在过去的几年中,Uber无人车,Google阿尔法狗,量化交易,LinkedIn精准的好友推送又或是我们建筑孩子们熟悉的Grasshopper中的Galapagos。机器学习(Machine Leraning)正在切实地改变着我们的生活、学习与工作。

什么是机器学习?

机器学习是一种可以自动生成分析模型的数据分析方法,通过使用一定的算法多次迭代从现有的数据中进行学习,使计算机能够在没有被明确编程的情况下,从数据(Data)中提炼出信息。(SAS)
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。(Langley,1996)
机器学习是对能通过经验自动改进的计算机算法的研究(Tom Mitchell,1997)
机器学习的学科背景
概率论、统计学、逼近论、凸分析、计算复杂性理论、生物学、神经生理学、自动控制、计算机科学等
机器学习的应用领域
个人信息识别(广告推送、信用评级等)
计算机视觉(手写识别、图像搜索等)
自然语言处理(垃圾邮件分类、语音识别、自动翻译等)
生物特征识别
搜索引擎
设备故障预测
网络入侵检测
医学诊断
检测信用卡欺诈
证券市场分析
DNA序列测序
战略游戏
机器人
.......

尽管机器学习算法已经被提出了很长时间(1950s),但直到近年来,对大数据使用复杂计算进行处理的机器学习方法才进入快速发展期(越来越快)。其原因是互联网的快速发展与自媒体时代的到来,可以被学习的数据以指数级的速度增加,而计算机的运算能力也根据摩尔定律高速发展。所以一夜之间:
Google自动驾驶汽车
Amazon Netflix在线推荐
微软Cotana (Win 10)苹果 siri
……
红遍大江南北
因为它是人工智能的核心,是使计算机具有智能的根本途径。

机器学习中常用的学习方法
被最广泛使用的两大机器学习方法是监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)。大多数的机器学习(大概70%)是监督学习,无监督学习大概占10%-20%。有时也会使用半监督(Semi-supervised)和强化学习(Reinforcement Learning)这两个学习方法。
监督学习 算法利用带有分类标签(Label)的实例训练机器学习模型,例如一系列有关肿瘤良性或恶性(分类标签)的病人信息(年龄、性别、人种、体重……)的数据。通过将数据标记为“B”(Benign,良性)或“M”(Malignant,恶性)。学习算法收到了一系列有着对应正确输出值的输入数据,算法通过对比模型实际输出和正确输出的多次模型修正迭代进行学习,。对模型进行修改以减小误差。通过分类,回归,预测和梯度上升的方法,监督学习方法使用模型来预测其他的未被标记数据的标签值(例如,新增一个病例,肿瘤是否为恶性)。监督学习方法被普遍应用于使用历史数据预测未来可能发生的事件。例如预测什么时候信用卡交易可能是欺诈性的,或哪个保险客户可能提出索赔。
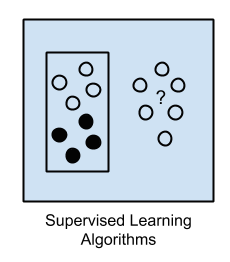
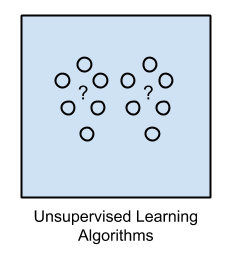
