專 欄
高金,知乎专栏 爬虫从入门到放弃的作者 ,喜欢爬虫!http://zhuanlan.zhihu.com/pachong
1.引言
我经常会看到有人在知乎上提问如何入门 Python 爬虫?如何学习Python爬虫[入门篇]?等这一些问题,我今天写这篇文章的目的就是来告诉大家,我为什么要学爬虫,爬虫的本质是什么。
2.我为什么要学爬虫
先说我吧,我当初为什么要学爬虫呢?
两年前,我还是个懵懂的小孩,那时候,基本上每天晚上都会上老司机论坛找电影,不知道大家知不知道老司机论坛,其实可以按照分类查找你想要看的电影的,但是它竟然没有多选(不能同时选择两个或多个分类进行查找)。比如 我想看“xxx”剧情+中文字幕的,我是怎么做的呢,先选择分类“xxx”,然后一页一页的ctrl+f 输入“中文” 查找......这样找了几天后,我发现这种方法简直太傻了,而是我百度了下,第一次知道了“爬虫”...于是,在强大的兴趣驱动下,我1个礼拜就入了门....这就是我为什么要学爬虫的经过
我觉得爬虫就是帮助我们偷懒的,如上面,当我爬下来整个老司机论坛后,我可以自定义多条件查找了,不用再那么傻傻的一页一页的翻了;爬虫能帮我们省掉一系列繁琐的时间(比如我要下载我爱看图这个网站的图片,我不可能一张一张的点,我可以写一个爬虫帮我全部下载完)
3.爬虫的本质是什么
爬虫的本质我觉得就是一句话 模仿浏览器去打开网页
我们来看一个例子吧(让红包飞)
打开这个网页后,按F12,打开开发者工具,然后F5刷新下页面(我用的Google浏览器)
先点击“最上面的Network”然后点击“Doc”,应该会看到如下图一样的界面
我们先看General 下面的
request url ,表示我们打开这个网页的地址,也就是我们上面的地址
request method ,表示我们请求的方式,这里我们看到用的是GET
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
应用举例:
GET方法:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)POST方法要求被请求服务器接受附在请求后面的数据,常用于提交表单。
eg:POST /reg.jsp HTTP/ (CRLF)
Accept:image/gif,image/x-xbit,... (CRLF)
...
HOST:桂林电子科技大学 (CRLF)
Content-Length:22 (CRLF)
Connection:Keep-Alive (CRLF)
Cache-Control:no-cache (CRLF)
(CRLF) //该CRLF表示消息报头已经结束,在此之前为消息报头
user=jeffrey&pwd=1234 //此行以下为提交的数据HEAD方法与GET方法几乎是一样的,对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源内容,就可以得到Request-URI所标识的资源的信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新。
status code 表示服务器返回的状态吗,这里是200,表示OK
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常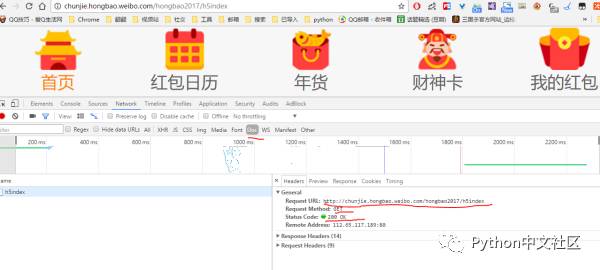
然后再看Request Headers(请求时候用的消息报头)Accept
Accept请求报头域用于指定客户端接受哪些类型的信息。eg:Accept:image/gif,表明客户端希望接受GIF图象格式的资源;Accept:text/html,表明客户端希望接受html文本。Accept-Encoding
Accept-Encoding请求报头域类似于Accept,但是它是用于指定可接受的内容编码。eg:Accept-Encoding:gzip.deflate.如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
Accept-Language
Accept-Language请求报头域类似于Accept,但是它是用于指定一种自然语言。eg:Accept-Language:zh-cn.如果请求消息中没有设置这个报头域,服务器假定客户端对各种语言都可以接受
Cache-Control 是用来控制网页的缓存,详细可以Cache-control_百度百科
Cookie,有时也用其复数形式 Cookies,指某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密)。定义于 RFC2109 和 2965 中的都已废弃,最新取代的规范是 RFC6265[1] 。(可以叫做浏览器缓存)
HOST 表示你请求网址的请求域
User-Agent 表示当前浏览器的名称及版本
Referer: 告诉服务器你是从哪个页面链接过来的(下图没有.) 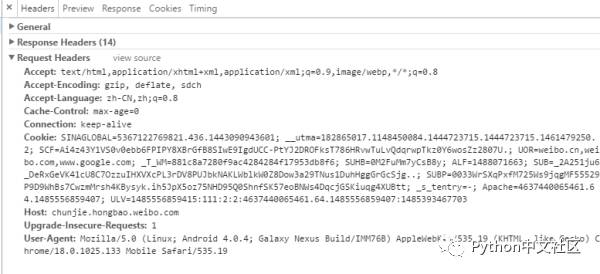
Response Headers我就不一一介绍了,大家可以看HTTP协议详解(真的很经典) - Hundre - 博客园.
爬虫就是把上面的内容模拟发送出去(请大家期待下一篇文章.)
优秀人才不缺工作机会,只缺适合自己的好机会。但是他们往往没有精力从海量机会中找到最适合的那个。
100offer 会对平台上的人才和企业进行严格筛选,让「最好的人才」和「最好的公司」相遇。
扫描下方二维码,注册 100offer,谈谈你对下一份工作的期待。一周内,收到 5-10 个满足你要求的好机会!



文章评论