大牛带你8周搞定
Node.js、SQL、D3.js
《数据可视化工程师》
6月24日开课
距离优惠截止
仅 7 天
详情见文末
(作者:郑林峰)深夜闲来无事,默默的打开github,在搜索框中填入了”Stars:>1”,本想着依旧可以在第一页看到Spark的身影,结果第一个映入眼帘的是这个:
快速浏览完第一页(Top10),10个项目里面7个JS或者具体来说是Node.js的项目!Github历来代表技术圈发展的风向,那么这个在Github比Spark更受追捧的Node.js,到底厉害在哪里?
爱的初体验Node.js:一体化数据可视化。

第一次听说“一体化数据可视化”我的内心是抗拒的,怎么可能,我的经验告诉我,做数据可视化,需要获取数据、处理数据、载入数据、呈现数据等多个过程,各种更是涉及到爬虫、ETL、SQL、HTML、服务端开发等多项技能,一个工具根本无法搞定。
不过抱着一种谨慎的心态,我还是决定先去研究一下Node.js究竟能够做什么:
随后我看到了颠覆我世界观人生观价值观的一片文章:爬虫性能:Node.js VS Python (“http://python.jobbole.com/86257/”)
以下内容为针对此文章内容的一些要点的提炼,有兴趣的可以浏览以下,大神请自行跳过此段:
文章主要想要通过爬虫证明Node.js的异步策略与I/O能力,看是否真的有官方介绍和相关文件描述的这么强势。(注意:文中作者为了更好的测试Python的性能,并未使用Scrapy等Python爬虫框架。)
爬虫的设计中,为了降低被网站拉黑的风险,同时防止因为头文件导致爬虫获取数据内容的不一致,一致的web请求头是必不可少的,针对一些特殊的网站,甚至还需要人为的加入cookies、网络代理等形式去更好的保护我们的爬虫不被网站拉黑。文中作者由于测试目的及测试网站自身的反扒机制问题,并未使用较为繁琐的设定,具体内容如下:

常规爬虫的设计中需要设定一个url队列,通过分工协作的方式,某些线程专门用于解析队列中的某类或某几类的url,某些线程专门用于将解析后的结果进行处理(数据落地,新url重入队列等)。文中作者分别制作了Python单线程版,Python多线程版和Node.js版3种爬虫,接下来我们一一分析作者这样设计的实现:
2.1 Python单线程版


整个代码逻辑较为简单,被爬网页url后缀为页面,单线程版中通过for循环,在单个线程中完成对30个页面内共计720个课程的初步内容提取,整个过程为线程获取url信息,通过网络获取对应url页面的具体html代码,针对html代码解析相关课程的内容,并通过遍历的方式完成计数。
运行结果越为46s左右,平均每个页面耗时1.5秒,基本略高于我们正常浏览器点击网页后加载完毕页面的时间,性能相对较低。
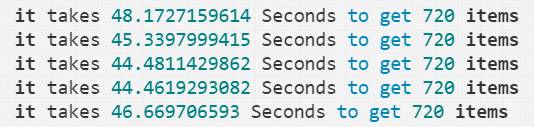
{ it takes 48.1727159614 Seconds to get 720 items
it takes45.3397999415 Seconds to get 720 items
it takes44.4811429862 Seconds to get 720 items
it takes44.4619293082 Seconds to get 720 items
it takes46.669706593 Seconds to get 720 items }
2.2 Python多线程版
由于篇幅原因,此处主要说明为何Python多线程速度(运行结果显示,处理完毕30个页面数据总耗时约为11.5秒)会远远高于Python单线程的原因。

