自然语言处理(Natural Language Processing)
自然语言处理(NLP)是机器学习重要分支之一,主要应用于篇章理解、文本摘要、情感分析、知识图谱、文本翻译等领域。而NLP应用首先是对文本进行分词,当前中文分词器有Ansj、paoding、盘古分词等多种,而最基础的分词器应该属于jieba分词器(比较见下图)。
下面将分别应用R和python对jieba分词器在中文分词、词性标注和关键词提取领域的应用进行比较。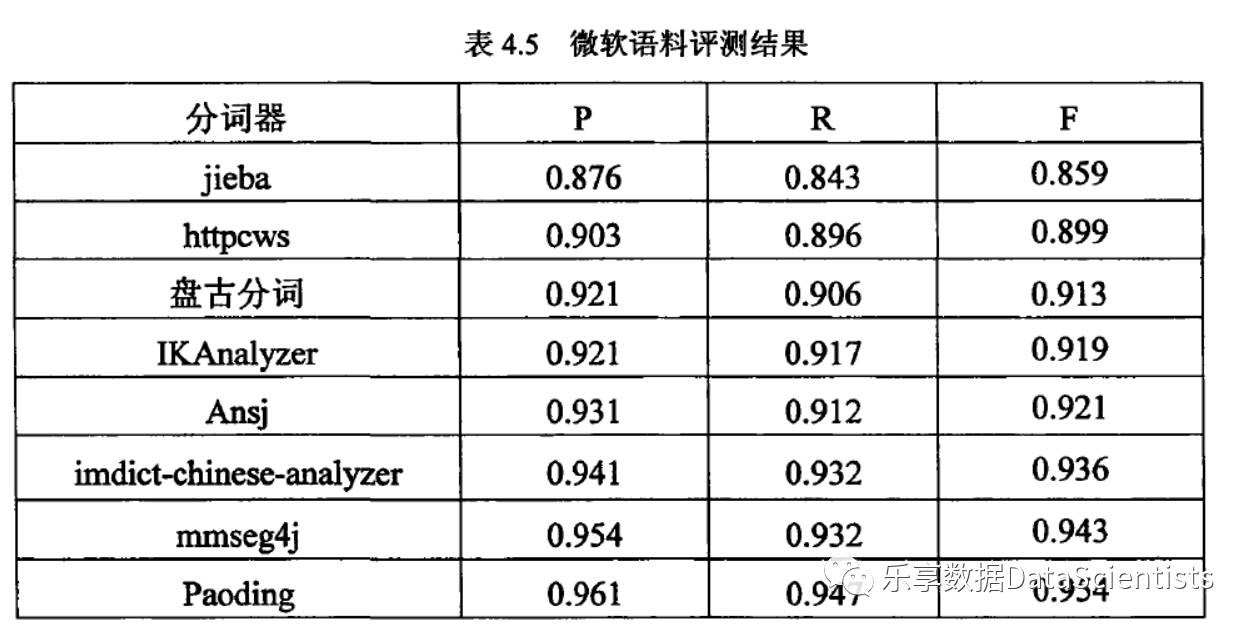
一、jiaba中文分词
R实现
通过函数worker()来初始化分词引擎,使用segment()进行分词。有四种分词模式:最大概率法(MP)、隐马尔科夫模型(HMM)、混合模型(Mix)及索引模型(query),默认为混合模型。具体可查看help(worker).#install.packages('jiebaR')
library(jiebaR)
mixseg <- worker()
segment( "这是一段测试文本" , mixseg )
#或者用以下操作
mixseg['这是一段测试文本']
mixseg <= "这是一段测试文本"python实现
python中需安装jieba库,运用jieba.cut实现分词。cut_all参数为分词类型,默认为精确模式。import jieba
seg_list = jieba.cut(u"这是一段测试文本",cut_all = False)
print("Full mode: "+ ",".join(seg_list)) #默认精确模式 无论是R还是python都为utf—8编码。二、词性标注
R实现
可以使用<=.tagger 或者tag 来进行分词和词性标注,词性标注使用混合模型模型分词,标注采用和 ictclas 兼容的标记法。words = "我爱北京天安门"
tagger = worker("tag") #开启词性标注启发器
tagger <= words
# r v ns ns
# "我" "爱" "北京" "天安门" python实现
#词性标注
import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门")
for word,flag in words:
print('%s, %s' %(word,flag))
<!-- 我, r -->
<!-- 爱, v -->
<!-- 北京, ns -->
<!-- 天安门, ns -->三、关键词提取
R实现
R关键词提取使用逆向文件频率(IDF)文本语料库,通过worker参数“keywords”开启关键词提取启发器,topn参数为关键词的个数。keys = worker("keywords",topn = 5, idf = IDFPATH)
keys <= "会议邀请到美国密歇根大学(University of Michigan, Ann Arbor)环境健康科学系副教授奚传武博士作题为“Multibarrier approach for safe drinking waterin the US : Why it failed in Flint”的学术讲座,介绍美国密歇根Flint市饮用水污染事故的发生发展和处置等方面内容。讲座后各相关单位同志与奚传武教授就生活饮用水在线监测系统、美国水污染事件的处置方式、生活饮用水老旧管网改造、如何有效减少消毒副产物以及美国涉水产品和二次供水单位的监管模式等问题进行了探讨和交流。本次交流会是我市生活饮用水卫生管理工作洽商机制运行以来的又一次新尝试,也为我市卫生计生综合监督部门探索生活饮用水卫生安全管理模式及突发水污染事件的应对措施开拓了眼界和思路。"
#结果:# 48.8677 23.4784 22.1402 20.326 18.5354 # "饮用水" "Flint" "卫生" "水污染" "生活" python实现