无监督学习 使用不带分类数据。系统不会被告知“正确答案”。算法必须自己搞明白这些数据呈现了什么。其目标是探索数据并找到一些内部结构。无监督学习对交易(事务性)数据的处理效果很好。例如,它可以识别有相同特征的顾客群(用于市场营销),或者它可以找到将客户群彼此区分开的特征。流行的方法包括自组织映射(Self-organizing maps),最近邻映射(Nearest-neighbor mapping),k-均值聚类(K-means clustering)和奇异值分解(Singular value decomposition)。这些算法也用于对文本进行分段处理,推荐项目和确定数据的异常值。
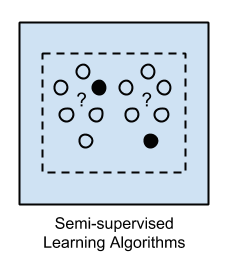
半监督学习 应用与监督学习相同。但它同时使用了有标签和无标签数据进行训练——通常情况下,学习的数据为少量的有标签数据与大量的未标记的数据(因为未标记的数据非常容易获得)。这种类型可以使用分类,回归和预测等学习方法。当一个全标记的监督学习过程,因其相关标签的成本太高时,可以使用半监督学习,例如使用网络摄像头识别人脸。
强化学习 经常被用于机器人,游戏和导航。算法通过不断地试错进行强化学习,使回报最大化。这种学习分三个主要组成部分:代理(学习者或决策者),环境(代理所接触到地一切)和行动(什么是代理可以做的)。其目标是在给定的时间内,使代理选择的行动回报最大化。通过一个好的策略,代理将更快地达到目标。因此,强化学习的目标是得到最好的策略。
机器学习的算法与工具
算法
建筑学的大部分同学应该是理科出身,所以可以先回忆一下高中的统计学知识:
偏差:描述的是预测值(估计值)的期望E与真实值T之间的差距。偏差越大,越偏离真实数据。
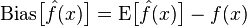
方差:描述的是预测值P的变化范围,离散程度,也就是离其期望值E的距离。方差越大,数据的分布越分散。
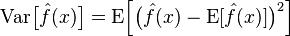
模型的真实误差是两者之和,如下图:
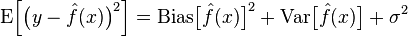
机器学习的目的无非是通过一定的处理,将数据投入一个模型中,使我们的模型函数f^(x)与真实函数f(x)的真实误差最小。这时我们可以引入梯度下降方法。
梯度下降方法
从最简单的两个变量开始(房价与面积之间的函数建模)。
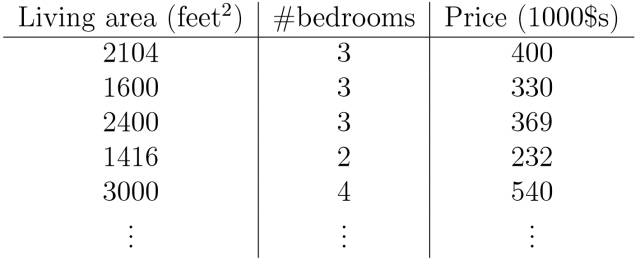
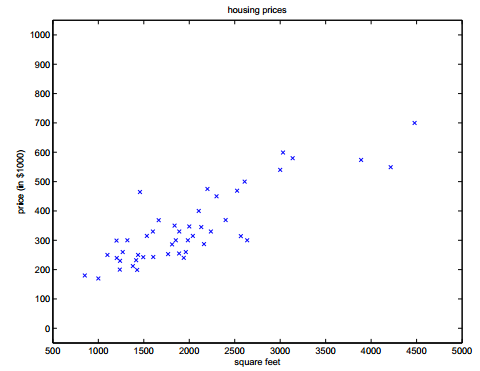
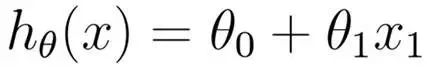
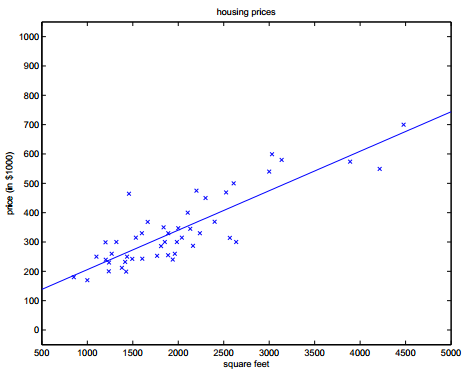
通过建立误差函数(即方差公式,其中1/2使是为了计算方便):
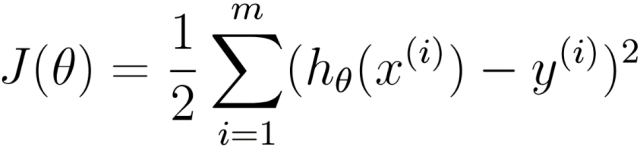
从而对误差函数J(θ)有梯度下降算法:
o (1) 初始化θ(随机初始化)
o (2)迭代,新的θ能够使得J(θ)更小
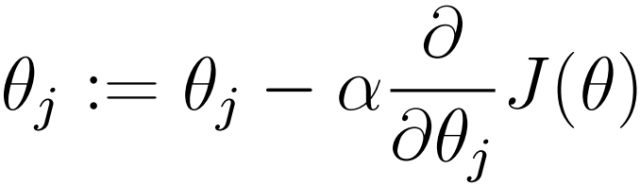
o (3)如果J(θ)能够继续减少,返回(2)
其中
α称为学习率
梯度方向为
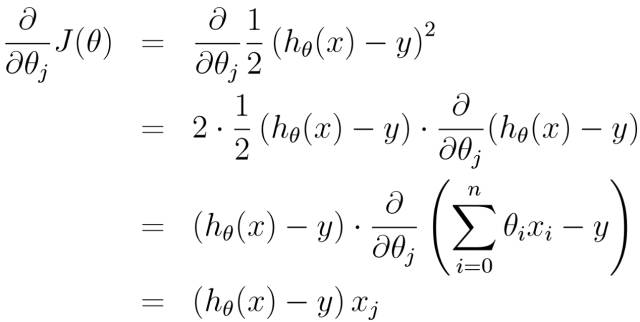
于是有:
将其扩展至多维的情形:
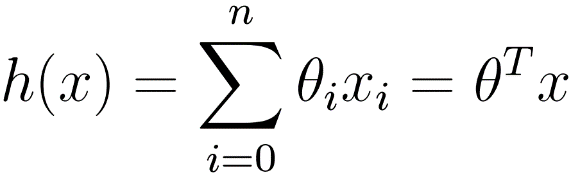
说简单了,就是和kangaroo里地形中水滴汇聚的原理一样。
当然类似功能的常用的还有
