
大数据文摘作品,转载要求见文末
原作者 | Moritz Mueller-Freitag
编译 | 笪洁琼 万如苑 一针
长期以来,在机器学习中不合理的数据利用效率一直是引起广泛讨论的话题。也有人认为,曾经阻碍人工智能领域取得各种重大突破的,并不是什么高深的算法,而是缺乏高质量的数据集。然而讨论的共同中心是,在当下最前沿的机器学习方面,数据是一个相当关键的组成部分。
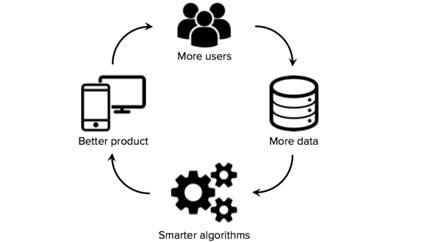
获取高质量的初始数据对于那些运用机器学习作为他们业务核心技术的创业公司来说是十分重要的。虽然许多算法和软件工具都是开源和共享的,但是好的数据通常是私人专有而且难以创建的。因此,拥有一个大型的、特定领域的数据集可以成为竞争优势的重要来源,尤其是如果初创公司能够启动数据网络效应(在这种情况下,更多的用户→更多的数据→更智能的算法→更好的产品→继续带来更多的用户)。
因此,对于机器学习创业公司必须做出的一个关键战略决策是如何建立高质量的数据集来训练他们学习算法。不幸的是,初创公司往往在一开始只有有限的或没有标签的数据,这一情况会阻碍创始人在构建数据驱动的产品方面取得重大进展。因此,在雇佣数据科学团队或建立昂贵的核心基础设施之前,从一开始就值得探索一套数据收集策略。
创业公司可以通过多种方式克服刚开始进行数据采集时遇到的棘手的问题。数据战略/资源的选择通常与商业模式的选择、创业公司的关注重点(消费者或企业、横向或纵向的)以及融资情况密切相关。以下简单列出几种并不互斥的策略,为广泛的可用方法提供了一种大体框架。
策略#1:手动工作
从头构建一个良好的专有数据集基本意味着要将大量的前期工作和人力资源投入到数据获取上,还要完成大量无法批量完成的的手动工作。在初期借助人力的创业公司的例子很多。例如,许多聊天机器人初创公司(通过改变对成功的定义和高职工流动率吸引求职者)雇佣真人来做“人工智能培训师”,让他们手动创建或验证机器人所说的话。就连科技巨头也采取了这种策略:Facebook M(一个最新内置在Facebook Messenger中人工智能驱动的数字助理)的所有回应都是由一个承包商团队审查和编辑的。

使用人力来手动标记数据点可以是一个成功的策略,只要数据网络效应在某个时间点生效,这样所需要的人力就不再以与用户增长相同的速度增加。只要人工智能系统进步的速度足够快,未指明错误就会出现地不那么频繁,相应地,执行手工标记的人的数量也将会减少或保持不变。
适用对象:几乎每一家机器学习创业公司
例子:
1.一些聊天机器人创业公司(包括Magic、GoButler、x.AI和Clara)
2.MetaMind(用于食品分类的手工收集和标记数据集)
3.Building Radar(员工/实习生手动标记建筑物的图片)
策略#2:缩小问题范围
大多数创业公司都会尝试直接从用户那里收集数据。
挑战在于说服早期用户在机器学习的好处完全发挥作用之前保持使用该产品(因为首先需要数据来训练和微调算法)。
解决这个自相矛盾的问题的方法之一,是彻底缩小问题范围(如果需要的话,可以在之后再扩大)。正如Chris Dixon所说:“你所需要的数据量与你试图解决的问题的广度有关。”
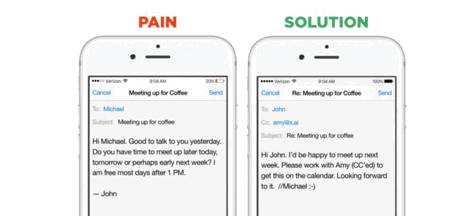
Source: x.ai(来源于X.AI)
这样缩小问题范围的好处再一次体现在聊天机器人上。这一领域的创业公司可以在两种市场策略之间做出选择:他们可以建立水平助手——可以帮助解决大量问题和回应即时请求的机器人(比如Viv、Magic、Awesome、Maluuba和Jam)。或者,他们也可以创建垂直助手——能出色完成一项具体、明确的任务的机器人(例如x.ai, Clara, DigitalGenius, Kasisto, Meekan以及最近的GoButler/Angel.ai)。这两种方法都是有效的,不管如何选择,只要缩小了问题的范围,数据收集对创业公司来说都要容易得多。
适用对象:经营垂直整合业务的公司
例子:
1.高度专业化的垂直聊天机器人(如 x.ai, Clara or GoButler)
2.Deep Genomics(利用深度学习来分类/解释基因变异)
3.Quantified Skin(使用客户自拍照来分析一个人的皮肤)
策略#3:众包/外包
除了让员工(或实习生)来手动收集或标注数据,创业公司也可以通过众包来达到目的。像Amazon Mechanical Turk 或CrowdFlower 的平台提供了一种方法,可以利用数百万人的在线劳动力来清理混乱和不完整的数据。例如,VocalIQ(2015年被苹果收购)使用亚马逊土耳其机器人为其数字助手提供数千个用户提出的问题。员工也可以通过雇佣其他独立的承包商来外包(就像Clara 或Facebook M所做的那样)。使用这种方法的必要条件是可以清楚地解释这个任务,而且它不至于太长或者很无聊。