{it takes 11.6800132309 Seconds to get 720 items
it takes 11.3621804427 Seconds to get 720 items
it takes 11.6811991567 Seconds to get 720items }
单线程中,一个线程每次只能执行一个命令,多个命令根据设定好的内容依次执行,在此过程中,由于网络传输等原因,CPU在网络传输的过程中由于无其他可处理的线程,导致存在计算资源的闲置浪费,与此同时由于单次只响应一个页面,计算机的网络带宽使用也远远无法达到上限,故整体耗时较长。
多线程模型中,程序通过新建数十个线程,每个线程处理一个页面的请求处理和解析,整体过程中若CPU的通道数(可以理解为CPU可以同时处理的线程数,目前常规笔记本为2核4通道)低于需要处理的线程数,则根据CPU调度线程原理,当CPU调度的线程开始进行数据IO的时候,CPU会暂时闲置线程,处理其他需要处理的线程,等到线程IO完毕后,继续进行后续内容的调度,从而起到充分利用CPU计算能力的目的。同时多线程对网站进行请求,相比单线程版也起到了大大降低请求平均相应时间的作用,从而其到了提高爬虫性能的作用。
2.3 Node.js版
为了便于大家可以直接在电脑上面测试,Node.js代码我先搬运过来:


整体的思路和Python单线程版类似,以列表遍历的形式产生URL串,提交代码执行,最后输出结果,平均下来处理30个页面的平均时间在3.8秒左右。
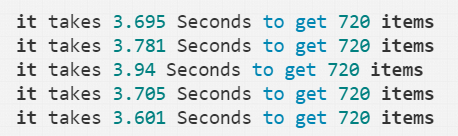
{it takes 3.695 Seconds to get 720 items
it takes 3.781 Seconds to get 720 items
it takes 3.94 Seconds to get 720 items
it takes 3.705 Seconds to get 720 items
it takes 3.601 Seconds to get 720 items}
如果单从这个结果考虑,貌似Python的多线程版还存在优势?其实不然,由于Node.js的特性,本文使用的Node.js是单线程进行的,而与之对应的Python多线程版本应该仅分配一个物理通道进行计算才算公平,而按照作者文章中的处理时间看,多线程部署机器的通道数估计会较高,不然不会有如此的性能(请参考单线程版的单页面处理时间的1.5s)。所以综合来看,在爬虫这类对于高并发和高I/O的具体应用上,Node.js还是展示了他应有的风采。
注意:
编程工具不管怎么高效,依旧无法摆脱物理性能的约束,针对具体业务的每一次代码优化都是存在着某种成本,若场景为一个极高请求数,但是单请求对于网络带宽需求较少的应用,例如通过调用API的方式去穷举数据,提高线程数往往是一个比较好的选择。
但是在一些图片采集内容中,较高线程数导致的网络带宽瓶颈却往往会导致程序的性能降低(CPU在调度线程中也是存在一定的性能损耗的),使用一定的线程数往往可以起到更加好的效果。
虽说作者在性能对比中并没有将各类条件控制得比较严苛,但就结果而言,Node.js在做爬虫相关的功能时,较Python还是有一定优势的。
总的来说,PHP、Python、Node.js,哪个比较适合写爬虫呢?
PHP:由于其对于多线程和异步的支持较差,在爬虫领域较不推荐;
Python:目前主流的爬虫框架语言,对于分布式爬取的支持较好,针对企业级的大规模爬虫等项目强力推荐;
Node.js:由于其异步处理机制的特性,对于垂直网站的爬取具有较好的性能和较低的学习成本,但是其对于分布式爬取和消息通讯的支持较弱,大规模的爬虫项目的使用难度较高。
而为何选择使用Node.js作为爬虫语言?
◆ Node.js作为一种JS语言,入门门槛较低;
◆ 其对于数据可视化的后端数据支持能力较好(高并发和I/O密集支持),降低学习门槛和压力;
◆ 业界流行通过Node.js去制作web架构中的中间件,完成设置路由,请求接口,渲染页面等功能,在高效的同时也保证网页的seo和安全性(对比Ajax,可浏览下文:AJAX技术对于SEO的影响 http://blog.csdn.net/dengxingbo/article/details/5756567)
相比而言,Node.js的优点:
◆ 高并发:如此专业的词汇,身为一个单纯的吃货还真很难理解,便附上一句文中的总结“Java、PHP也有办法实现并行请求(子线程),但Node.js通过回调函数(Callback)和异步机制会做得很自然”;
◆ 适合I/O密集型应用:不行了再看下去要被安利了,赶紧调到缺点去。
……
Node.js的缺点(好样的,终于来了):
1. 不适合CPU密集型应用:好好好,吐槽点一号准备就绪;
4. 开源组件库质量参差不齐,更新快,向下不兼容;
5. Debug不方便,错误没有stack trace。
别问我为啥2,3不见了,明明就可以通过Nnigx可以解决的事情,还放在这么前面,由俭入奢易,由奢入俭难啊,提出一个缺点马上带上一个解决方法,夭寿啦。
……(此处省略许多关于Node.js的适用场景,作者用了一句话总结:Node.js能实现几乎一切的应用,我们考虑的点只是适不适合用它来做)
好歹找到一个糟点,搞大数据的,每每看到不适合CPU密集型,总是会有莫名的优越感,平时操作计算任务少说都是几百个core(自行脑补富土康VS小作坊)。
熟练地按下alt+tab,切出聊天窗口,飞快在聊天栏中打入:Node.js虽然说在爬虫方面还是略有性能优势(JS的老本行应该的),在后台开发中能够支持较高的并发能力(也算JS的一些特性),据说其对于IO密集型操作有着独到的解决方法(这个还是得服一波),可是其对于CPU密集性的功能要求支持度还是有点问题的(这玩意还是有点问题的,看我后一句怎么打你脸),说什么一体化数据可视化有点太过了吧!
等等,一体化的数据可视化,貌似和CPU密集性操作有那么一丢丢的差距,貌似这玩意还和D3.js的集成度还挺高。
这么说来,数据可视化的4个步骤(获取数据,处理数据,载入数据,呈现数据)里面,Node.js还真的解决了三个比较核心的问题:
至于处理数据…:“DBA大神,这个数据你这边能够帮我写个SQL直接出来么?”“后台大哥,你这边的接口里面能够帮我再加个计算字段么?这边我怕到时候用户一瞬间点了几千下,给人家弄死机了”……)
那么问题来了,我上面究竟写的是什么?