牛顿方法
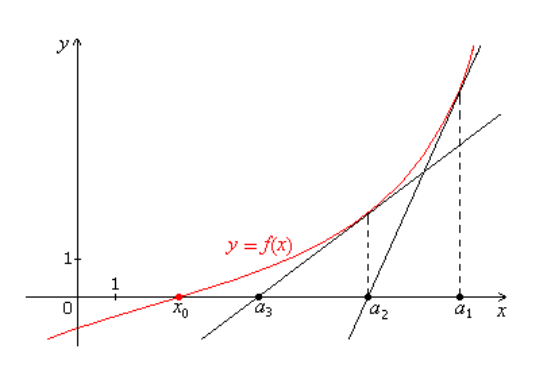
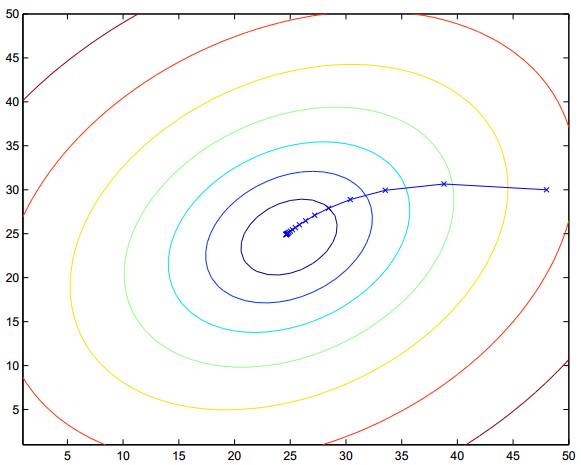
通过重复求某一点切线与坐标轴的交点(多维情况下是超平面),可以得到模型函数,和梯度下降相比,牛顿方法的收敛速度更快,通常只要十几次或者更少就可以收敛,牛顿方法也被称为二次收敛(quadratic convergence),因为当迭代到距离收敛值比较近的时候,每次迭代都能使误差变为原来的平方。缺点是当参数向量较大的时候,每次迭代都需要计算一次 Hessian 矩阵的逆,比较耗时。
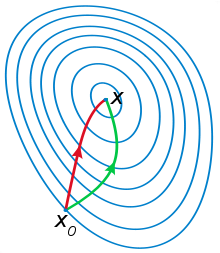
红色曲线是利用牛顿法迭代求解,绿色曲线是利用梯度下降法求解。
有了上面的算法我们大致可以解决对于多变量的模型的拟合问题,而在生活中,还有一大类问题是分类问题,例如前文提到的,对肿瘤良性与恶性的辨别问题。
通过建立函数,我们可以将分类问题用一种简单的方式转化为函数问题。
在二维的例子中,我们将每一个输入数据都可以表示为一个向量 x =(x_1, x_2) ,而我们的函数则是要实现“如果线以下,输出0;线以上,输出1”。
用数学方法表示,定义一个表示权重的向量 w 和一个垂直偏移量 b。然后,我们将输入、权重和偏移结合可以得到如下传递函数:
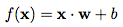
这个传递函数的结果将被输入到一个激活函数中以产生标记。在上面的例子中,我们的激活函数是一个门限截止函数(即大于某个阈值后输出1):
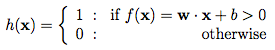
上面的这种分类方式,在方法上是通过建立一种指数分布族来将数据点进行分类。
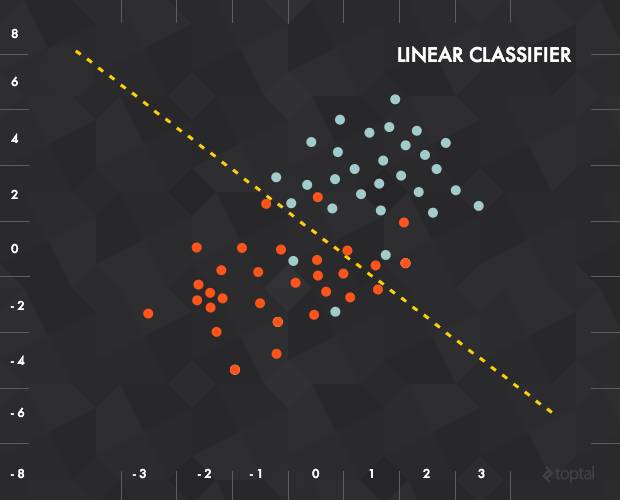
通过引入指数分布族,我们可以将这种分类问题转化为梯度下降与牛顿法可以处理的函数问题。即广义线性模型(GLM)通过假设一个概率分布,得到不同的模型,而梯度下降和牛顿方法都是为了求取模型中的线性部分(θTx)的参数θ的。
指数分布族形式
伯努利分布(Bernoulli):对 0、1 问题进行建模;
多项式分布(Multinomial):多有 K 个离散结果的事件建模;
泊松分布(Poisson):对计数过程进行建模,比如网站访问量的计数问题,放射性衰变的数目,商店顾客数量等问题;
伽马分布(gamma)与指数分布(exponential):对有间隔的正数进行建模,比如公交车的到站时间问题;
β 分布:对小数建模;
Dirichlet 分布:对概率分布进建模;
Wishart 分布:协方差矩阵的分布;
高斯分布(Gaussian);
通过上述模型的建立,我们就得到了机器学习的两种最基础的方式。
将这两种基础方式优化、更高级的实现或组合构成了更多的学习算法:
神经网络(Neural networks)
决策树(Decision trees)
随机森林(Random forests)
联系和序列发现(Associations and sequence discovery)
梯度上升(Gradient boosting and bagging)
支持向量机(Support vector machines)
最近邻映射(Nearest-neighbor mapping)
k-聚类(k-means