另一种策略是鼓励公众自愿提供数据。一家总部位于巴黎的人工智能创业公司Snips就是一个例子,该公司利用这种方法获得特定类型的数据(餐厅、酒店和航空公司的电子确认信)。和其他创业公司一样,Snips使用的是一种游戏化的系统,用户可以在排行榜上进行排名。
适用对象:可以很容易地执行质量控制的情况
例子:
1. DeepMind, Maluuba, AlchemyAPI,和其他很多人(见这里see here)
2.VocalIQ(用土耳其机器人帮助系统学习人们如何说话)
3. Snips (要求人们无偿为研究提供数据)
策略# 4:引导用户自发参与
有一种能够自成一类的众包策略,是通过恰当的方式引导用户自发地产生数据。这种方法中很重要的一步是设计能够为用户提供恰当激励,使其主动将数据结果反馈给系统的产品。
那些在自家许多产品中都使用了这种方法的公司里,有两个十分典型的例子:谷歌(搜索引擎、谷歌翻译、垃圾邮件过滤器等等)和Facebook(用户可在照片中给朋友加标签)。用户通常不知道他们的行为在为这些公司提供免费的标签数据。
机器学习领域的许多初创公司都从谷歌和Facebook中汲取了灵感,他们创建了具有纠错功能的产品,明确地鼓励用户纠正机器错误。这方面特别出名的是reCAPTCHA 验证码和Duolingo(都是由路易斯冯创立的)。其他的例子包括Unbabel,Wit.ai 和 Mapillary.
适用对象:以消费者为中心并且有稳定用户交互的创业公司
例子:
1.Unbabel(用户纠正机器翻译的社区)
2. Wit.ai (为用户提供了用于纠正翻译错误的面板/api)
3. Mapillary (用户可以纠正机器生成的交通标志检测)
策略# 5:开发副业务
一个似乎特别受计算机视觉创业公司欢迎的策略是有针对性地向用户提供一个免费的、特定领域的手机app。
Clarifai、HyperVerge和Madbits(2014年被Twitter收购)都采取了这一策略,它们向用户提供能够为自己的核心业务收集额外图像数据的照片应用。
Source: Clarifai(来源于Clarifai)
这个策略并不是完全没有风险(毕竟,成功开发和推广一个app是要花费时间和金钱的)。 创业公司还必须确保他们创建了一个足够强大的使用案例,能让用户乖乖交出他们的使用数据,即使在开始时缺少数据网络效应的优势。
适用对象:初创企业/横向平台
例子:
* Clarifai(Forevery,可用来发现新照片的应用程序)
* HyperVerge(Silver,可用来组织照片的应用程序)
* Madbits(Momentsia,可用来拼贴照片的应用程序)
策略#6:数据陷阱
另一种收集有效数据排放的方法是构建Matt Turck所谓的“数据陷阱”(Leo Polovets已经给了这个策略一个不太可爱的名字:“特洛伊木马收集数据法”)。 目标是创造一些即使在没有机器学习的情况下也有价值的东西,然后以收集数据的成本出售(即使其中的边际效益很小)。 与之前的策略形成对比的是,构建数据陷阱是创业公司商业模型的核心部分(而不仅仅是一个副业务)。

一个相关的例子是Recombine,一家临床基因检测公司,通过提供生殖力测试服务来收集DNA数据,然后可以将DNA数据用机器学习进行分析。 另一个例子是BillGuard(被Prosper于2015年收购),一家提供了一个帮助信用卡用户争取“灰色费用”的移动端app的创业公司。该应用程序帮助BillGuard获得大量之后还可以用于其他目的欺诈数据。 另一边Telsla也正在使用这个策略。作为拥有超过10万辆(配有传感器的)车辆正被用于行驶的公司,Tesla目前正在建造最大的自动驾驶训练数据集(每天可以收集比Google更多的自动驾驶里程)。
适用对象:经营垂直整合业务的企业
例子:
*Recombine(提供生育力测试来收集DNA数据)
* BillGuard(提供移动应用程序来收集欺诈数据)
*Tesla(当驾驶员使用自动驾驶功能时收集数据)

