Python:中文文本处理
作者:罗晨 来源:转载自公众号“沈浩老师”

作为新闻传播学科的学生,我们为什么要学习编程?如果说我们的专业强调实践导向,希望大家在新闻业中发光发热,那么现在调查报道、数据新闻已成为行业内备受关注的新闻形式,我们都希望通过切实可靠的信息来追求一种客观性与真实性,如果不会一些编程技巧,那么所能做的就很有限,即使生产的新闻作品中有一两篇质量优秀的,依然会比国外媒体差很大一截,诸如关于政府政策、公共健康的新闻报道中,往往需要分析空间型数据(spatial data)与时序性数据(temporal data),而这些数据由于体量庞大,往往保存在各种形式的数据库中,如果连基本的数据抽取、数据清洗都不会,那就非常值得堪忧。
放在稍显功利主义的层面来说,如果具备一些基本的编程能力,那么一定会更加适应如今的人才招聘需要,基于编程的可视化、数据分析一定是你求职时的加分项。那么有一部分同学就会反问:我今后意图从事学术研究,面对大型数据的几率很小,我并不一定要掌握这些程序知识。但是传播学的发展热点之一是突破传统研究方法的一些局限,致力于从更广阔的关系型数据中提炼出卓有价值的学术见解;其次我们在分析文本时经常涉及到文本获取,诸如网络爬虫(Web Crawler)、数据库检索(诸如:Google BigQuery、Postgre SQL等)、文本处理,诸如分词(Segmentation)、词性标注与提取(POS Label and Extraction)、主题模型建构(Topic Model)等,这些目的往往难以依靠传统的工具来实现,必须仰赖新的模式。
那么分词的规则究竟有哪些呢?或者说在进行中文文本处理时是怎样分词的?
首先是基于词典的分词,有一种比较流行的说法:分词效果好不好,就看词典优不优。显然这需要一个尽可能全面且完善的词典(lexicon),我们的切分完全按照词典来进行,原理就是拿切分的每个词和词典中的词进行匹配,如果匹配成功,就分出了一个词。具体而言,其中主要包含正向最大匹配、逆向最大匹配。首先需要设定一个长度(length),以正向最大匹配(FMM)为例,先按照长度取出左起(正常阅读习惯)的字,然后与词典进行匹配,如果词典中没有这个词,那么缩短取字个数,以此类推,最后对剩余的字进行同样的操作,直到整个句子都被切分完毕。逆向最大匹配(IMM)反之,后来诞生的双向匹配则结合了两者的特点,但是程序也更加复杂了。话不多说,上一段我自己写的FMM代码(毕竟文科出身,写出的代码可能不是最简约的)。
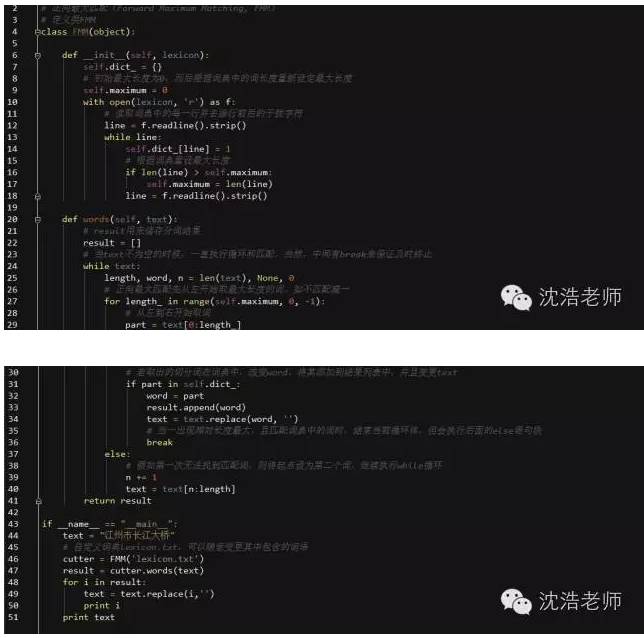