python实现关键词提取可运用TF-IDF方法和TextRank方法。allowPOS参数为限定范围词性类型。#关键词提取
import jieba.analyse
content = u'会议邀请到美国密歇根大学(University of Michigan, Ann Arbor)环境健康科学系副教授奚传武博士作题为“Multibarrier approach for safe drinking waterin the US : Why it failed in Flint”的学术讲座,介绍美国密歇根Flint市饮用水污染事故的发生发展和处置等方面内容。讲座后各相关单位同志与奚传武教授就生活饮用水在线监测系统、美国水污染事件的处置方式、生活饮用水老旧管网改造、如何有效减少消毒副产物以及美国涉水产品和二次供水单位的监管模式等问题进行了探讨和交流。本次交流会是我市生活饮用水卫生管理工作洽商机制运行以来的又一次新尝试,也为我市卫生计生综合监督部门探索生活饮用水卫生安全管理模式及突发水污染事件的应对措施开拓了眼界和思路。'
#基于TF-IDF
keywords = jieba.analyse.extract_tags(content,topK = 5,withWeight = True,allowPOS = ('n','nr','ns'))
for item in keywords:
print item[0],item[1]
#基于TF-IDF结果
# 饮用水 0.448327672795
# Flint 0.219353532163
# 卫生 0.203120821773
# 水污染 0.186477211628
# 生活 0.170049997544#基于TextRank
keywords = jieba.analyse.textrank(content,topK = 5,withWeight = True,allowPOS = ('n','nr','ns'))
for item in keywords:
print item[0],item[1] #基于TextRank结果:
# 饮用水 1.0
# 美国 0.570564785973
# 奚传武 0.510738424509
# 单位 0.472841889334
# 讲座 0.443770732053写在文后
自然语言处理(NLP)在数据分析领域有其特殊的应用,在R中除了jiebaR包,中文分词Rwordseg包也非常常用。一般的文本挖掘步骤包括:文本获取(主要用网络爬取)——文本处理(分词、词性标注、删除停用词等)——文本分析(主题模型、情感分析)——分析可视化(词云、知识图谱等)。本文是自然语言处理的第一篇,后续将分别总结下应用深度学习Word2vec进行词嵌入以及主题模型、情感分析的常用NLP方法。参考资料
Introduction · jiebaR 中文分词https://qinwenfeng.com/jiebaR/segment.html
知乎:【文本分析】利用jiebaR进行中文分词https://zhuanlan.zhihu.com/p/24882048
雪晴数据网:全栈数据工程师养成攻略http://www.xueqing.tv/course/73
搜狗实验室,词性标注应用http://www.sogou.com/labs/webservice/
【R文本挖掘】中文分词Rwordseghttp://blog.163.com/zzz216@yeah/blog/static/162554684201412895732586/
要想获取分析代码,可查看原文,进入本人的GitHubhttps://github.com/Alven8816查看下载,或通过本人邮箱[email protected]与本人联系
”乐享数据“个人公众号,不代表任何团体利益,亦无任何商业目的。任何形式的转载、演绎必须经过公众号联系原作者获得授权,保留一切权力。欢迎关注“乐享数据”。


文章评论