策略#7:公开可用的数据集
一个许多创业公司都屡试不爽的策略是在公开来源中挖掘数据。像“普通抓取”这样的网络存档包含多年网络爬虫收集的免费原始数据。另外,像Yahoo或Criteo这样的公司已经向研究界发布过了大量数据集(雅虎发布了13.5 TB的未压缩数据!)。随着最近政府公开数据库的蓬勃发展(由奥巴马政府引领),越来越多的数据来源正在免费公开。
几家机器学习初创公司已经在利用公共数据了。当Oren Etzioni开始Farecast(由Microsoft于2008年收购)时,他使用了在旅游网站抓取信息而获得的12,000个价格观察样本。同样,SwiftKey(由Microsoft于2016年收购)在早期收集并分析了数十亿网页爬虫数据,来创建它的语言模型。
适用对象:可以识别相关公共数据集的初创公司
例子:
* Farecast(第一版从旅游网站爬取的信息)
* SwiftKey(抓取网页文字来创建语言模型)
*The Echo Nest(每天爬取数百万个音乐相关网站)
* Jetpac(将公共Instagram数据用于其移动应用程序)
策略#8:第三方数据许可
访问第三方数据的另一种方法是通过外部数据提供者提供的API或通过在第三方移动应用程序中实施SDK来抓取数据(理想情况下是终端用户同意)来得到许可。 在这两种情况下,创业公司都要支付另外一方来处理为某个目的而生成的数据,然后应用机器学习从该数据中提取新价值。
Farecast和Decide.com(均由Oren Etzioni创立)已经成功地实施了这一战略。 开放的数据平台,如Clearbit或Factual是外部数据提供者的典范。 在使用第三方数据来挖掘预测信息的公司中,也有几家对冲基金和算法交易公司(正在使用非传统数据集,如Orbital Insight或Rezatec等创业公司的卫星数据)。
适用对象:依靠第三方数据的创业公司(如行业数据)
例子:
* Farecast(通过航空公司的数据使用许可来预测机票价格)
* Decide.com(通过电子商务的数据使用许可来预测价格)
*Building Radar(使用ESA卫星图像来监测建设项目)
战略#9:与大企业协作
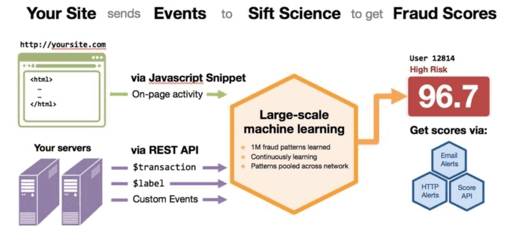
对于初创企业,数据提供者可能是提供相关数据处理权的大客户。在这个策略中,创业公司向客户出售问题的解决方案(如减少欺诈),并使用客户的数据训练其学习算法。 在理想情况下,从一个客户或实例中做的数据学习可以转移给所有其他客户。 例如在测谎领域的Sift Science和SentinelOne。
采用这种方法的难点在于如何在前期做好谈判,确认通过数据学习到的信息都归创业公司所拥有,而数据本身仍是顾客的资产。 鉴于大型公司通常具有严格的规则,并且对共享专有数据非常敏感,这是很容易产生分歧的地方。
适用对象:企业创业公司
例子:
*Sift Science(使用公司特有数据查找独特的欺诈信号)
* SentinelOne(销售终端保护软件的网络安全初创公司)
* Skytree(开发用于企业使用的机器学习软件)
策略#10:小型收购
Matt Turck列出了许多公司的收购方式,以获得特别相关的数据集(类似于收购有价值的专利组合)。 例如,IBM Watson在2015年进行了四次与数据有关的收购,将其卫生部门转变为世界上最大和最多样化的健康相关数据库之一。

由于这种方法需要资金支持,所以可能只对于拥有充裕资金的创业公司来说是可行的。
适用对象:(后期)有足够资金的创业公司
示例:难以确定(数据是收购的唯一原因)
很可能还有其他数据采集策略在这里没有提到(如果是,请给我留言)。除此之外还有几个初创公司可以用来解决数据问题的算法技巧(例如传输学习,MetaMind使用的一个技术)。
无论您采取何种策略,关键信息是:获取和拥有大型特定领域的数据集以构建高精度模型可能是创业者一开始就需要解决的最难的问题。在某些情况下,它涉及到找一个能快速解决问题但不是长久之计的方案,比如雇佣人类来假装是人工智能(像许多聊天机器人创业公司那样)。 在其他情况下,它要求企业大大地延长免费周期,限制测试版的公开发布,直到机器学习的好处开始发挥作用而且客户愿意为此付费。
这些策略和例子来自与企业家们的谈话以及几个博客文章,其中包括内森·贝纳奇(Nathan Benaich)(这里here),克里斯·迪克森(Chris Dixon)(这里here),弗洛里安·杜特奥(Florian Douetteau)(这里here),利奥·波洛维奇(这里here),马特·图克(Matt Turck) (这里here)。

原文链接:https://medium.com/@muellerfreitag/10-data-acquisition-strategies-for-startups-47166580ee48

点击阅读原文,了解课程详情!

关于转载
如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘 | bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:zz@bigdatadigest.cn。
回复“志愿者”加入我们



点击图片阅读




文章评论