你以为是一个精分修炼手册么?不!其实这是一个广告O(∩_∩)O。
几天前,一次巧合看到了稀牛学院的《数据可视化工程师》课程。作为一个喜欢使用Scrapy的脑残粉,看到课程内容竟然是Node.js做爬虫,我这小暴脾气分分钟炸得稀里哗啦的。较真的我想着好好和老师交流沟通一波人生,便做了一波准备...然后就出现了上述精分现象。
课程基于Node.js讲解了从爬虫到后端开发到前段呈现的单一语言的一体化流程操作;适合入门型学员学习使用,学一种语言完成3种功能,活脱脱的事半功倍。
与此同时,课程还设置了至少11个案例展示与讲解,并以综合实战型结业项目收尾,真能分分钟教面试官做人的道理。
可视化课程当然少不了可视化的开源件。课程内使用了目前业界使用较多的Echart、D3等框架,基本和公司级别使用无缝衔接(信息源自各类友商)。
至于各类机构都十分推崇的所谓就业问题,我只能说,在我写这个文章的时候,我已经在幻想被群内的CDO、CEO看上,升职加薪,当上总经理,出任CEO,迎娶白富美,走上人生巅峰。
想想还有点小激动呢,嘿嘿~~

本文作者郑林峰
商学院背景,从医疗行业跨越到数据领域。报名学习了大数据文摘x稀牛学院所有课程,从小白一路飞升~目前是《数据可视化工程师》课程助教之一,同时也是“稀牛学院Plan A”(众多学员成长计划之一)一期成员,表现可圈可点,获大神称赞!
郑大侠既能鼓励小白勇敢开始,又能和JS全栈工程师探讨技术与技术,群活跃度直线飙升!也是助教界的扛把子呢~
课程预习群已发放预习资料,助教每晚答疑。
在线教育界,
讲师天团+就业辅导+高逼格负责任的助教团队+规范化的班级管理+学员努力
=学有所成
=offer手到擒来
如果:
-
想和郑林峰助教有更多互动,
-
想和小伙伴一起愉快地努力,
-
想短时间内迅速上手“爬虫+数据库+可视化”全流程,
-
拿到理想offer,那么本门课程你不应该错过!
我,在预习群等你!
点击【阅读原文】,直达课程直播页面

点击图片阅读文章




文章评论