clustering)
自组织映射(Self-organizing maps)
局部搜索优化——遗传算法(Local search optimization
techniques .e.g., genetic algorithms.)
期望最大化(Expectation maximization)
多元自适应回归样条(Multivariate adaptive regression
splines)
贝叶斯网络(Bayesian networks )
核密度估计(Kernel density estimation)
主元素分析(Principal component analysis)
奇异值分离(Singular value decomposition)
高斯混合模型(Gaussian mixture models )
……
用一张图来说明一下,还是一头雾水?没关系,有很多工具可以帮助我们实现上述的算法。
工具
1、SAS
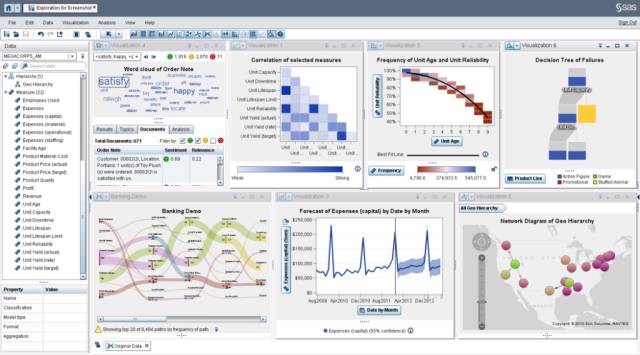
SAS 功能丰富而强大(包括绘图能力),且支持编程扩展其分析能力,适合复杂与高要求的统计性分析。
2、Matlab
Matlab 也能提供大量数据挖掘的算法,更关注科学与工程计算领域。
3、SPSS Modeler
SPSS Modeler 的统计功能相对有限, 主要是提供面向商业挖掘的机器学习算法(决策树、神经元网络、分类、聚类和预测等)的实现。同时,其数据预处理和结果辅助分析方面也相当方便,这一点尤其适合商业环境下的快速挖掘。不过就处理能力而言,实际感觉难以应对亿级以上的数据规模。
4、TableAU
TableAU 的优势主要在于支持多种大数据源/格式,众多的可视化图表类型,加上拖拽式的使用方式,上手快,非常适合研究员使用,能够涵盖大部分分析研究的场景。不过要注意,其并不能提供经典统计和机器学习算法支持,因此其可以替代Excel, 但不能代替统计和数据挖掘软件。另外,就实际处理速度而言,感觉面对较大数据(实例超过3000万记录)时,并没有官方介绍的那么迅速。
5、Weka
一个基于java开发的数据挖掘工具,它为用户提供了一系列据挖掘API、命令行和图形化用户接口。你可以准备数据、可视化、建立分类、进行回归分析、建立聚类模型,同时可以通过第三方插件执行其他算法。除了WEKA之外,Mahout是Hadoop中为机器学习提供的一个很好的JAVA框架,你可以自行学习。如果你是机器学习和大数据学习的新手,那么坚持学习WEKA,并且全心全意地学习一个库。
6、NanoCubes
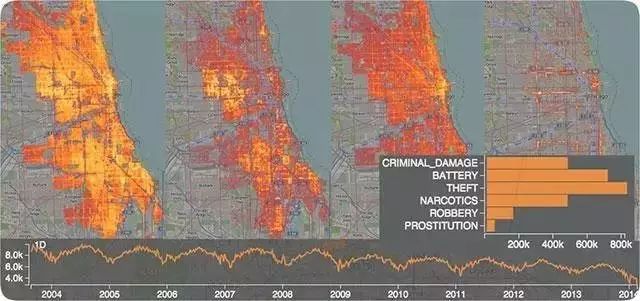
如果要分析千万级以上的时空数据,比如新浪微博上亿用户发文的时间与地理分布(从省到街道多级粒度的探索)时,推荐使用NanoCubes(http://www.nanocubes.net/)。该开源软件可在日常的办公电脑上提供对亿级时空数据的快速展示和多级实时钻取探索分析。上图是对芝加哥犯罪时间地点的分析,网站有更多的实时分析的演示例子。
7、高阶编程使用

◆ R语言——最适合统计研究背景的人员学习,具有丰富的统计分析功能库以及可视化绘图函数可以直接调用。通过Hadoop-R更可支持处理百亿级别的数据。相比SAS,其计算能力更强,可解决更复杂更大数据规模的问题。
