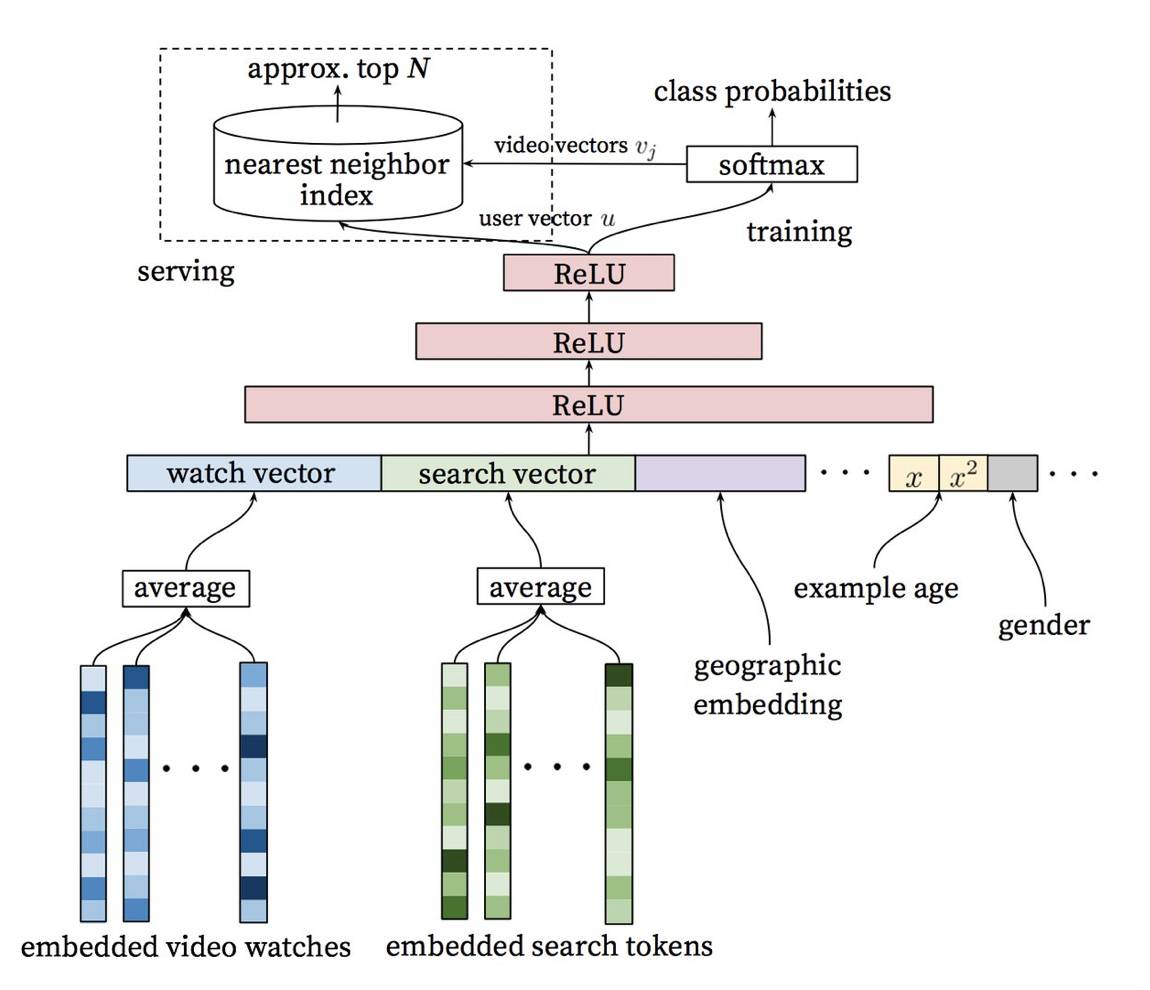
在这一步中,我们拥有了更少量的候选结果,这些结果与用户需求更加接近。我们现在的目的是仔细地分析所有候选结果,这样我们就可以做出最好的决策。此任务是由排序网络(ranking network)来完成的,它可以根据一个期望的目标函数为每一个视频都分配一个分数,这个目标函数是使用数据来对有关用户行为的视频和信息来进行描述的。
使用两阶段法(two-stage approach),我们就能够从很大的视频语料库中做出视频推荐,然而可以确信的是,这些推荐结果中只有少量是个性化的,而且是被用户真正进行应用的。这一设计也能使我们把其它资源生成的结果和这些候选结果混合在一起。
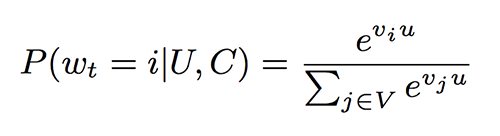
推荐任务就像是一个极端的多类别分类问题,预测问题变成了一个在给定的时间 t 下,基于用户(U)和语境(C),对语料库(V)中数百万的视频类别(i)中的一个特定视频(wt)进行精准分类的问题。
在创建你自己的推荐系统前要注意的要点:
-
如果你拥有一个很大的数据库,并且你要用它进行在线推荐,最好的方式就是把这个问题分成两个子问题:1)选择前 N 个候选结果,2)对它们进行排序。
-
你怎样衡量你的模型的质量?除了标准化的质量指标,还有一些用于推荐问题中特定的指标:Recall@k,Precision@k也可看一下推荐系统的最佳描述指标。
-
如果你正在使用分类算法解决推荐问题,你应该考虑生成负样本(negative samples)。如果一个用户买了一件推荐的商品,你不应该把它当做正样本(positive sample)来进行添加,也不应该把其余作为负样本来处理。
-
考虑一下你的算法质量的在线与离线评分。一个仅基于历史数据的训练模型可以产生简单的推荐结果,因为该算法并不会知道未来的新趋势与偏好。


原文链接:https://blog.statsbot.co/recommendation-system-algorithms-ba67f39ac9a3
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]
点击阅读原文,查看机器之心官网↓↓↓

文章评论