IMM的出现很大程度上是归因于中文里习惯主语后置,所以IMM的原理是从后往前按照最大长度取词,如果不匹配词典,那么最大长度自减一,依次类推。其代码和FMM最大不一致之处是在class中的第二个函数。
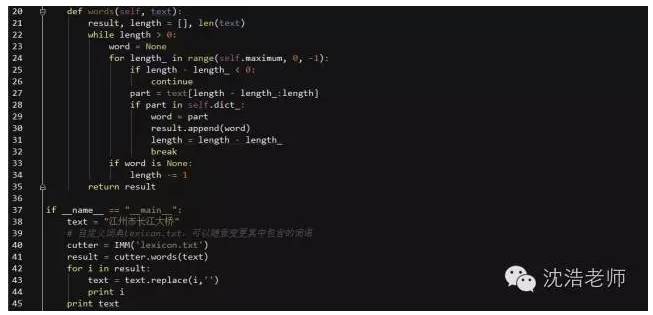
可以明显看出:IMM分词器的原理较FMM而言更好理解,且写法更加简便一些。IMM返回的结果是:长江大桥、江州市。
在本次实践中,IMM的分词结果比FMM更加准确。当然,词典不同,分词结果一定是不一样的,一次比较也不能说明什么,难以给出一个结论。但是有许多NLPers认为:IMM向来比FMM更加准确些,可能中文的文法如是吧!
当然,基于词典的分词有其弊端,有时候句子的原意要素不会出现在词典中,往往在这个时候我们青睐于用数学知识来减少这种不确定性,因此诞生了基于概率的分词,常见的是马尔科夫链(Markov Chain)与隐马尔科夫模型(Hidden Markov Model,HMM),如果能够结合词典语料与统计学模型,那么就可以用较快的速度来切分无悬念、无歧义的既有词,并且根据模型对陌生词汇(字典中未收纳的词汇)进行二次处理,有助于提升分词的精度与召回率。
马尔科夫链表达的是一种状态切换之间的随机过程,其最大特征是“无记忆性”,即下一状态的概率分布仅有当前状态决定,其中暗含着时间序列,我认为这大概是所谓的:discrete time series,这种状态到状态之间的切换完全随机,就如随机漫步(Random Walk)一样。
在马尔科夫模型中,从状态n变换到状态n+1的概率为:
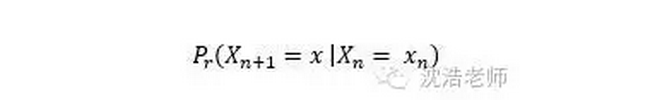 对于静态的马尔科夫链,借用以上公式,可以得出:
对于静态的马尔科夫链,借用以上公式,可以得出:
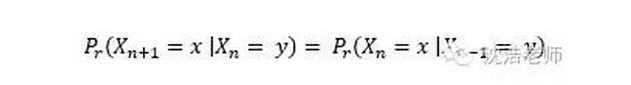 当要分析的中文语句很长很长,就可以发现马尔科夫相对全概率的优势,全概率要计算平方级别次,时间复杂度会很大,而马尔科夫可以限定阶数,即限制其记忆范围。对应以上语句,如果希望分解出的分词状态为:江州市|长江大桥,那么借用二阶马尔科夫链可以如下运算:
当要分析的中文语句很长很长,就可以发现马尔科夫相对全概率的优势,全概率要计算平方级别次,时间复杂度会很大,而马尔科夫可以限定阶数,即限制其记忆范围。对应以上语句,如果希望分解出的分词状态为:江州市|长江大桥,那么借用二阶马尔科夫链可以如下运算: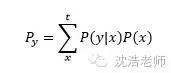
在分词中涉及隐马尔科夫,又要牵扯到Viterbi算法、Baum-Welch算法等,这些算法大致掌握就好,没有必要详细推演,不过在未来的推送中,如有机会我会继续用Python来实现。
幸好,Python的第三方模块jieba融合了HMM分词和词典分词,且支持用户自定义词典载入,效果很不错,课堂上也系统学习了jieba分词及其高级运用,在上面代码中用到的“江州市长江大桥”也是jieba中的标志性案例,jieba可以说是现在进行中文分词的一项利器!
未来推送中会继续总结分词学习的内容,无论进行多么复杂的分词,都是在Python基础应用之上的积累,所以对基础知识的良好掌握还是很重要的。

文章评论