◆ Python语言——最大的优势是在文本处理以及大数据量处理场景,且易于开发。在相关分析领域,Python代替R的势头越来越明显。
◆ Java语言——通用性编程语言,能力最全面,拥有最多的开源大数据处理资源(统计、机器学习、NLP等等)直接使用。也得到所有分布式计算框架(Hadoop/Spark)的支持。
结语
从时间角度看, 机器学习是用过去预测未来。
从信息流处理的角度看,机器学习是按照某种规则对信息进行压缩和抽提。
从神经元参数角度看,机器学习的过程是建立神经元之间的联系,学习样本里反复出现的pattern会建立权重大的关联,出现少的pattern会有权重小的关联。
从学术的角度来说,机器学习是空间搜索和函数的泛化。
从应用的角度:机器学习可以大约的解释成数据挖掘+人工智能。
从哲学的角度来说,机器学习是“重现人认识世界的过程。
而机器学习对于普通人,对于建筑师来说,是一种未来必备的工具。一如90年代我们看待AutoCAD,现在我们看待BIM一样,终有一天,我们对复杂建筑因素的处理,工作中部分繁杂的设计过程会被以机器学习为背景的自优化算法与人工智能取代,在那时,作为建筑师的我们应该是这些工具的主人,而非淘汰品。人工智能的浪潮已近,这一天应该不会太远,而你准备好了么?
扩展阅读:
回归方法
http://www.csdn.net/article/2015-08-19/2825492
Andrew Ng,CS229,斯坦福大学机器学习视频,
http://open.163.com/special/opencourse/machinelearning.html
CS229学习笔记
http://www.cnblogs.com/xuesong/p/4094968.html
学习资源列表
http://conductrics.com/data-science-resources/
从零实现来理解机器学习算法:书籍推荐及障碍的克服
http://www.csdn.net/article/2015-09-08/2825646
编译自:
http://cs229.stanford.edu/
http://www.sas.com/en_id/insights/analytics/machine-learning.html
http://blog.chinaunix.net/uid-25267728-id-4678802.html
http://www.cnblogs.com/xiaowanyer/p/3701944.html
https://www.zhihu.com/question/19830921
http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/
http://mp.weixin.qq.com/s?__biz=MzA4MzQxMTAwNA==&mid=2650108926&idx=3&sn=9a274344c5fa7d78cb69c467707af178&scene=2&srcid=0913CnGmnfggd2s97NVeGNLA&from=timeline&isappinstalled=0#wechat_redirect
胡雨辰 同济大学建筑与城市规划学院硕士在读
来源:FabUnion
近期热门文章Top10
↓ 点击标题即可查看 ↓
3. 终于有人讲透了芯片是什么
5. 科研经费大解放!!!
点击公众号内菜单栏“Top10”可查看过往每月热门文章Top10


文章评论